XiaoMi-AI文件搜索系统
World File Search SystemVoight

2024-Career-fair-book_compressed.pdf
1-社区健康核心2-威利斯·奈顿健康3- Jet ProS,LLC 4-交叉世界5-任务航空奖学金6-富富,神学院神学院7-标准Aero 8-撒玛利亚人的钱包9-撒玛利亚人的钱包9-天空西航空10- oxy 11- oxy 11- oxy 11- oxy 11 -GFA世界12- Abernathy 19-动态航空20 -Textron Aviation 21 -Lockheed Martin 22-卡温顿飞机工程师,Inc。23-地铁航空24-美国陆军招募25 -Barnhart Crane&Riging 26 -CB&i

以及心力衰竭的罕见变异遗传结构......
David SM Lee,医学博士,哲学博士 1 ,Kathleen M. Cardone,理学士 2 ,David Y. Zhang,文学士 2 ,Noah L. Tsao,理学士 3 ,Sarah Abramowitz,文学士 3 ,Pranav Sharma,文学士 3 ,John S. DePaolo,医学博士,哲学博士 3 ,Mitchell Conery,文学士 4 ,Krishna G. Aragam,医学博士 5,6 ,Kiran Biddinger 6 ,Ozan Dilitikas,医学博士 7 ,Lily Hoffman- Andrews,理学硕士,CGC 8 ,Renae L. Judy,理学硕士 3 ,Atlas Khan,哲学博士 9 ,Iftikhar Kulo,医学博士 7 ,Megan J. Puckelwartz,哲学博士 10 ,Nosheen Reza,医学博士 7 ,Benjamin A. Satterfield,医学博士,哲学博士 7 ,Pankhuri Singhal,哲学博士2、Regeneron Genetics Center 11、Zoltan P. Arany,医学博士,哲学博士 8,12、Thomas P. Cappola,医学博士,理学硕士 8、Eric Carruth,哲学博士 13、Sharlene M. Day,医学博士 8,12、Ron Do,哲学博士 14,15,16、Christopher M. Haggarty,哲学博士 13、Jacob Joseph,医学博士 17,18、Elizabeth M. McNally,医学博士,哲学博士 19、Girish Nadkarni,医学博士,公共卫生硕士 20、Anjali T. Owens,医学博士 12、Daniel J. Rader,医学博士 2,21、Marylyn D. Ritchie,哲学博士 2,22、Yan V. Sun,哲学博士,理学硕士 23,24、Benjamin F. Voight,哲学博士 2,25,26,27、Michael G. Levin 医学博士 7,27 * † ,Scott M. Damrauer 医学博士 2,3,12,27 *

工作组会议纪要 2023 年 10 月 26 日
在线出席者:Daryl Wright、Julia Weigel、Luke Miller、Thomas LeQuire、Rebecca Price、Shannon Moore、Stuart Kaplow、Margaret Evans、Bruce Zavos、Scott Falvey、Nicholas Silbergeld、Scott Zacharko、Chelsea Steffes、Nicola Tran、Michael Matthews、Dun Scott、Cliff Majersik、Jared Deluccia、Bo Cheng、参议员 Ben Kramer、Ben Adams、Karen Massey、Aaron Rice Helps、Alice Bell、Eric Coffman、Jessica Riesett、Joanna Freeman、Luke Lanciano、Les Knapp、Lindsey Humphrey、Melissa Wilfong、Michael Manen、Rick Briemann、Steve Lauria、Todd Nedwick、Zachary Rockwell、Ruth White、众议员 Marvin Holmes、Khalid Malik、Kevin Walton、Daryl Wright、Kim Pezza、Joe Francaviglia、Chris Parts、Chris Stix、Amar Shah、Mark Szybist、Ruth Ann Norton、Shan Gordon、Seth Blumen、Jose Coronado-Flores、Smita Chandra Thomas、Anuj Khanna、Frederick Hoover、Ben Roush、Jamal Lewis、Justin Barry、Lisa Ramjohn、Louise Sharrow、Michael Flatt、Michael Hindle、Michael Powell、Hannah Allen、Erica Bannerman、James Burton、Senay Emmanuel、Liz Feighner、Nathan Fridinger、Joshua Galloway、Ashita Gona、Lori Graf、James Grevatt、Joshua Kace、Sonia Khanna、Logan Dean、Mark LeBel、Kathy Magruder、Greg Ackerman、Ian Marcus、Chris Hoagland、Tyler Pullen、Kristin Mielcarek、Cherise Seals、Ryan Trauley、Ben Voight
