XiaoMi-AI文件搜索系统
World File Search Systemcovariates

癌症治疗的合成杀伤力的进步
抽象目的Tepotinib是一种高度选择性,有效的间质 - 上皮过渡因子(MET)抑制剂,批准用于治疗具有MET Exon 14跳过的非小细胞肺癌(NSCLC)。该人群药物的目标(PK)分析是为了评估Tepotinib及其主要循环代谢物MSC2571109A的剂量暴露关系,并识别可预测PK变异性的内在/外在因素。方法数据包括来自12例癌症患者和健康参与者的研究。一种顺序建模方法用于分析父和代谢物数据,包括协变量分析。使用基于自举分析的森林图说明了观察到的协变量与PK参数之间的潜在关联。导致一个两室模型,具有顺序的零和一阶吸收,并且从中央隔室中消除了一阶消除,最好描述了人类在30-1400 mg的剂量范围内tepotinib的等离子体PK。tepotinib的生物可用性被证明是剂量依赖性的,尽管生物利用度主要以500 mg的治疗剂量高于治疗剂量下降。种族,年龄,性别,体重,轻度/中度肝损伤以及轻度/中度肾功能障碍的内在因素以及阿片类镇痛药和吉非替尼的外在因素对Tepotinib PK没有相关作用。tepotinib的有效半衰期约为32小时。结论Tepotinib显示至少至少具有治疗剂量的剂量比例,并且与时间无关的清除率具有适合每日给药的概况。均未确定的协变量对Tepotinib暴露或所需剂量调整具有临床意义。

发作性和慢性偏头痛患者的结构性脑网络特征
基于Desikan Atlas的每个半球区域(55)。随后,我们使用了亚皮质网络中每个半球和脑干的九个区域的亚皮质体积。用于评估患者和HC之间图指标的统计学意义,应用了5000次迭代的非参数置换测试(56,57)。鉴于CT对年龄和性别很敏感,它们被进一步用作分析的协变量。在每个重复中,每个受试者的区域数据被随机重新分配至两组之一,并获得了一个关联矩阵。然后计算每个密度的所有网络的网络度量。在这里,密度代表通过与所有可能连接的当前连接的分数计算的网络成本。因此,网络测量

血液学肿瘤中同种异体干细胞移植的个性化时间:使用多层建模和微仿真的目标试验仿真方法
患者预科用根据决策过程中的临床相关性所选择的关键因素(对于MDS:年龄:IPSS-R/IPSS-M)所选择的关键因素。7,8目的是通过使用不同的移植策略计算质量调整后的平均生存时间来确定最佳策略,并在每个患者中进行比较。出于这个原因,多层建模框架用于考虑治疗前和治疗后的疾病状态,并根据治疗性治疗和治疗后结果调整可能的混杂因素。这个多态疾病模型描述了该疾病的自然史,并估算了感兴趣的协变量的影响。最后,实施了基于微观仿真的决策模型,以确定与最高生存时间相关的过程的最佳时机。

1 标题:使用预测临床的规范建模...
注意:当您需要对新数据进行预测时,该过程会更加复杂,因为我们需要准备、处理和存储适应数据的协变量、响应变量和站点 ID。 for idp_num, idp in enumerate(idp_ids): print(' Running IDP ', idp_num, idp, ': ') idp_dir = os.path.join(out_dir, idp) os.chdir(idp_dir) # 提取并保存测试集的响应变量 y_te = df_te[idp].to_numpy() # 保存变量 resp_file_te = os.path.join(idp_dir, 'resp_te.txt') np. savetxt(resp_file_te,y_te)#配置并保存设计矩阵cov_file_te = os.path.join(idp_dir,'cov_bspline_te.txt')X_te = create_design_matrix(df_te[cols_cov],


临时翻译(截至 2020 年 7 月)*
根据所分析的临床研究的设计,考虑按照方案中预先确定的研究目的定义的终点分析的分析集、要评价的指标及汇总方法、脱落、观测值缺失等中期事件的处理、缺失数据的填补方法。因此,在规划临床研究时,负责暴露-反应关系的人员(临床药理学家、药理计量学家等)应与临床医生、生物统计学家及参与研究的其他相关人员进行讨论,在制定分析计划之前明确暴露-反应关系相关的协变量、预后因素、混杂因素、缺失值等的处理规则。
支持制定行为反应噪声暴露标准的分析方法
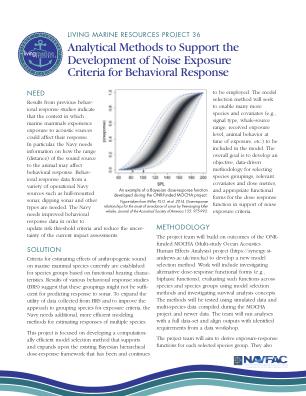
开发更有效的模型选择方法将最大限度地发挥现有贝叶斯分层剂量反应框架的潜力。结果将为开发海军第四阶段行为风险功能的人员提供物种分组。虽然不需要使用这些分组,但它们至少会提供另一个证据来指导物种分组的创建。拟议的工作还将解决了解响应性与剂量指标之间关系的需要,而不是与接收声级相关的剂量指标。该模型将使用当前可用的数据来拟合鲸鱼源范围与响应概率之间的关系,并确定这种关系的形式以及物种内和物种之间的变异水平。结果将提供有关数据要求、数据格式、优先协变量和剂量指标的指导,以确保将来收集的数据可用于此框架。

