XiaoMi-AI文件搜索系统
World File Search Systemdrl
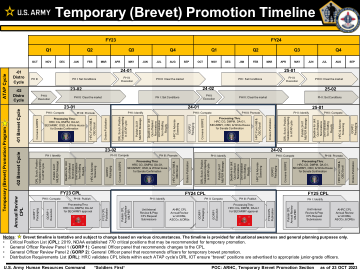
临时 (Brevet) 晋升时间表
注意:名誉晋升时间表是暂定的,可能会根据各种情况而更改。时间表仅用于态势感知和一般规划目的。• 关键职位清单 (CPL):2019 年,NDAA 设立了 770 个可能被推荐临时晋升的关键职位。• 一般官员审查小组 1 (GORP 1):建议对 CPL 进行更改的一般官员小组。• 一般官员审查小组 2 (GORP 2):建议官员临时获得名誉晋升的一般官员小组。• 分配要求清单 (DRL):HRC 在每个 ATAP 周期的 DRL IOT 中验证 CPL 职位,确保“名誉”职位被公布给适当的初级官员。

硕士论文多代理增强学习网格为智能网格的分布式能源的控制
向分散的可再生能源(例如太阳能和风)的转变需要能源需求才能适应天气条件,从而对电网构成挑战。传统解决方案涉及加强网格或基于预测和线性优化或基于规则的方法的管理系统。这些常规模型是复杂且刚性的,需要对不同的网格拓扑进行大量的手动适应,通常会限制优化潜力。作为替代性的深入增强学习(DRL)提供了一种更灵活,更适应性的方法。drl自主探索并从其环境中学习,消除了对明确的数学配方的需求,并使其非常适合动态能源管理系统。

哺乳动物大脑中的分布式强化学习
分布式强化学习 (dRL) —— 学习预测的不仅是平均回报,还有回报的整个概率分布 —— 在广泛的基准机器学习任务中取得了令人印象深刻的表现。在脊椎动物中,基底神经节强烈编码平均值,长期以来被认为是实现 RL 的,但对于该回路中的神经元群是否、在何处以及如何编码有关奖励分布高阶矩的信息知之甚少。为了填补这一空白,我们使用 Neuropixels 探针来敏锐地记录执行经典条件反射任务的训练有素、缺水的小鼠的纹状体活动。在几个表征距离测量中,与相同奖励分布相关的气味彼此之间的编码相似度要高于与相同平均奖励但不同奖励方差相关的气味,这与 dRL 的预测一致,但不是传统 RL。光遗传学操作和计算建模表明,遗传上不同的神经元群编码了这些分布的左尾和右尾。总的来说,这些结果揭示了 dRL 与哺乳动物大脑之间显著的融合程度,并暗示了同一总体算法的进一步生物学专业化。

文章基于深度强化学习的车辆到电网运行策略,用于管理太阳能发电预测误差
摘要:本研究提出了一种基于深度强化学习 (DRL) 的车辆到电网 (V2G) 运营策略,该策略侧重于动态整合充电站 (CS) 状态以优化太阳能发电 (SPG) 预测。为了解决太阳能和 CS 状态的变化,本研究提出了一种新方法,将 V2G 运营制定为马尔可夫决策过程,并利用 DRL 自适应地管理 SPG 预测误差。利用韩国南方电力公司的实际数据,使用 PyTorch 框架证明了该策略在增强 SPG 预测方面的有效性。结果表明,与没有 V2G 的情景相比,均方误差显著降低了 40% 至 56%。我们对阻塞概率阈值和折扣因子影响的研究揭示了最佳 V2G 系统性能的见解,表明在即时运营需求和长期战略目标之间取得平衡。研究结果强调了使用基于 DRL 的策略实现电网更可靠、更高效的可再生能源整合的可能性,标志着智能电网优化向前迈出了重要一步。

