XiaoMi-AI文件搜索系统
World File Search System主成分

2000 年至 2020 年医学人工智能出版物的趋势:放射学处于什么位置?
使用 PubMed 数据库进行出版物搜索。从 2000 年到 2020 年,所有与人工智能 (AI) 相关的出版物都使用以下 MeSH 术语进行选择:人工智能、神经网络、机器学习、深度学习、支持向量机、贝叶斯分析、聚类分析和主成分分析。通过将 MesH 术语与专业名称相结合来选择特定专业的人工智能研究。从 ERAS 专业列表中选择了 23 个专业关系。对于具有替代英式拼写的专业查询(例如儿科和骨科手术)进行了特别考虑,并区分了“儿科”和“内科/儿科”。排除了会产生重叠结果的搜索字符串,例如查询“医学 AND (儿科 OR 儿科)”的医学儿科。
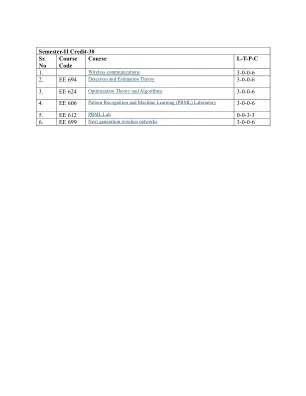
学期-II Credit-30 Sr.没有课程代码课程LTPC 1。
概率理论的概述,线性代数,凸优化。简介:模式识别和机器学习的历史,模式识别和机器学习重点的区别。回归:线性回归,多元回归,逻辑回归。聚类:分区聚类,分层聚类,桦木算法治疗算法,基于密度的基于密度的聚类PCA和LDA:主成分分析,线性判别分析。内核方法:支持向量机图形模型:高斯混合模型和隐藏的马尔可夫模型贝叶斯方法的简介:贝叶斯分类,贝叶斯学习,贝叶斯最佳分类器,天真的贝叶斯分类器和贝叶斯网络..

人工智能对仓库绩效的影响
摘要 :本研究重点关注人工智能对仓库绩效的影响。本研究以选定仓库的 329 名工人为样本,使用自填问卷收集数据。使用主成分分析 (PCA) 方法构建指数以衡量对仓库绩效的影响。使用 Mann Whitney U 检验和 Kruskal-Wallis H 检验用于确定人口统计因素对仓库绩效的影响。通过相关性分析确定变量之间的关联。进行回归分析以确定所确定的因素与仓库绩效之间的关系。当研究测试变量之间的关联时,它显示出正相关性。最后,基于分析,说明了机器学习、机器人、物联网 (IoT) 和模糊逻辑对仓库绩效的影响。仓库绩效分为三个类别:时间、库存和成本。
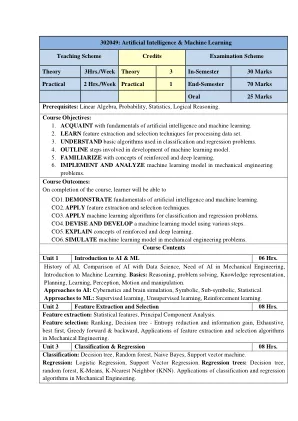
302049:人工智能与机器学习
单元1 AI和ML 06小时的简介。AI的历史,AI与数据科学的比较,机械工程中的AI需要,机器学习简介。 基础:推理,解决问题,知识表示,计划,学习,感知,运动和操纵。 AI的方法:控制论和脑模拟,符号,亚符号,统计。 ML的方法:监督学习,无监督的学习,强化学习。 单元2特征提取和选择08小时。 特征提取:统计特征,主成分分析。 功能选择:排名,决策树 - 熵减少和信息增益,详尽,最佳,贪婪的前向和向后,功能提取的应用和选择算法在机械工程中。 单元3分类和回归08小时。 分类:决策树,随机森林,天真的贝叶斯,支撑向量机。 回归:逻辑回归,支持向量回归。 回归树:决策树,随机森林,K-均值,K-Nearest邻居(KNN)。 机械工程中分类和回归算法的应用。AI的历史,AI与数据科学的比较,机械工程中的AI需要,机器学习简介。基础:推理,解决问题,知识表示,计划,学习,感知,运动和操纵。AI的方法:控制论和脑模拟,符号,亚符号,统计。ML的方法:监督学习,无监督的学习,强化学习。单元2特征提取和选择08小时。特征提取:统计特征,主成分分析。功能选择:排名,决策树 - 熵减少和信息增益,详尽,最佳,贪婪的前向和向后,功能提取的应用和选择算法在机械工程中。单元3分类和回归08小时。分类:决策树,随机森林,天真的贝叶斯,支撑向量机。回归:逻辑回归,支持向量回归。回归树:决策树,随机森林,K-均值,K-Nearest邻居(KNN)。机械工程中分类和回归算法的应用。

