XiaoMi-AI文件搜索系统
World File Search SystemViT

宣传册-NRI-外国-PG-研究-录取-2024-25。......
综合技术硕士。软件工程 对于 VIT-Vellore 和 VIT-Chennai 校区:通过州/中央中等教育委员会组织的高中考试或同等考试,物理、化学和数学(PCM)总分达到 70%。 对于 VIT - AP 和 VIT Bhopal 校区:通过州/中央中等教育委员会组织的高中考试或同等考试,物理、化学和数学(PCM)总分达到 65%。 年龄限制:出生日期在 2004 年 7 月 1 日或之后

Quasar-ViT:面向硬件的视觉变换器量化感知架构搜索
视觉转换器 (ViT) 已证明其在计算机视觉任务中比卷积神经网络 (CNN) 具有更高的精度。然而,为了在资源有限的边缘设备上有效部署,ViT 模型通常需要大量计算。这项工作提出了 Quasar-ViT,一种面向硬件的量化感知 ViT 架构搜索框架,以设计用于硬件实现的高效 ViT 模型,同时保持精度。首先,Quasar-ViT 使用我们的逐行灵活混合精度量化方案、混合精度权重纠缠和超网层缩放技术来训练超网。然后,它应用一种高效的面向硬件的搜索算法,结合硬件延迟和资源建模,从不同推理延迟目标下的超网中确定一系列最佳子网。最后,我们提出了一系列 FPGA 平台上的模型自适应设计,以支持架构搜索并缩小理论计算减少和实际推理加速之间的差距。我们搜索到的模型在 AMD/Xilinx ZCU102 FPGA 上分别实现了 101.5、159.6 和 251.6 帧每秒 (FPS) 的推理速度,对于 ImageNet 数据集的 top-1 准确率分别达到 80.4%、78.6% 和 74.9%,始终优于之前的研究。

XSL•FO
背景:基于 Transformer 的模型在医学成像和癌症成像应用中越来越受欢迎。许多最近的研究表明,基于 Transformer 的模型可用于脑癌成像应用,例如诊断和肿瘤分割。目的:本研究旨在回顾不同的视觉变换器 (ViT) 如何有助于利用脑图像数据推进脑癌诊断和肿瘤分割。本研究考察了为增强脑肿瘤分割任务而开发的不同架构。此外,它还探讨了基于 ViT 的模型如何增强卷积神经网络在脑癌成像中的性能。方法:本综述按照 PRISMA-ScR(系统评价和荟萃分析扩展范围界定综述的首选报告项目)指南进行研究搜索和研究选择。搜索包括 4 个流行的科学数据库:PubMed、Scopus、IEEE Xplore 和 Google Scholar。搜索词的制定涵盖了干预措施(即 ViT)和目标应用(即脑癌成像)。研究选择的标题和摘要由 2 名审阅者独立完成,并由第三名审阅者验证。数据提取由 2 名审阅者完成,并由第三名审阅者验证。最后,使用叙述方法合成数据。结果:在检索到的 736 项研究中,有 22 项(3%)被纳入本综述。这些研究发表于 2021 年和 2022 年。这些研究中最常见的任务是使用 ViT 进行肿瘤分割。没有研究报告早期发现脑癌。在不同的 ViT 架构中,基于移位窗口变压器的架构最近成为研究界最受欢迎的选择。在所包含的架构中,UNet transformer 和 TransUNet 具有最多的参数,因此需要多达 8 个图形处理单元的集群进行模型训练。脑肿瘤分割挑战数据集是所包含研究中使用的最流行的数据集。ViT 与卷积神经网络以不同的组合使用,以捕获输入脑成像数据的全局和局部背景。结论:可以说,Transformer 架构的计算复杂性是推动该领域发展和实现临床转化的瓶颈。本综述提供了有关该主题的当前知识状态,本综述的结果将有助于医学人工智能及其在脑癌应用领域的研究人员。

使用傅立叶转化红外光谱
1个生物系统机械工程系,农业与生命科学学院,智纳国立大学,大韩民国大道34134; 201860369@o.cnu.ac.kr(R.J.); akbar.faqeerzada@o.cnu.ac.kr(m.a.f.); btanima1987@gmail.com(T.B.)2 VIT设计学院多媒体系(V-Sign),Vellore Technology Institute(VIT),Vellore 632014,印度; lakshmipriya.gg@vit.ac.in 3美国农业部农业部农业研究局环境微生物和食品安全实验室,美国农业部,Barc-East,Barc-East,Barc-East,Bldg 303,Beltsville,MD 20705,美国; moon.kim@usda.gov(M.S.K. ); unsuck.baek@usda.gov(i.b.) 4农业与生命科学学院智能农业系统系,智纳国立大学,大韩民国大师,34134 *通信:chobk@cnu.ac.kr;电话。 : +82-42-821-67152 VIT设计学院多媒体系(V-Sign),Vellore Technology Institute(VIT),Vellore 632014,印度; lakshmipriya.gg@vit.ac.in 3美国农业部农业部农业研究局环境微生物和食品安全实验室,美国农业部,Barc-East,Barc-East,Barc-East,Bldg 303,Beltsville,MD 20705,美国; moon.kim@usda.gov(M.S.K.); unsuck.baek@usda.gov(i.b.)4农业与生命科学学院智能农业系统系,智纳国立大学,大韩民国大师,34134 *通信:chobk@cnu.ac.kr;电话。 : +82-42-821-67154农业与生命科学学院智能农业系统系,智纳国立大学,大韩民国大师,34134 *通信:chobk@cnu.ac.kr;电话。: +82-42-821-6715