一种联合的深入强化学习方法
摘要:本文提出了使用联合加固学习(FRL)的多个智能建筑物的共享存储系统(SESS)的隐私能源管理(SESS)。为了保留与SESS连接的建筑物的能源计划的隐私,我们使用FRL方法提出了分布式的深入强化学习(DRL)框架,该方法由全球服务器(GS)和本地建筑能源管理系统(LBEMSS)组成。在框架中,LBEMS DRL代理仅与无需消费者的能耗数据的GS共享其训练有素的能源消耗模型的训练有素的神经网络。使用共享模型,GS执行了两个过程:(i)向LBEMS代理的全球能源消耗模型的构建和广播,以培训其本地模型,以及(ii)培训SESS DRL代理商的能源充电和从公用事业和建筑物中释放。模拟研究是使用带有太阳能电动系统的一台SES和三个智能建筑进行的。结果表明,所提出的方法可以安排和排放SESS的充电和排放,并在智能建筑环境下的智能建筑物中供暖,通风和空调系统的最佳能源消耗,同时保留建筑物能源消耗的隐私。

情境感知深度强化学习... - arXiv
摘要 —随着无人机技术的快速发展,无人机被广泛应用于包括军事领域在内的许多应用领域。本文提出了一种新型的基于情境感知 DRL 的自主非线性无人机机动性控制算法,应用于网络物理巡飞弹药。在战场上,基于 DRL 的自主控制算法的设计并不简单,因为通常无法收集现实世界的数据。因此,本文的方法是利用 Unity 环境构建网络物理虚拟环境。基于虚拟网络物理战场场景,可以设计、评估和可视化基于 DRL 的自动非线性无人机机动性控制算法。此外,在现实战场场景中,存在许多不利于线性轨迹控制的障碍物。因此,我们提出的自主非线性无人机机动性控制算法利用了情境感知组件,这些组件是在 Unity 虚拟场景中使用 Raycast 函数实现的。基于收集到的态势感知信息,无人机可以在飞行过程中自主且非线性地调整其轨迹。因此,这种方法显然有利于在布满障碍物的战场上避开障碍物。我们基于可视化的性能评估表明,所提出的算法优于其他线性移动控制算法。

深入强化学习基于钢生产线的维护决策
洛林大学,法国克兰。电子邮件:phuc.do@univ-lorraine.fr在4.0行业中,采用系统监控技术提供了有关系统健康状况的大量数据,这引发了采用基于条件的维护(CBM)的挑战。 由于其能力基于其嵌入式状况监测设备实时采用系统,这可以帮助降低O&M成本并提高系统可用性,因此CBM已成为行业竞争力的一种相关方法。 但是,要利用大量数据在维护决策中的优势,要考虑的一个重要问题是国家和行动的巨大空间,这很难应对传统的维护模型。 为了克服这个问题,将机器学习和人工智能的新兴工具整合到维护决策和优化中似乎是有希望的。 因此,这项工作提出了对钢生产线的基于深入的加固学习(DRL)的维护优化,其中维护决策是根据有关系统状况的实时数据做出的。 研究的生产线使用金属废料作为钢材制造的原材料。 在使用之前,需要将废料粉碎在切碎机器中,这是最关键的过程。 当机器关闭以进行维护操作时,使用中间的缓冲区来继续为其余站提供碎屑。 建立了模拟模型,以模拟生产线的动态。 关键字:深钢筋学习,维护,钢生产线,模拟模型电子邮件:phuc.do@univ-lorraine.fr在4.0行业中,采用系统监控技术提供了有关系统健康状况的大量数据,这引发了采用基于条件的维护(CBM)的挑战。由于其能力基于其嵌入式状况监测设备实时采用系统,这可以帮助降低O&M成本并提高系统可用性,因此CBM已成为行业竞争力的一种相关方法。但是,要利用大量数据在维护决策中的优势,要考虑的一个重要问题是国家和行动的巨大空间,这很难应对传统的维护模型。为了克服这个问题,将机器学习和人工智能的新兴工具整合到维护决策和优化中似乎是有希望的。因此,这项工作提出了对钢生产线的基于深入的加固学习(DRL)的维护优化,其中维护决策是根据有关系统状况的实时数据做出的。研究的生产线使用金属废料作为钢材制造的原材料。在使用之前,需要将废料粉碎在切碎机器中,这是最关键的过程。当机器关闭以进行维护操作时,使用中间的缓冲区来继续为其余站提供碎屑。建立了模拟模型,以模拟生产线的动态。关键字:深钢筋学习,维护,钢生产线,模拟模型然后建立一个DRL框架,以通过与环境的交互进行学习,以找到最低维护成本的最佳维护政策。进行了数值案例研究,以评估所提出的DRL维护方法与常规维护策略相比。结果,提出的DRL方法在成本以及系统可用性的增加方面显示出更好的结果。

