XiaoMi-AI文件搜索系统
World File Search SystemScipad

scipad:将空间线索纳入无监督的姿势深入关节学习
摘要 - 不监督的单眼深度估计框架 - 作品显示出有希望的自主驱动性能。但是,现有的解决方案主要依靠一个简单的召集神经网络来进行自我恢复,该网络努力在动态,复杂的现实世界情景下估算精确的相机姿势。这些不准确的相机姿势不可避免地会恶化光度重建,并误导了错误的监督信号的深度估计网络。在本文中,我们介绍了Scipad,这是一种新颖的方法,它结合了无监督的深度置式联合学习的空间线索。具体来说,提出了一种置信度特征流估计器来获取2D特征位置翻译及其相关的置信度。同时,我们引入了一个位置线索聚合器,该位置线索聚合器集成了pseudo 3D点云中的depthnet和2D特征流入均匀的位置表示。最后,提出了一个分层位置嵌入喷油器,以选择性地将空间线索注入到鲁棒摄像机姿势解码的语义特征中。广泛的实验和分析证明了与其他最新方法相比,我们的模型的出色性能。非常明显的是,Scipad的平均翻译误差降低了22.2%,而Kitti Odometry数据集的相机姿势估计任务的平均角误差为34.8%。我们的源代码可在mias.group/scipad上找到。
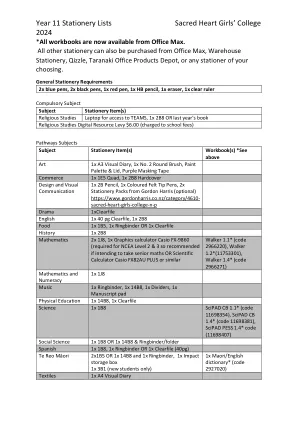
11年级文具列出了圣心女大学学院2024
体育教育1x 14b8,1x Clearfile Science 1X 1B8 Scipad CB 1.1*(代码11698354),Scipad CB 1.4*(代码11698381),Scipad Pess 1.4*代码*代码(11698407 (40pg)Te ReoMāori2x1b5或1x 14b8和1x Ringbinder,1倍冲击储物盒1x 3B1(仅新学生)