XiaoMi-AI文件搜索系统
World File Search Systemkubernetes
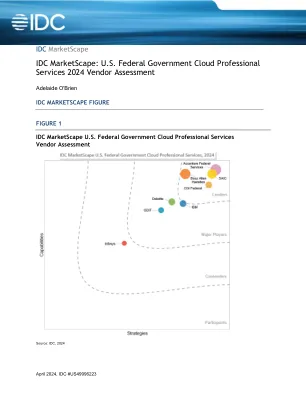
IDC MarketScape:美国联邦政府云专业服务 2024 年供应商评估
云支持冗余、有保障的工作负载、灾难恢复和业务连续性,因为云是始终可用于支持关键服务的数字基础设施。随着云计算环境的扩展和变得更加多样化,联邦机构面临着多种架构、开发和部署决策,以及越来越多的云服务、产品和选项——例如,最佳的应用程序部署选择是什么(本地、异地)、架构设计(单片、宏服务、微服务)和技术基础(虚拟机、基础设施即服务 [IaaS]、平台即服务 [PaaS]、无服务器/功能即服务、Kubernetes 编排系统)。为了制定明智的策略来理解、预测、合理化和优化主要的云架构决策,机构通常会部署提供云专业服务的供应商。

Jacques Serizay
数据分析机器学习标准,深度学习,SQL [SQLITE3,MySQL],交互式仪表板[Shinny,dash]•适应并优化了解决生物学问题的机器学习方法。•实施云代理框架以存储,操纵和分析高维数据集。•开发定制数据分析管道以简化生物学发现和假设检验。•交互式仪表板的全堆放开发可视化复杂的多态数据集,以进行实时数据探索。数据管理CI/CD [NextFlow,Makefile,Snakemake,GitHub动作],容器化[Docker,Singularity,Kubernetes]•实现CI/CD程序以自动化工作流程,确保可重复性和可伸缩性。•领导计划,以增强数据版本和工作流程自动化,从而改善跨学科团队的协作。

Azure AI 和高级分析功能
UST 经验丰富的数据科学家、AI 工程师和机器学习开发人员为您的组织提供最佳实践,并帮助您快速掌握最新的 Microsoft Azure 机器学习功能 - 快速轻松地构建、训练和部署机器学习模型。他们的专业知识可帮助您利用尖端技术,如自动化机器学习、Fairlearn、Jupyter、Visual Studio Code 框架(如 PyTorch Enterprise、TensorFlow 和 Scikit-learn)。借助自动化机器学习和拖放界面等低代码和无代码工具,您可以扩展数据科学团队并更快地生成模型。此外,使用 ONNX Runtime,您可以使用 Azure Kubernetes 服务 (AKS) 轻松大规模部署并最大化机器学习推理。

flautim:使用K8和Flower的联合学习平台
联合学习(FL)是人工智能中的最先进技术,可在降低计算和通信成本的同时,保留数据隐私和安全性。它改变了传统的集中机器学习和深度学习方法,以实现无需数据交换的分散模型培训。这项工作介绍了FLAUTIM,这是基于Kubernetes(K8S)和Flower Framework的巴西和拉丁美洲的FL平台的首次实施。FLAUTIM专为学术使用而设计,使没有技术背景的研究人员可以轻松地在该平台上进行FL实验。此外,该平台允许开发涉及从连接车辆收集的数据的应用程序。因此,本研究旨在介绍这个新的FL平台,从而提供其架构的全面细节。

安全的云存储变得容易。
veeam®是数据保护和勒索软件恢复领域排名第一的全球市场领导者,它的使命是使每个组织能够从数据中断或损失中反弹,而是向前反弹。使用Veeam,组织通过数据安全性,数据恢复和混合云的数据自由来实现根本的弹性。Veeam数据平台为云,虚拟,物理,SaaS和Kubernetes环境提供了一个解决方案,使其和安全领导者放心,他们的应用程序和数据受到保护并始终可用。总部位于华盛顿的西雅图,在30多个国家 /地区设有办事处,可保护全球550,000多个客户,其中包括2000年全球2000年的68%,他们相信Veeam可以保持其业务运行。根本的弹性始于Veeam。在www.veeam.com上了解更多信息,或在LinkedIn @veeam-software和x @veeam上关注Veeam。