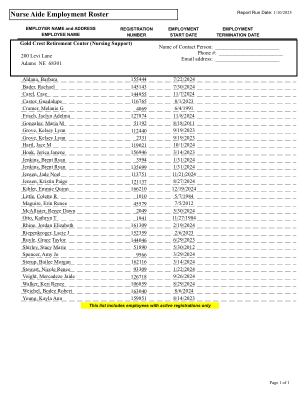
护士助理就业名册
Aldana, Barbara 155444 2024 年 7 月 22 日 Bader, Rachael 145143 2024 年 7 月 30 日 Carel, Case 144955 2024 年 11 月 7 日 Castor, Guadalupe 116765 2023 年 8 月 1 日 Cramer, Melanie G 4069 1991 年 6 月 4 日 Frisch, Jaclyn Adelma 127874 2024 年 11 月 8 日 Gonzalez, Maria M 51192 2011 年 8 月 18 日 Grove, Kelsey Lynn 112440 2023 年 9 月 19 日 Grove, Kelsey Lynn 2331 2023 年 9 月 19 日 Hartl, Jace M 119021 2024 年 10 月 1 日 Hoak, Jerica Janene 156946 2023 年 3 月 14 日 Jenkins,Brent Ryan 3594 2024 年 1 月 31 日 Jenkins,Brent Ryan 135699 2024 年 1 月 31 日 Jensen,Jade Noel 113751 2024 年 11 月 21 日 Jensen,Kristin Paige 121137 2024 年 8 月 27 日 Kibler,Emmie Quinn 166210 2024 年 12 月 19 日 Little,Colette R 1010 1984 年 5 月 7 日 Maguire,Erin Renee 45579 2012 年 7 月 5 日 McAllister,Renee Dawn 2049 2024 年 5 月 30 日 Otto,Kathryn T 1941 1984 年 11 月 27 日 Rhine,Jordan Elizabeth 161309 2024 年 2 月 19 日Riepenkroger,Lacie J 152359 2023 年 2 月 6 日 Ruyle,Grace Taylor 144046 2023 年 6 月 29 日 Shirley,Stacy Marie 51890 2012 年 5 月 30 日 Spencer,Amy Jo 9566 2024 年 3 月 29 日 Sterup,Bailee Morgan 162116 2024 年 3 月 14 日 Stewart,Nicole Renee 93309 2024 年 1 月 22 日 Voight,Mercadeze Jaide 126718 2024 年 9 月 26 日 Walker,Keri Renee 106859 2024 年 8 月 29 日 Weichel,Bodee Robert 163040 2024 年 8 月 6 日 Young,Kayla Ann 159851 2023 年 8 月 14 日

selscan 2.0:在未经遗传数据中扫描扫描
基于单倍型的摘要统计数据 - 例如IHS(Voight等人2006),NSL(Ferrer-Admetlla等人 2014),XP-EHH(Sabeti等人。 2007)和XP-NSL(Szpiech等人 2021) - 在进化基因组学研究中司空见惯,以确定种群中的最新和持续的阳性选择(例如, Colonna等。 2014,Zoledziewska等。 2015,Ne´de´lec等。 2016,Crawford等。 2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021)。 当适应性等位基因扫描一个人群时,它留下了长期高频单倍型和等位基因附近遗传多样性低的特征模式。 这些统计数据旨在通过总结单倍型纯合性的衰减来捕获这些信号,这是一个距离被推定的区域(IHS和NSL)或两个种群(XP-EHH和XP-NSL)之间的距离。 这些基于单倍型的统计数据非常有力地检测最近的阳性选择(Colonna等人 2014,Zoledziewska等。 2015,Ne´de´lec等。 2016,Crawford等。 2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021),并且两个人群版本甚至可以在很大的参数空间上进行成对的FST扫描(Szpiech等人。 2021)。 此外,基于单倍型的方法也已证明对背景选择是可靠的(Fagny等人。2006),NSL(Ferrer-Admetlla等人2014),XP-EHH(Sabeti等人。 2007)和XP-NSL(Szpiech等人 2021) - 在进化基因组学研究中司空见惯,以确定种群中的最新和持续的阳性选择(例如, Colonna等。 2014,Zoledziewska等。 2015,Ne´de´lec等。 2016,Crawford等。 2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021)。 