超对称顶夸克事件分类的量子算法
寻找超对称粒子是大型强子对撞机 (LHC) 的主要目标之一。超对称顶部 (停止) 搜索在这方面发挥着非常重要的作用,但 LHC 下一个高光度阶段将达到前所未有的碰撞率,这对任何新信号与标准模型背景的分离提出了新的挑战。量子计算技术提供的大规模并行性可以为这个问题提供有效的解决方案。在本文中,我们展示了缩放量子退火机器学习方法的一种新应用,用于对停止信号与背景进行分类,并在量子退火机中实现它。我们表明,这种方法与使用主成分分析对数据进行预处理相结合,可以产生比传统多元方法更好的结果。

用于二次二进制优化的更快的量子和经典 SDP 近似
这一问题自然出现在各个科学学科的许多应用中,例如图像压缩 [ 52 ]、潜在语义索引 [ 36 ]、社区检测 [ 48 ]、相关性聚类 [ 17 , 46 ] 和结构化主成分分析,例如参见 [ 38 , 37 ] 及其参考文献。从数学上讲,MaxQP s ( 1 ) 与计算矩阵的 ∞→ 1 范数密切相关。反过来,该范数与割范数密切相关(将 x ∈ {± 1 } n 替换为 x ∈ { 0 , 1 } n ),因为这两个范数之间的差只能为一个常数因子。这些范数是理论计算机科学中的一个重要概念 [ 24 , 3 , 2 ],因为诸如识别图中最大割( MaxCut )之类的问题可以自然地表述为这些范数的实例。这种联系凸显了在最坏的情况下,(1)式的最优解是 NP 难计算的

鲁棒量子计算的自动生成与训练...
摘要 — 我们提出了一种新的混合系统,使用多目标遗传算法在灰度图像上自动生成和训练量子启发分类器。我们定义了一个动态适应度函数,以获得最小的电路和对看不见的数据的最高准确度,确保所提出的技术具有通用性和鲁棒性。我们通过惩罚它们的出现来最小化生成的电路在纠缠门数量方面的复杂性。我们使用两种降维方法来减小图像的大小:主成分分析 (PCA),它在个体中编码以进行优化,以及一个小型卷积自动编码器 (CAE)。将这两种方法相互比较并与经典的非线性方法进行比较,以了解它们的行为并确保分类能力归因于量子电路而不是用于降维的预处理技术。

细胞年龄对细胞外基质治疗结果的影响
图2 ICM年龄依赖性转录改变(a)基因表达数据的主成分分析(PCA),描述了年轻和老化ICM的群体关系。(b)ICMS的预选为58个心脏和衰老的特定基因的差异表达水平。(c – g)与CM行为不同特征的关键基因的热图:(c)肌膜,(d)钙(Ca2+)循环和核质网(SR),(e)离子通道,(F)ECM沉积和(G)应力响应。(h)统计上改变的ICM的基因表达。使用单向ANOVA进行了统计分析,并进行了HOC Tukey测试。*** <0.001,** p <0.01, *p <0.05,n = 6汇总为2个技术重复。数据表示为平均值±标准偏差(SD)。(i)显示kegg途径的蛋白质组。

评估生成扩散模型,以增强范围和全原子分辨率的折叠和无序蛋白质态采样
图2:基于扭转角的主成分分析(PCA),TRP型栅格和α-突触核蛋白的自由能表面(FES)。(a)和(d)分别沿TRP-CAGE和α-类核蛋白的整个分子动力学(MD)模拟数据集沿第一个两个主要成分(PC-1和PC-2)显示了2D FES图。(b)和(e)使用仿真数据的子集描绘了FES图,相当于TRP -cage的总数据的10%,而α-突触核蛋白的50%。与完整数据集相比,这些子集突出了采样自由能表面的稀疏性。(c)和(f)介绍了由DDPM训练的模型产生的FES图,这些模型在还原的子集上进行了训练。值得注意的是,DDPM生成的FES图与完整数据集的FES相似,并有效地采样了(b)和(e)中观察到的稀疏区域。

可再生能源的预先决定制定
本文提出了一种综合方法,用于以具有成本效益和实时方式使用存储设备来管理和稳定风能/太阳能农场的产出。我们考虑了可再生农场应确定电池收取或从可再生能源能力输出中具有随机且随时间变化的性质的电池中收取的能量的问题。我们的方法具有基于功能主成分分析的非侧重决策框架的无缝集成以及一个基于功能性主体组件分析的顺序非参数预测模型。我们算法的一个关键功能是,它可以在滚动范围内量化成本,在滚动范围内,随着新数据的获取,预测和决策都可以随时更新。我们的技术在加利福尼亚ISO数据集上进行了测试。案例研究提供了概念验证,既强调了我们前瞻性框架的好处又易于实施。