血液与免疫学 - II 模块 3 年级 MBBS
描述氰钴胺素(维生素 B12)的各种口服和肠外制剂 描述氰钴胺素(维生素:B12)的临床用途 描述叶酸的临床用途 描述将氰钴胺素与叶酸和铁结合的药理学原理 描述粒细胞集落刺激因子(非格司亭)和粒细胞单核细胞集落刺激因子在治疗白细胞减少症中的作用。 描述血小板集落刺激因子(奥普瑞白介素)在治疗血小板减少症中的作用。 法医学法医证据

可持续发展目标 9 – 产业、创新和...
VIT 认识到可持续经济发展的重要性,并理解技术进步在实现这一目标方面发挥着至关重要的作用。为了确保长期繁荣,必须应对经济和环境挑战。这包括创造新的就业机会、提高能源效率和实施碳负系统。这些措施不仅有助于国家的整体福祉,而且为可持续的未来铺平了道路。鉴于全球经济的快速变化和贫富差距的扩大,必须推行工业化,为所有人提供平等的机会。这可以通过促进创新和建立强大的基础设施来实现。通过投资研究和创新,各国可以有效地推动稳定增长并创建一个包容性社会。作为印度著名的教育和研究机构,VIT 致力于调整其政策以促进创新和支持研究。VIT 认识到可持续经济发展的重要性,努力创造一个鼓励技术进步和促进研究工作的环境。总之,可持续经济的发展对于一个国家的长期繁荣至关重要。技术进步,例如创造新的就业机会和实施节能系统,对于应对经济和环境挑战至关重要。为了实现稳定增长并缩小贫富差距,必须投资于研究和创新。作为领先的教育和研究机构,VIT 致力于创建一个支持创新和促进研究的基础设施。

视觉变压器带有遮盖自动编码器,用于基于大尺寸视网膜图像的引用糖尿病性视网膜病变分类
基于深度学习算法的计算机辅助诊断系统已显示出糖尿病性视网膜病快速诊断(DR)的潜在应用。由于变压器的出色表现而不是自然图像上的卷积神经网络(CNN),因此我们尝试开发一种新模型,以使用变压器使用有限数量的大型视网膜图像来对引用的DR进行分类。在本研究中应用了带有蒙版自动编码器(MAE)的视觉变压器(VIT),以提高参考DR的分类性能。我们收集了超过224×224的100,000张公共底面的视网膜图像,然后使用MAE在这些视网膜图像上进行了预训练的VIT。将预训练的VIT应用于对引用的DR进行分类,还将性能与使用ImageNet的VIT预先训练的性能进行了比较。通过使用MAE进行超过100,000个视网膜图像预先培训,模型分类性能的改善优于预先训练的Ima-Genet。本模型的精度,曲线下的面积,最高灵敏度和最高特异性分别为93.42%,0.9853、0.973和0.9539。本研究表明,MAE可以为输入图像提供更大的灵活性,并大大减少所需图像的数量。同时,这项研究中的预处理数据集量表比ImageNet小得多,并且不需要ImageNet的预训练权重。


VIT2EEG:利用脑电图数据的混合预审前的视觉变压器
在这项研究中,我们证明了在电解图(EEG)回归任务上预处理的混合视觉变压器(VIT)模型的应用。最初接受了图像分类任务的训练,但在脑电图数据进行微调时,与其他模型相比,该模型的性能明显增加,包括相同的体系结构VIT训练而没有Imagenet权重。这一发现挑战了模型概括的传统范围,这表明在看似无关的图像数据上预测的变压器模型可以通过适当的精细调整管道为EEG回归任务提供宝贵的先验。这种方法的成功表明,在视觉任务中,VIT模型提取的功能可以很容易地用于EEG预测建模。我们建议不仅在神经科学和相关领域中利用这种方法,而且通常用于数据收集受实际,财务或道德约束限制的任何任务。我们的结果阐明了对任务明显不同的任务的潜力。
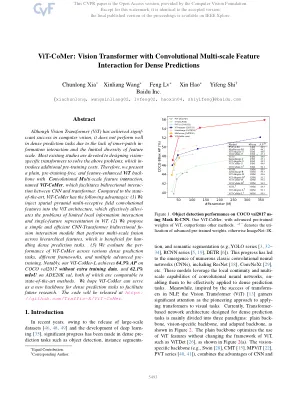
VIT-COMER:具有卷积多尺度特征相互作用的视觉变压器,用于密集预测
尽管Vision Transformer(VIT)在计算机视觉方面取得了显着的成功,但由于缺乏内部绘制互动和特征量表的多样性有限,它在密集的预测任务中表现不佳。大多数现有的研究致力于设计视觉特定的变压器来解决上述问题,从而涉及额外的培训前成本。因此,我们提出了一种普通的,无培训的且具有特征增强的vit背骨,并具有指定性的特征性动作,称为Vit-Comer,可促进CNN和Transformer之间的双向相互作用。与现状相比,VIT-COMER具有以下优点:(1)我们将空间金字塔多触发性场卷积特征注入VIT体系结构,从而有效地减轻了VIT中局部信息相互作用和单场表述的有限问题。(2)我们提出了一个简单有效的CNN转换器双向交互模块,该模块在跨层次特征上执行多尺度融合,这对Han-dling密集的预测任务有益。(3)我们评估了在各种密集的预测任务,不同框架和多个高级预训练中VIT-COMER的能力。值得注意的是,我们的VIT-COMER-L在没有额外训练数据的情况下可可Val2017上的AP达到64.3%,而ADE20K Val上的MIOU为62.1%,这两种方法都与最先进的方法相当。我们希望VIT-COMER可以作为密集预测任务的新骨干,以促进未来的研究。该代码将在https://github.com/traffic-x/vit-comer上发布。