当适应性等位基因扫描一个人群时,它留下了长期高频单倍型和等位基因附近遗传多样性低的特征模式。 这些统计数据旨在通过总结单倍型纯合性的衰减来捕获这些信号,这是一个距离被推定的区域(IHS和NSL)或两个种群(XP-EHH和XP-NSL)之间的距离。 这些基于单倍型的统计数据非常有力地检测最近的阳性选择(Colonna等人 2014,Zoledziewska等。 2015,Ne´de´lec等。 2016,Crawford等。 2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021),并且两个人群版本甚至可以在很大的参数空间上进行成对的FST扫描(Szpiech等人。 2021)。 此外,基于单倍型的方法也已证明对背景选择是可靠的(Fagny等人。2014),XP-EHH(Sabeti等人。2007)和XP-NSL(Szpiech等人2021) - 在进化基因组学研究中司空见惯,以确定种群中的最新和持续的阳性选择(例如,Colonna等。2014,Zoledziewska等。 2015,Ne´de´lec等。 2016,Crawford等。 2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021)。 当适应性等位基因扫描一个人群时,它留下了长期高频单倍型和等位基因附近遗传多样性低的特征模式。 这些统计数据旨在通过总结单倍型纯合性的衰减来捕获这些信号,这是一个距离被推定的区域(IHS和NSL)或两个种群(XP-EHH和XP-NSL)之间的距离。 这些基于单倍型的统计数据非常有力地检测最近的阳性选择(Colonna等人 2014,Zoledziewska等。 2015,Ne´de´lec等。 2016,Crawford等。 2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021),并且两个人群版本甚至可以在很大的参数空间上进行成对的FST扫描(Szpiech等人。 2021)。 此外,基于单倍型的方法也已证明对背景选择是可靠的(Fagny等人。2014,Zoledziewska等。2015,Ne´de´lec等。 2016,Crawford等。 2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021)。 当适应性等位基因扫描一个人群时,它留下了长期高频单倍型和等位基因附近遗传多样性低的特征模式。 这些统计数据旨在通过总结单倍型纯合性的衰减来捕获这些信号,这是一个距离被推定的区域(IHS和NSL)或两个种群(XP-EHH和XP-NSL)之间的距离。 这些基于单倍型的统计数据非常有力地检测最近的阳性选择(Colonna等人 2014,Zoledziewska等。 2015,Ne´de´lec等。 2016,Crawford等。 2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021),并且两个人群版本甚至可以在很大的参数空间上进行成对的FST扫描(Szpiech等人。 2021)。 此外,基于单倍型的方法也已证明对背景选择是可靠的(Fagny等人。2015,Ne´de´lec等。2016,Crawford等。 2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021)。 当适应性等位基因扫描一个人群时,它留下了长期高频单倍型和等位基因附近遗传多样性低的特征模式。 这些统计数据旨在通过总结单倍型纯合性的衰减来捕获这些信号,这是一个距离被推定的区域(IHS和NSL)或两个种群(XP-EHH和XP-NSL)之间的距离。 这些基于单倍型的统计数据非常有力地检测最近的阳性选择(Colonna等人 2014,Zoledziewska等。 2015,Ne´de´lec等。 2016,Crawford等。 2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021),并且两个人群版本甚至可以在很大的参数空间上进行成对的FST扫描(Szpiech等人。 2021)。 此外,基于单倍型的方法也已证明对背景选择是可靠的(Fagny等人。2016,Crawford等。2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021)。 当适应性等位基因扫描一个人群时,它留下了长期高频单倍型和等位基因附近遗传多样性低的特征模式。 这些统计数据旨在通过总结单倍型纯合性的衰减来捕获这些信号,这是一个距离被推定的区域(IHS和NSL)或两个种群(XP-EHH和XP-NSL)之间的距离。 这些基于单倍型的统计数据非常有力地检测最近的阳性选择(Colonna等人 2014,Zoledziewska等。 2015,Ne´de´lec等。 2016,Crawford等。 2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021),并且两个人群版本甚至可以在很大的参数空间上进行成对的FST扫描(Szpiech等人。 2021)。 此外,基于单倍型的方法也已证明对背景选择是可靠的(Fagny等人。2017,Meier等。2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021)。 