XiaoMi-AI文件搜索系统
World File Search SystemSVL

什么是特殊受害者联络 (SVL)?
SVL 是 OSTC 28 个实地办事处内指派的文职人员,负责与受害者建立和维持开放且一致的沟通渠道。SVL 拥有专业知识,可帮助受害者应对军事司法程序并维护当地资源网络,以确保满足受害者的需求。

在寻找纳什平衡的加密硬度
(回想一下PG的运作方式,以及上次Dan演讲的减少)。点是(s',p',e x s)给出了SVL(PPAD -COMPLETE)的实例,并且(S',C,E X S)给出了SVL(PLS -COMPLETE)上DAG的实例。

Delma Vescolineata Hunter Valley Delma的保护建议)
该物种的四个标本已用于描述Mahony等人的形态特征。(2022),还有另外13个活人的照片用于评估颜色和模式变化。猎人山谷delma头的顶部是深灰色至浅棕色和均匀的,或带有较深的条纹或斑点。在与嘴巴,耳朵和侧面接壤的鳞片上有零散的黑条,斑点或污迹。在耳朵后面和侧面,颜色可能是略带生锈的颜色。身体的其余部分是浅棕色的,通常沿着身体的顶部有一些深色斑点。大多数人沿着身体的耳朵后面奔跑。有些人可能有两条这样的行。底面是白色的(Mahony等人2022)。该物种的总长度约为250毫米,最大鼻孔长度(SVL)为101毫米(Mahony等人。2022)。
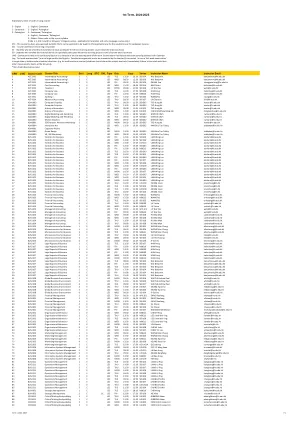
第一学期,2024-2025
E - 英文 1 - 英文/粤语 C - 粤语 2 - 英文/普通话 P - 普通话 3 - 粤语/普通话 4 - 英文/粤语/普通话 5 - 其他:请参考课程大纲(代码 1、2、3 及 4 代表双语/三语课程 - 只适用于翻译及部分语言课程) STC - 本课程已获 AQAC 预先批准,基于教学原因,可于本学年转为以中文/粤语授课。 SVL - 含有服务研习部分的课程 SC - 选修此讲座/导修班的学生必须参与服务研习项目,计入/扣除总课时 SO - 选修此讲座/导修班的学生可选择性参与服务研习项目,计入/扣除总课时 LWE - 在最后一堂讲座/导修班或学期最后一周的某个时段举行的考试。教务处不组织在日历上公布的考试时间之外举行的考试(例如“上周考试”)。有关教师将公布详细安排。如果“上周考试”超过预定的上课时间或在预定的上课时间之外举行(例如多部门课程),学生应立即通知科目教师,如果与大学的其他课程和/或考试有时间冲突。 * 非学分课程