XiaoMi-AI文件搜索系统
World File Search Systemischool

ischool 应急响应袖珍计划
• UW 应急管理办公室 206-897-8000 • UW 应急行动地点 UW 大厦,C 140 • UW 应急管理电子邮件 disaster@uw.edu • UWPD 911(线路可能超载) • UWPD 电子邮件 uwpolice@uw.edu • UWPD 网站 police.uw.edu • UWPD 非紧急情况 206-685-8973 • UW 警报注册 uwalert.org • UW 警报博客 emergency.uw.edu • UW 警报推特 twitter.com/uwalert • MyUW my.uw.edu • UW 主页上的紧急横幅 washington.edu • iSchool 紧急情况网站 emergency.ischool.uw.edu • Microsoft Teams og_ischool_all > 紧急登记 • 这些列表服务器上的电子邮件:ifac@uw.edu、istaff@uw.edu、

INF 385T:健康领域的人工智能 - UT iSchool
课程简介 最近,美国医疗行业已超越制造业和零售业,成为该国最大的就业行业,每 8 个美国人中就有 1 个在该行业工作。已经建立了政策和激励措施来促进医疗保健领域的信息技术发展,以改善护理和提供服务。在本课程中,我们将探索健康 IT 系统的主要组成部分,从数据语义 (ICD10)、数据互操作性 (FHIR)、诊断代码 (SNOMED CT) 到临床决策支持系统中的工作流程。在对健康 IT 系统基础知识建立良好的理解之后,我们将深入研究 AI 创新(例如机器学习、深度学习、计算机视觉)如何通过引入移动健康、AI 诊断、AI 医疗、智能设备和智能交付的新概念来改变我们的医疗保健系统。本课程将基于 MIT Critical Data 发布的 MIMIC III(https://mimic.physionet.org/)中的真实世界电子健康记录 (EHR) 数据提供实践教程。 MIMIC-III(重症监护 III 医疗信息集市)包含 2001 年至 2012 年间在贝斯以色列女执事医疗中心重症监护室住院的四万多名患者的匿名健康信息。这些教程旨在通过提供与数据库搜索、自然语言处理、数据可视化、机器学习和深度学习相关的实践来增强数据搜索和分析技能。在本课程中,我们将增强小组学习体验和边做边学,因此将有许多课堂活动。本课程适合所有人,因此不需要或不需要编程背景。

可解释人工智能课程大纲 2024 年春季 - UT iSchool
未经我书面明确许可,不得在线或与课外任何人共享本课程中使用的任何材料,包括但不限于讲义、视频、评估(测验、考试、论文、项目、家庭作业)、课堂材料、复习表和其他问题集。未经授权共享材料可能会助长作弊行为。大学了解用于共享材料的网站,任何与您相关的在线材料或任何疑似未经授权共享材料的行为都将报告给学生主任办公室的学生行为和学术诚信部门。这些报告可能导致启动学生行为流程,并包括对学术不端行为的指控,可能导致制裁,包括影响成绩。

展望未来:将人工智能纳入 MLIS 能力
摘要 摘要长期以来,图书馆对于知识民主化和提供可靠信息至关重要,其服务范围扩大到满足各种社区需求,包括教育计划和互联网接入 (Pawley, 2022; Freudenberger, 2022)。图书馆员作为信息和文化的保管人,拥有信息组织、数字素养和研究技能方面的核心能力。圣何塞州立大学 (SJSU) 信息学院 (iSchool) 旨在通过高质量的教育、研究和技术创新培养对全球社区产生重大影响的专业人士。本文研究了 SJSU iSchool 的图书馆和信息科学硕士 (MLIS) 课程,重点关注其 14 项核心能力的演变,以融入人工智能 (AI) 的进步。随着人工智能改变教育课程和行政流程,需要更新以包括数字素养、人工智能伦理和数据隐私,确保 MLIS 毕业生具备在人工智能整合的未来中领导的能力。通过将这些能力与 iSchool 的战略愿景相结合,本文提供了将人工智能融入现有能力的建议,并确定了潜在的新能力,以有效满足新兴的工作场所需求。
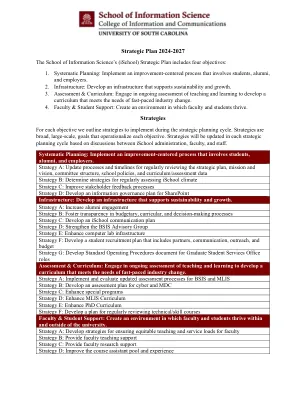
2024-2027 年战略计划
系统规划:实施以改进为中心的流程,让学生、校友和雇主参与其中。策略 A:更新流程和时间表,以定期审查战略计划、使命和愿景、委员会结构、学校政策以及课程/评估数据策略 B:确定定期评估 iSchool 氛围的策略策略 C:改进利益相关者反馈流程策略 D:制定 SharePoint 基础架构的信息治理计划:开发支持可持续性和增长的基础架构。策略 A:增加校友参与度策略 B:提高预算、课程和决策过程的透明度策略 C:制定 iSchool 沟通计划策略 D:加强 BSIS 咨询小组策略 E:增强计算机实验室基础设施策略 F:制定包括合作伙伴、沟通、外展和预算的学生招募计划策略 G:为研究生服务办公室角色制定标准操作程序文件评估和课程:持续评估教学和学习,以开发满足快速行业变化需求的课程。策略 A:实施和评估 BSIS 和 MLIS 的最新评估流程 策略 B:制定网络和 MDC 评估计划 策略 C:增强特殊计划 策略 D:增强 MLIS 课程 策略 E:增强 PhD 课程 策略 F:制定定期审查技术/技能课程的计划 师生支持:营造一个让师生在大学内外都能茁壮成长的环境。 策略 A:制定确保教师教学和服务负担公平的策略 策略 B:为教师提供教学支持 策略 C:为教师提供研究支持 策略 D:改善课程助理人才库和经验