人工智能在Web开发中的集成
交通部门提供的信息。这些数据包括列车时刻表、出发和到达时间、延误和其他相关信息。B. 所采用的人工智能技术和工具在拟议的列车调度系统的开发中采用了多种人工智能技术和工具。这些包括:用于列车时刻表预测分析和异常检测的机器学习算法。用于理解用户查询和反馈的自然语言处理 (NLP) 技术。用于根据历史使用数据个性化用户体验的推荐系统。用于系统组件可扩展性和模块化的微服务架构。使用 Docker 进行容器化,以简化跨不同环境的部署。用于管理和自动化微服务的部署、扩展和监控的编排工具(如 Kubernetes)。C. 系统设计和架构概述
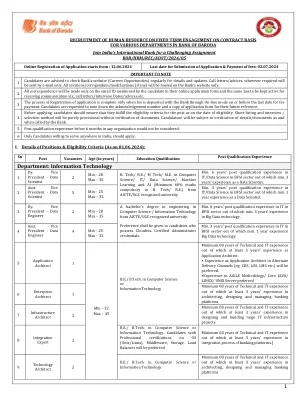
1个部门:信息技术
• 至少 3 年行业工作经验者优先考虑 • 深入了解数据库结构原理。 • 了解数据挖掘和分割技术,精通 SQL 和 Oracle。 • 熟悉数据可视化和数据导向。 • 能够记录复杂的业务流程并处理所有类型的客户请求。 • 良好的英语沟通能力;数学和统计分析,能够解释和整理相关数据。 • 应具有处理大型和多样化数据集的本地和基于云的数据基础设施的工作经验 • 优先考虑具有以下一种或多种技术经验的人 • AWS/GCP/Azure • Kubernetes/Docker Swarm • Apache Hadoop 和 Apache Spark • Elastic Stack/Elk • Airflow / Prefect • MongoDB、Cassandra、Redis、Memcached 和 DynamoDB • MySQL、Cassandra 和 Oracle SQL • PowerBI/Tableau/Qlik 视图

人工智能的未来是混合的
4.2 软件和模型效率 Qualcomm AI Stack 旨在帮助开发者只需编写一次,即可在我们的硬件上随处运行 AI 负载。Qualcomm AI Stack 从上到下支持 TensorFlow、PyTorch、ONNX 和 Keras 等热门 AI 框架,以及 TensorFlow Lite、TensorFlow Lite Micro、ONNX 运行时等运行时。此外,它还包括推理软件开发工具包 (SDK),例如我们广受欢迎的 Qualcomm® 神经处理 SDK,提供 Android、Linux 和 Windows 版本。我们的开发者库和服务支持最新的编程语言、虚拟平台和编译器。在较低层次上,我们的系统软件包括基本的实时操作系统 (RTOS)、系统接口和驱动程序。我们还在不同的产品线中提供丰富的操作系统支持,包括 Android、Windows、Linux 和 QNX,以及 Prometheus、Kubernetes 和 Docker 等部署和监控基础设施。

AI-602 - 大语言模型系统
课程描述本课程为人工智能(AI)开发提供了实用的,以行业为中心的旅程,从基础概念到为现实世界应用部署大型语言模型(LLM)。学生将通过自然语言处理和多模式AI进行动手实验室和案例研究,探索必不可少的AI生命周期阶段,包括业务问题,AI解决方案配方,模型培训,部署和评估。强调框架和工具,例如Docker,Kubernetes和MLOPS实践,该课程使学生准备设计可扩展的AI解决方案,同时解决道德考虑并优化模型性能。在课程结束时,学生将对AI系统体系结构,LLM的实践经验和职业准备技能有全面的了解,最终在一个顶峰项目中表明了他们创建与业务目标一致的影响力AI解决方案的能力。
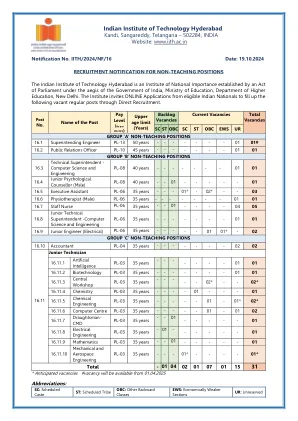
印度理工学院海得拉巴分校
其雇主核实其职位、服务年限以及角色和职责。期望: (i) 获得 LPI/Red Hat/Oracle/AWS 的 Linux/Unix 系统管理/架构认证。 (ii) 具有使用云和工作负载管理平台(如 OpenStack、Docker、Kubernetes、SLURM 和虚拟化技术(如 KVM))的经验 (iii) 熟悉基础设施即代码 (IaC) 工具,如 Terraform、Ansible、Puppet 或 Chef。 (iv) 熟练使用 Bash shell/Python 和自动化框架的脚本。 (v) 了解存储技术,如 SAN、NAS、对象存储和分布式文件系统(如 Ceph 或 GlusterFS)。 (vi) 具有使用监控和日志记录工具(例如 Prometheus、Grafana、Nagios)和中央日志记录系统(例如 ELK Stack)的经验 (vii) 了解网络概念和技术(例如 SDN、VPN、负载平衡)。 (viii) 具有安全最佳实践和工具方面的经验