当适应性等位基因扫描一个人群时,它留下了长期高频单倍型和等位基因附近遗传多样性低的特征模式。 这些统计数据旨在通过总结单倍型纯合性的衰减来捕获这些信号,这是一个距离被推定的区域(IHS和NSL)或两个种群(XP-EHH和XP-NSL)之间的距离。 这些基于单倍型的统计数据非常有力地检测最近的阳性选择(Colonna等人 2014,Zoledziewska等。 2015,Ne´de´lec等。 2016,Crawford等。 2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021),并且两个人群版本甚至可以在很大的参数空间上进行成对的FST扫描(Szpiech等人。 2021)。 此外,基于单倍型的方法也已证明对背景选择是可靠的(Fagny等人。2018,Lu等。2019,Zhang等。 2020,Salmo´n等。 2021)。 当适应性等位基因扫描一个人群时,它留下了长期高频单倍型和等位基因附近遗传多样性低的特征模式。 这些统计数据旨在通过总结单倍型纯合性的衰减来捕获这些信号,这是一个距离被推定的区域(IHS和NSL)或两个种群(XP-EHH和XP-NSL)之间的距离。 这些基于单倍型的统计数据非常有力地检测最近的阳性选择(Colonna等人 2014,Zoledziewska等。 2015,Ne´de´lec等。 2016,Crawford等。 2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021),并且两个人群版本甚至可以在很大的参数空间上进行成对的FST扫描(Szpiech等人。 2021)。 此外,基于单倍型的方法也已证明对背景选择是可靠的(Fagny等人。2019,Zhang等。2020,Salmo´n等。2021)。当适应性等位基因扫描一个人群时,它留下了长期高频单倍型和等位基因附近遗传多样性低的特征模式。这些统计数据旨在通过总结单倍型纯合性的衰减来捕获这些信号,这是一个距离被推定的区域(IHS和NSL)或两个种群(XP-EHH和XP-NSL)之间的距离。这些基于单倍型的统计数据非常有力地检测最近的阳性选择(Colonna等人2014,Zoledziewska等。 2015,Ne´de´lec等。 2016,Crawford等。 2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021),并且两个人群版本甚至可以在很大的参数空间上进行成对的FST扫描(Szpiech等人。 2021)。 此外,基于单倍型的方法也已证明对背景选择是可靠的(Fagny等人。2014,Zoledziewska等。2015,Ne´de´lec等。 2016,Crawford等。 2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021),并且两个人群版本甚至可以在很大的参数空间上进行成对的FST扫描(Szpiech等人。 2021)。 此外,基于单倍型的方法也已证明对背景选择是可靠的(Fagny等人。2015,Ne´de´lec等。2016,Crawford等。 2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021),并且两个人群版本甚至可以在很大的参数空间上进行成对的FST扫描(Szpiech等人。 2021)。 此外,基于单倍型的方法也已证明对背景选择是可靠的(Fagny等人。2016,Crawford等。2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021),并且两个人群版本甚至可以在很大的参数空间上进行成对的FST扫描(Szpiech等人。 2021)。 此外,基于单倍型的方法也已证明对背景选择是可靠的(Fagny等人。2017,Meier等。2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021),并且两个人群版本甚至可以在很大的参数空间上进行成对的FST扫描(Szpiech等人。 2021)。 此外,基于单倍型的方法也已证明对背景选择是可靠的(Fagny等人。2018,Lu等。2019,Zhang等。 2020,Salmo´n等。 2021),并且两个人群版本甚至可以在很大的参数空间上进行成对的FST扫描(Szpiech等人。2019,Zhang等。2020,Salmo´n等。2021),并且两个人群版本甚至可以在很大的参数空间上进行成对的FST扫描(Szpiech等人。2021)。此外,基于单倍型的方法也已证明对背景选择是可靠的(Fagny等人。2014,Schrider 2020)。 然而,这些统计数据中的每一个都认为单倍型相是已知或据估计的。 作为非模型生物的基因组测序数据的产生正在变得常规(Ellegren 2014),有很多很大的机会来研究整个生命之树的最新适应性(例如, Campagna和Toews 2022)。 但是,这些生物/种群通常没有特征良好的人口历史或重组率2014,Schrider 2020)。然而,这些统计数据中的每一个都认为单倍型相是已知或据估计的。作为非模型生物的基因组测序数据的产生正在变得常规(Ellegren 2014),有很多很大的机会来研究整个生命之树的最新适应性(例如,Campagna和Toews 2022)。但是,这些生物/种群通常没有特征良好的人口历史或重组率