引用 Larue F、Rouan L、Pot D、Rami J-F、Luquet D 和 Beurier G (2024) 使用神经网络将遗传标记和作物模型参数链接到 e
需要开发适应不断变化的生产情景的植物品种,特别是在气候变化的情况下,这要求作物满足日益复杂和多样化的需求,这对育种者来说是一个巨大的挑战。在此背景下,追求赋予所需作物特性和适应性的性状组合比以往任何时候都更加重要,因此有必要加强多标准或多性状育种(Moeinizade 等人,2020 年)。利用分布在基因组中的完整核苷酸多样性来预测数量性状的育种值(基因组预测,GP,Meuwissen 等人,2001 年)已证明其在育种计划中的有效性。事实证明,这种方法有助于提高遗传增益率并降低成本(Hickey 等人,2017 年)。然而,为了应对气候变化和更明确的环境目标种群(Chapman 等人,2000 年),对多环境(ME)育种的需求日益增长,这需要采用基因组预测方法来解释基因型和环境(GxE)之间相互作用的出现(Rincent 等人,2017 年)。先前的研究试图在基因组选择(GS)中解决 GxE。例如,Burgueño 等人(2012) 开发了多环境统计模型。然而,这些模型仅考虑线性和非因果环境效应,从而降低了预测准确性的可能增益,尤其是对于复杂的综合性状或与校准集有显着差异的环境(Rogers and Holland,2022)。Heslot 等人。另一方面,(2014 年)使用作物生长模型 (CGM) 来推导环境协变量。与标准 GS 模型相比,在 GS 框架内加入环境协变量可提高预测准确性并降低未观察环境中的预测变异性。整合作物模型以解决 GxE,如 Heslot 等人的研究所示。(2014) ,强调了这种方法在所述育种环境中的实用性。尽管如此,考虑大量协变量会显著增加问题的复杂性,使得建模变得极具挑战性(Larkin 等人,2019 年)。

使用机器学习和高分辨率激光雷达地形数据绘制丘陵景观的地形
地图是评估土壤和生态杂质的过程和危害,水文建模以及自然资源和土地管理的重要工具。基于现场调查或航空照片的映射土地形式的传统技术可能是时间和劳动密集型,强调了基于遥感产品的自动或半自动方法的重要性。此外,时间密集的手动标记也可以是主观的,而不是对地形的客观识别。在这里,我们实施了一种客观的方法,该方法将随机的森林机器学习算法应用于一组观察到的地形数据和1M水平分辨率裸露的数字高程模型(DEM),它是从空气中的光检测和范围数据(LIDAR)数据开发的,以快速映射丘陵地面的各种地面地面。地面分类包括高地高原,山脊,凸面,平面斜坡,凹陷坡,溪流通道和山谷底部,横跨俄克拉荷马州东北部俄克拉群岛的Ozark山脉的400公里2丘陵景观。我们使用了4200个地面观测值(每个地形600个)和八个从随机森林算法中的2 m,5 m和10 m分辨率LIDAR DEM得出的地形指数,以开发2 m,5 m和10 m分辨率地分辨率地面地面模型。我们通过比较观察到的地貌与建模地面的地图来测试DEM分辨率在映射地图中的有效性。结果表明,当协变量以2 m的分辨率分辨率为〜89%时,该方法绘制了约84%的观察到的地形,分辨率为10 m。使用这种方法开发的地图图具有多种潜在应用。然而,预测的地图显示,2 m分辨率的协变量在捕获准确的地形边界和小型地面的细节(例如溪流通道和山脊)方面表现更好。与使用空中图像和现场观测值相比,此处介绍的方法大大减少了绘制地图的时间,并允许掺入各种各样的协变量。它可以用于水文建模,自然资源管理,并在丘陵景观中表征土壤地球形过程和危害。

eDNAjoint:贝叶斯框架下传统和环境 DNA 调查数据的联合建模
描述模型整合了环境 DNA (eDNA) 检测数据和传统调查数据,以联合估计物种捕获率(参见包插图:< https://ednajoint.netlify.app/ >)。模型可以与通过传统调查方法(即诱捕、电捕鱼、目测)获得的计数数据以及通过聚合酶链反应(即 PCR 或 qPCR)从多个调查地点复制的 eDNA 检测/未检测数据一起使用。估计参数包括假阳性 eDNA 检测的概率、相对于传统调查缩放 eDNA 调查灵敏度的站点级协变量以及传统渔具类型的捕获系数。模型使用“Stan”概率编程语言通过贝叶斯框架(马尔可夫链蒙特卡罗)实现。