XiaoMi-AI文件搜索系统
World File Search System为时已晚

在为时已晚之前规范人工智能大型语言模型,是吗......
10 Cobbe 和 Singh 的论文旨在将基础模型与 LLM 进行比较。他们解释说,“考虑到对数据、专业知识和计算能力的需求,内部机器学习可能会令人望而却步。通过让开发人员能够以低成本、无需大量投入的方式将最先进的 ML 功能‘插入’到他们的应用程序中,AIaaS 增加了 ML 支撑更广泛应用程序的可能性”。 Jennifer Cobbe 和 Jatinder Singh,“人工智能即服务:法律责任、义务和政策挑战” [2021] 计算机法律与安全评论 < https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3824736> 访问日期:2021 年 9 月 19 日 11 Bommasani 等人 (n 8) 3. 12 例如,如果基础模型在有毒数据上进行训练,那么建立在它们之上的所有下游应用程序都会因此受到“污染”。 13 Emily M. Bender 和 Alexander Koller,《攀登自然语言理解:数据时代的意义、形式和理解》(计算语言学协会 2020 年)< https://aclanthology.org/2020.acl-main.463/ > 于 2021 年 9 月 15 日访问 14 Samoili 等人(注 5)
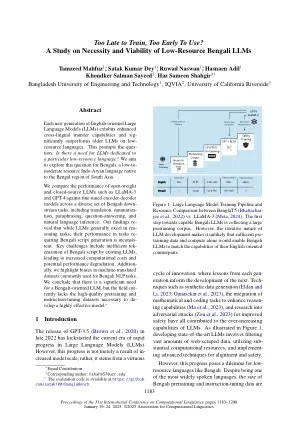
为时已晚,无法使用太早使用?低资源孟加拉语LLMS
我们比较了开放量和封闭式LLM的性能,例如Llama-3和GPT-4与跨孟加拉语下流任务的微调编码器模型,包括翻译,摘要,汇总,释义,问答,提示和自然语言的推流。我们的发现表明,尽管LLM通常在执行任务方面表现出色,但它们在重新制定孟加拉语脚本生成的任务中的表现却是不明智的。关键挑战包括现有LLM对孟加拉脚本的效率低下,从而导致计算成本增加和潜在的性能退化。加法 - 我们重点介绍了通常用于孟加拉NLP任务的机器翻译数据集中的偏差。我们得出的结论是,孟加拉国面向的LLM非常需要,但是该领域通常缺乏为降低一个高效模型所需的高质量预科和指导调整数据集。*



强大的国家、有韧性的社会和...
4 Alar Karis,‘爱沙尼亚总统:北约必须在为时已晚之前加强其东翼’,《金融时报》,2022 年 3 月 28 日 5 Mark Milley,‘米利提议在东欧各地的永久基地轮换部队’,Defense.gov

Michael W. Killen
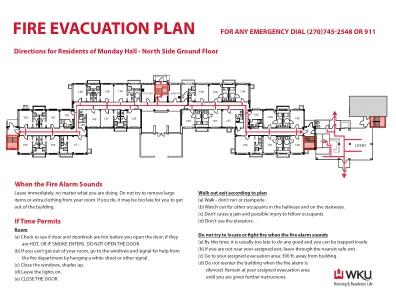
不要试图找到或发现何时发出警报的声音(a)此时,做任何好事通常为时已晚,您可能会被困在里面。(b)如果您不在分配的出口附近,请通过最近的安全出口离开。(c)转到您指定的撤离区域:距建筑物300英尺(d)距离建筑物(d)保持沉默时,请勿重新进入建筑物。保留在您指定的疏散区域,直到您得到进一步的说明为止。

装配厂还是电池供电?
这留下了关税。可以以不会引起贸易战争的方式进行更高的关税。许多中国球员已经在计划投资到欧洲。与以前的贸易纠纷类似,可以找到一个友好的解决方案。这可以包括较低的关税至一定数量的进口(例如,以商定的最低价格占市场的10-15%),此后提高了较高的关税。 为了为当地电池电池制造创造一种吸引力,到2027年,欧洲将需要将关税提高到至少20%,以缩小与中国的平均成本差距(可能是调查应该研究的更多)。 与太阳能不同,欧洲应该在为时已晚之前先进行先发制人的行动。 这应该伴随着公共招标,补贴以及向电动汽车和电池制造商提供的公共补贴以及欧盟赠款和贷款的“欧盟制造”要求。以商定的最低价格占市场的10-15%),此后提高了较高的关税。为了为当地电池电池制造创造一种吸引力,到2027年,欧洲将需要将关税提高到至少20%,以缩小与中国的平均成本差距(可能是调查应该研究的更多)。与太阳能不同,欧洲应该在为时已晚之前先进行先发制人的行动。这应该伴随着公共招标,补贴以及向电动汽车和电池制造商提供的公共补贴以及欧盟赠款和贷款的“欧盟制造”要求。

重新定义寿命,寿命和退休
2025年1月1日,标志着新一代的开始 - 代代beta。这个拐点为思考这一全新一代的未来生活提供了一个有趣的机会。他们的家庭,医疗保健,教育和工作生活将是什么样的?今天我们该怎么做才能确保这些年轻人将来有更好的生活?无数的研究表明,人们倾向于为退休计划为时已晚。如果我们现在开始思考2025年出生的人的退休生活会是什么样?为了回答这些问题,审慎性进行了一项全面的研究,旨在了解下一代的生活可能是什么样的生活 - 可能性,机会和他们可能面临的挑战。而“生成beta”是
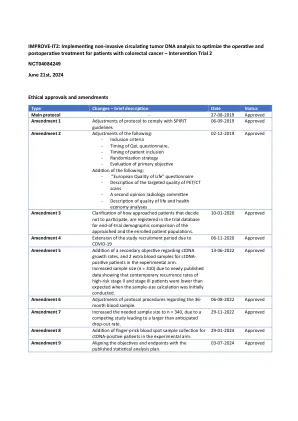
REVIT-IT2:实施非侵入性循环肿瘤DNA分析,以优化Colorect
内发生转移最常见于肝脏和肺部,如果以治愈性为例,则5年的相对存活率约为50-60%。2–5但是,如果检测到预期治疗的转移量为时已晚,而患者接受姑息化疗或最佳支持,那么5年后,少于10%的人还活着。 2–4,6–8切除和切除后的存活能力受到增加的转移部位和转移大小的负面影响。 2,3,5因此,当肿瘤负担低的时候早期发现复发是至关重要的,不仅是为了提高治愈性切除率,而且还可以增加切除后的生存率。 转移的局部治疗(例如 射频消融)很小,但在不符合大手术的患者中不可切除或可能可切除,其生存率高达40-60%。 9–12这意味着,也认为被认为没有符合治疗切除的患者可能会受益于早期复发检测。2–5但是,如果检测到预期治疗的转移量为时已晚,而患者接受姑息化疗或最佳支持,那么5年后,少于10%的人还活着。2–4,6–8切除和切除后的存活能力受到增加的转移部位和转移大小的负面影响。2,3,5因此,当肿瘤负担低的时候早期发现复发是至关重要的,不仅是为了提高治愈性切除率,而且还可以增加切除后的生存率。转移的局部治疗(例如射频消融)很小,但在不符合大手术的患者中不可切除或可能可切除,其生存率高达40-60%。9–12这意味着,也认为被认为没有符合治疗切除的患者可能会受益于早期复发检测。