车辆网络的深入强化学习技术:最新的进步和未来趋势6G
将机器学习用于6G车辆网络,以支持车辆应用服务,并广泛研究了文献中最新研究工作的热门话题。本文提供了对研究作品的全面看法,这些研究工作整合了用于车辆网络管理的强化和深入的增强学习算法,重点是车辆电信问题。车辆网络已成为重要的研究领域,因为它们的特定功能和应用(例如标准化,有效的官能管理,道路安全性和侵害)。在此类网络中,网络实体需要做出决策,以最大程度地提高不确定性的网络性能。为了实现这一目标,建议学习(RL)可以有效地解决决策问题。但是,在大型无线网络中,状态和行动空间是庞大而复杂的。因此,RL可能无法在合理的时间内找到最佳策略。因此,已经开发了深入的增强学习(DRL),以将RL与深度学习(DL)结合起来,以克服这个问题。在这项调查中,我们第一个目前的车辆网络并简要概述了RL和DRL概念。然后,我们回顾RL,尤其是DRL方法,以解决6G车辆网络中的新兴问题。我们最终讨论并突出了一些未解决的挑战以进行进一步研究。

摘要 - 生成扩散模型(GDMS),在对各种域的复杂数据分布进行建模方面取得了显着的进步。同时,D
摘要 - 生成扩散模型(GDMS),在对各种域的复杂数据分布进行建模方面取得了显着的进步。与此同时,深度加固学习(DRL)在优化Wi-Fi网络性能方面已显示出重大改进。Wi-Fi优化问题对于数学上的模型来说是高度挑战性的,DRL方法可以绕过复杂的数学建模,而GDMS在处理复杂的数据建模方面表现出色。因此,将DRL与GDM相结合可以相互增强其功能。Wi-Fi网络中当前的MAC层访问机制是分布式协调函数(DCF),它在大量端子中大大降低了性能。在这项研究中,我们提出了深层扩散确定性策略梯度(D3PG)算法,该算法将扩散模型与深层确定性策略梯度(DDPG)框架集成在一起,以优化Wi-Fi网络性能。据我们所知,这是在Wi-Fi性能优化中应用这种集成的第一项工作。我们提出了一种基于D3PG算法的共同调整争议窗口和聚合框架长度的访问机制。通过模拟,我们证明了这种机制在密集的Wi-Fi方案中显着优于现有的Wi-Fi标准,即使用户数量急剧增加,也保持了性能。

使用深度强化学习生成航天器操作程序
太空任务操作的高成本促使多个航天机构优先开发自主航天器指挥和控制技术。深度强化学习 (DRL) 技术为创建复杂、多方面的操作问题的自主代理提供了一个有前途的领域。这项工作研究了将 DRL 驱动的策略生成算法应用于航天器决策问题的可行性,包括构建航天器决策问题的策略,例如马尔可夫决策过程、降维途径、使用专家领域知识进行简化、对超参数的敏感性以及面对错误建模的环境动态时的鲁棒性。此外,在屏蔽深度强化学习的新颖改编中,考虑通过将这些方法与构造正确的控制技术相结合来确保这些方法的安全性。这些策略针对原型低保真驻留场景和高保真姿态模式管理场景进行了演示,涉及飞行遗产姿态控制和动量管理算法。研究发现,DRL 技术与这些问题的其他黑盒优化工具或启发式解决方案相比具有优势,并且需要与深度学习社区中广泛使用的测试数据集类似的网络规模和训练持续时间。