hcil-symposium-2024-full-program.pdf
1983年在马里兰大学推出的人类计算机互动实验室(HCIL)拥有丰富的历史,可以改变人们通过新技术的经验。从了解用户需要开发和评估这些技术的情况下,实验室的教职员工和学生已经领导HCI研究已有40多年了。HCIL是在马里兰州高级计算机研究研究所(UMIACS)内建立的。今天,HCIL参与者包括校园以下单位的教职员工和学生:信息研究(iSchool),计算机科学,心理学,教育,英语,工程,新闻学和美国研究。此外,HCIL教师是校园中许多中心和机构的成员企业家精神。这本小册子包含座谈会摘要以及过去一年中我们教师新闻和成就的精选亮点。请访问我们的网站(https://hcil.umd.edu),以了解有关HCIL中正在进行的研究的更多信息。如果您想要更多信息,请联系:

什么是机器学习以及如何工作
机器学习是人工智能的一部分,可以分析数据以对未来事件进行预测。此过程涉及诸如收集和准备数据,构建模型,培训它们,测试其准确性,可视化结果并将最终产品部署在金融,医疗保健,市场营销,教育等各个行业等步骤等。机器学习使用不同的算法和模型来了解复杂的数据,识别模式并做出明智的决定。由于神经网络和深度学习的进步以及大型数据集和复杂技术(例如自然语言处理,计算机视觉和增强学习)的可用性,近年来它变得越来越流行。该领域在各个领域都有许多应用程序,包括医疗保健,可以通过分析患者数据,在优化库存水平,减少欺诈和风险评估的地方进行融资,以及在其启用有针对性的广告的地方进行融资,在其中优化库存水平,融资,在此方面有助于诊断疾病。机器学习建立稳定业务的潜力是广泛的,这对于希望改善其运营的行业来说是必不可少的工具。机器学习可以分为四种主要类型:监督,半监督,无监督和强化学习。这些类型在使用数据的方式和为模型提供的指导级别上有所不同。例如,监督的学习使用标记的数据来训练模型,而无监督的学习依赖于未标记的数据来识别模式。关键概念,例如算法,模型,培训,测试等,在机器学习中起着至关重要的作用。通过实际示例理解这些概念,例如根据历史数据预测房价,可以为机器学习及其潜在应用的运作提供宝贵的见解。某些输入变量,例如房间平方英尺的数量等在确定住房价格算法中起关键作用错误代码实施遵循系统步骤,包括数据收集预处理模型培训评估部署数据收集质量收集质量可以确定准确性数据可以来自API网站社交媒体社交媒体社交媒体或构建的语言的道德注意事项,例如公平隐私等公平隐私应在脑海中保留数据中应在数据中置于数据预处理的范围,以提高较高的差异级别的差异级别的差异级别的质量质量质量质量质量质量质量质量的质量质量质量质量质量质量,使得质量质量质量质量质量,使得质量质量质量质量差异,远程质量的质量质量差异树木超参数调整改进准确性模型评估使用诸如精确度召回F1得分AUC交叉验证技术等指标来评估绩效,这有助于确定效率模型模型部署将训练有素的部署集成到解决其他步骤中,这些步骤涉及其他步骤,涉及可视化预测的准确性,以了解预测性能预测性模型在功能上促进了功能界定模型,并在功能上促进了多个计算模型。负责任的模型开发方法对于有效使用数据集至关重要。在部署过程中出现挑战:必须尊重数据隐私,算法必须是公正的,并且透明度对于代码解释性至关重要。必须通过抽样对人群进行公平表示,以防止数据和算法的偏见。模型解释性能够理解预测,而应考虑社会影响,因为机器学习可能会对社会产生正面或负面影响。