XiaoMi-AI文件搜索系统
World File Search Systemnearest

双线性和最近邻的比较分析
像素转换在图像处理中至关重要,很大程度上取决于插值方法来确保平滑度和清晰度。这项工作重点关注两种广泛使用的图像插值技术:最近邻插值和双线性插值,这两种技术都是使用集成软件代码实现的。我们的方法使每种插值技术都可以独立应用,从而可以直接比较它们的性能。为了对每种插值方法进行全面评估,我们使用了一组基本质量评估指标:峰值信噪比 (PSNR)、结构相似性指数 (SSIM)、灰度分析和均方误差 (MSE)。选择这些指标是为了对图像清晰度、结构准确性和整体视觉质量进行平衡评估。本研究的结果对每种插值技术的优势和局限性进行了详细分析。这些发现旨在帮助研究人员和从业者根据他们在图像处理领域的特定要求选择最合适的插值方法。通过提供比较框架,这项工作通过增强评估和优化数字成像应用中的图像质量的方法来为该领域做出贡献。

探索银河系最近的目的地
由于时间通常是此类问题中唯一的独立变量,我们必须制定策略来发现适宜居住的地方并利用地外能源。这一目的回顾了太空探索在第二代生物燃料、聚变、生物特征、技术特征、原子丰度曲线、核合成(即燃烧 H、He、C、Ne、O、Si、Fe)等领域的研究问题。从氢进行氦、氧和氖的核合成,以及从捕获过剩的大气碳和甲烷进行铁的核合成,可以为太空探索提供宝贵的物质资源并促进技术科学知识。无论如何,聚变与其他有效手段相结合,是星际旅行的一个有前途的技术项目,而从这个角度来看,控制核扩散的伦理问题也必须得到解决。因此,功利主义应该得到责任和组合学的帮助。

在有符号累积函数中进行最近子空间搜索...
本文提出了一种使用有符号累积分布变换 (SCDT) 对一维信号进行分类的新方法。所提出的方法利用 SCDT 的某些线性化特性,使问题在 SCDT 空间中更容易解决。该方法使用 SCDT 域中的最近子空间搜索技术来提供一种非迭代、有效且易于实现的分类算法。实验表明,所提出的技术在使用极少量训练样本的情况下优于最先进的神经网络,并且对模拟数据上的分布外示例也具有鲁棒性。我们还通过将所提出的技术应用于 ECG 分类问题来证明其在实际应用中的有效性。实现所提出的分类器的 Python 代码可以在 PyTransKit [1] 中找到。

囚禁离子量子计算机上的最近质心分类
近年来,量子机器学习在理论和实践方面取得了长足的发展,已成为量子计算机在现实世界中应用的有希望的领域。为了实现这一目标,我们结合了最先进的算法和量子硬件,为量子机器学习应用提供了实验演示,并可证明其性能和效率。具体来说,我们设计了一个量子最近质心分类器,使用将经典数据高效加载到量子态并执行距离估计的技术,并在 11 量子比特离子阱量子机上进行了实验演示,其准确度与经典最近质心分类器的准确度相当,可用于 MNIST 手写数字数据集,并可实现 8 维合成数据的准确度高达 100%。

皮肤类型分析通过计算机视觉和最近的邻居
这个提出的计算机视觉系统是一种创新的解决方案,可以帮助在皮肤病学诊断和个性化护肤方面革命性。在使用最新的图像分析技术时,该系统拾取了与皮肤类型,色调以及其他皮肤问题有关的基本属性,例如痤疮,色素沉着甚至细纹。这可以通过在HSV和YCBCR颜色空间中进行转换来精确确定皮肤,从而精确地确定皮肤,无论是否有任何照明或环境条件,都可以精确地确定皮肤的细分。Fitzpatrick肤色分类与K-最近的邻居(KNN)一起使用,以在音调上有很大的差异,因此具有包含和准确的结果。它通过使用一式式编码和余弦相似性来映射针对策划产品数据库的独特皮肤配置文件,从而为用户提供可行的见解。它被放置在一个基于网络的平稳平台中,该平台将允许实时视频和电子商务集成,为不同的方法集创建友好且易于访问的体验。

利用预训练模型进行最近邻药物靶标亲和力预测
药物-靶标结合亲和力 (DTA) 预测对于药物发现至关重要。尽管将深度学习方法应用于 DTA 预测,但所获得的准确度仍然不理想。在这项工作中,受到最近检索方法成功的启发,我们提出了 𝑘 NN-DTA,这是一种基于非参数嵌入的检索方法,采用预先训练的 DTA 预测模型,它可以扩展 DTA 模型的功能,而无需或几乎不需要任何成本。与现有方法不同,我们从嵌入空间和标签空间引入了两种邻居聚合方法,并将它们集成到一个统一的框架中。具体而言,我们提出了一种具有成对检索的标签聚合和一种具有逐点检索最近邻居的表示聚合。该方法在推理阶段执行,并且可以在无需训练成本的情况下有效提高 DTA 预测性能。此外,我们提出了一个扩展,Ada-𝑘 NN-DTA,一种具有轻量级学习的实例化和自适应聚合。在四个基准数据集上的结果

CXL-ANNS:软硬件协作内存分解和十亿级近似最近邻搜索计算
摘要 我们提出了 CXL-ANNS,这是一种软硬件协作方法,可实现高度可扩展的近似最近邻搜索 (ANNS) 服务。为此,我们首先通过计算快速链路 (CXL) 将 DRAM 从主机中分离出来,并将所有必要的数据集放入其内存池中。虽然这个 CXL 内存池可以使 ANNS 能够在不损失准确性的情况下处理十亿点图,但我们观察到由于 CXL 的远内存类特性,搜索性能会显著下降。为了解决这个问题,CXL-ANNS 考虑节点级关系并将预计访问最频繁的邻居缓存在本地内存中。对于未缓存的节点,CXL-ANNS 通过了解 ANNS 的图遍历行为预取一组最有可能很快访问的节点。CXL-ANNS 还了解 CXL 互连网络的架构,并让其中的不同硬件组件并行协作搜索最近邻居。为了进一步提高性能,它放宽了邻居搜索任务的执行依赖性,并通过充分利用 CXL 网络中的所有硬件来最大化搜索并行度。我们的实证评估结果表明,与我们测试的最先进的 ANNS 平台相比,CXL-ANNS 的 QPS 提高了 111.1 倍,查询延迟降低了 93.3%。在延迟和吞吐量方面,CXL-ANNS 也分别比仅具有 DRAM(具有无限存储容量)的 Oracle ANNS 系统高出 68.0% 和 3.8 倍。

使用 UCI 机器学习糖尿病数据集上的 K 最近邻 (KNN) 方法预测糖尿病
3. 使用 K 最近邻 (KNN) 方法进行分析 K 最近邻 (KNN) 是一种通过考虑现有属性和训练样本来对新对象进行分类的算法。分类不需要使用模型,而仅基于记忆。在该算法中,将在查询点中搜索若干个𝐾个最近的训练点,并根据这些𝐾点中的大多数进行分类。 KNN 采用基于邻域的分类方法,通过计算查询实例到训练样本的最短距离来确定 KNN。 KNN算法对于预测新物体的分类非常简单而且有效。使用KNN方法的步骤如下:
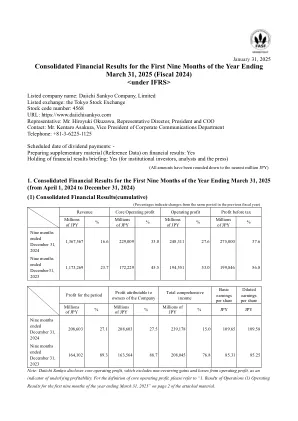
(所有金额都被四舍五入到最近的百万jpy)1。截至3月的前九个月合并财务业绩
1) Overview ....................................................................................................................................................2 [Consolidated Financial Results (Core Base)] ..................................................................................................2 [Revenue by Business Unit] ........................................................................................................................................................................................................................................................................................................................................................................................................................................................................................... Forecasts of Consolidated Financial Results and Other Forward-Looking Statements ......9 (4) Information about Return to Shareholders .....................................................................................................10 2.Condensed Interim Consolidated Financial Statements with Primary Notes ........................................................11

吉尔吉斯共和国的灾害风险融资的有利环境:国家诊断评估
Figures 1 Timeline and Area of Impact of Selected Disasters 2 2 Layered Approach to Disaster Risk Financing 5 3 W&W Insurance, Reinsurance, and Capital Markets Solutions 9 Development Framework—Hypothetical Example 4 Exceedance Probability Curves for Flood and Earthquake Risk, 13 Kyrgyz Republic 5 Ministry of Emergency Situations Organization Structure 19 6 Gross Domestic Product Growth, 2021–2024 25 7 Hospital Beds per 100,000/Population Ratio, 2019 or Nearest Available Year 26 8 Physicians per 100,000/Population Ratio, 2019 or Nearest Available Year 26 9 Nurses per 100,000/Population Ratio, 2019 or Nearest Available Year 27 10 Health Expenditure in the Kyrgyz Republic, 2019 38 11 Satellite Optical Image of Irrigated Maize Fields 48 12 Photo of Maize Fields Taken by Drone Showing Problem Areas of the Fields 49 13 Satellite Image Showing Problem Zones in a Vineyard 49 14 Kyrgyz Stock Exchange交易量,2001–2022 53 15吉尔吉斯共和国的评级结果58