数据匿名,加密和差异隐私等技术可以最大程度地减少偏见并保护用户隐私。总而言之,尽管机器学习提供了许多好处,但它需要仔细处理和考虑各种数据以防止偏见的结果。本文讨论了在各个领域负责使用机器学习模型的重要性,包括在部署期间面临的挑战和应观察到的道德实践。三种主要的学习类型包括受监督,无监督和强化学习,每个学习都解决了不同的问题。监督学习利用标记的数据,使模型可以学习模式并对新数据进行预测。监督学习的例子包括语音识别,医学诊断,欺诈检测和产品推荐系统。无监督的学习确定未标记数据中的模式,并根据相似性或差异组织。电子邮件中的异常检测是无监督学习的一个典型示例,该系统分析了大量数据以了解构成典型电子邮件的内容。在机器学习中,有多种方法,包括受监督和无监督的方法,每个方法都解决了独特的挑战和应用。通过承认这些差异并意识到潜在的偏见,开发人员可以创建有效和负责任的模型,从而使社会受益,同时最大程度地减少伤害。机器学习模型使用各种技术来检测欺诈,细分客户,提出内容建议并优化物流。无监督的学习有助于识别数据中的模式,而半监督的学习结合了标记和未标记的数据集,以提高准确性。强化学习涉及反复试验,系统通过与环境的互动进行学习并接收反馈以完善其策略。机器学习工作流程从数据收集,预处理,模型选择,培训,测试和评估开始。不同的算法专门从事不同的任务,并使用各种指标评估性能。高质量的数据和精心制作的功能对于提供有用的结果至关重要。机器学习算法提供了一系列解释选项,而其他人则需要其他计算资源。选择取决于所需的问题,数据类型和准确性。通常使用的算法包括线性回归,决策树,支持向量机,K-Nearest邻居,随机森林和神经网络。线性回归通过找到描述输入变量与输出变量之间关系的最佳拟合线来预测数值。决策树是基于是/否问题的直观模型,导致决定。支持向量计算机在数据集中找到最佳的边界。k-nearest邻居根据最接近的邻居的多数类对新数据点进行分类。随机森林结合了多个决策树的输出,或选择大多数投票进行分类和回归。幼稚的贝叶斯假定所有特征都是独立的,并应用了贝叶斯定理以基于概率的分类。神经网络处理像人脑一样的数据,分析大型数据集中的模式。机器学习算法提供可扩展性,自动化,通过数据驱动的见解增强的决策以及解决复杂问题的潜力。数据质量问题,例如培训数据中的不准确和偏见,可能会严重影响模型性能和可靠性。此外,过度拟合和不足的问题是常见问题,在这些问题中,模型变得过于专业或过于简单,导致预测不良。此外,机器学习引起了道德和隐私问题,尤其是在使用敏感的个人数据时。这包括偏见,公平,透明度和潜在的滥用。机器学习的现实应用在各个行业中都广泛。在医疗保健中,通过模式分析和个性化治疗计划,机器学习有助于早期疾病检测。财务将其用于实时安全系统和信用评分来确定借款人的信誉。电子商务平台利用机器学习用于推荐系统,库存管理和客户服务聊天机器人。自动驾驶汽车依靠深度学习模型进行传感器数据处理,而预测维护则在车辆性能数据分析中用于检测机械故障。机器学习在各个行业中都普遍存在,扩大了其影响力并引起人们对那些能够利用其潜力的人们的兴趣。为了从事这一领域的职业,锡拉丘兹大学的iSchool通过其应用数据分析计划(包括学士学位和未成年人)提供了理想的基础。另外,学生可以探索高级选项,例如人工智能或应用数据科学的硕士学位。这些计划提供了必要的知识,工具和动手经验,以做出有意义的贡献。尽管机器学习算法可以适应,但人类专业知识对于指导其发展是必不可少的。