XiaoMi-AI文件搜索系统
World File Search System图像细节
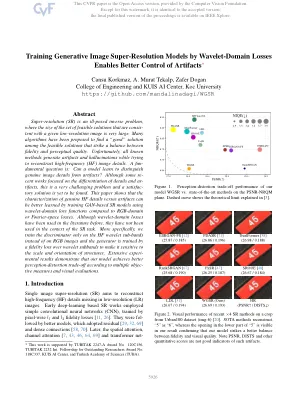
训练小波域损失的训练生成图像超分辨率模型可以更好地控制伪影
抽象的超分辨率(SR)是一个不当的反问题,其中具有给定低分辨率图像的可行解决方案集的大小非常大。已经提出了许多算法,以在可行的解决方案中找到一种“好”解决方案,这些解决方案在忠诚度和感知质量之间取得了平衡。不幸的是,所有已知方法都会生成伪影和幻觉,同时试图重建高频(HF)图像细节。一个有趣的问题是:模型可以学会将真实图像细节与文物区分开吗?尽管有些重点侧重于细节和影响的分化,但这是一个非常具有挑战性的问题,并且尚待找到满意的解决方案。本文表明,与RGB域或傅立叶空间损耗相比,使用小波域损失功能训练基于GAN的SR模型可以更好地学习真正的HF细节与伪像的表征。尽管以前在文献中已经使用了小波域损失,但在SR任务的背景下没有使用它们。更具体地说,我们仅在HF小波子带上而不是在RGB图像上训练鉴别器,并且发电机受到小波子带的忠诚度损失的训练,以使其对结构的规模和方向敏感。广泛的实验结果表明,我们的模型根据多种措施和视觉评估实现了更好的感知延续权权衡。

Lookout 的负责任开发
在应用程序开发过程中,Lookout 团队参与了多次人工智能原则评审,并进行了对抗性公平性测试。该团队采用了 Google DeepMind 视觉语言模型 (VLM),该模型针对此用例进行了高度定制,并得到了来自 BLV 人群以及跨性别和非二元性别者的多轮反馈。VLM 使人们能够就图像提出自然语言问题。新的 Lookout 问答功能允许用户超越字幕,询问对他们来说最重要的图像细节。此功能允许团队提供不带感知性别的字幕,但如果用户询问有关某人性别的问题,该模型可以使用来自该人外表的线索提供感知性别的最佳猜测。通过这种方式,Lookout 可以避免在不需要时提供性别描述,从而减少潜在的性别错误,但应用程序可以在用户认为这些信息对他们有用时提供这些信息。Lookout 团队对 BLV 和非二元性别的最终用户测试了这种方法,发现这些用户认为这种方法既有用又尊重。

利用太空图像进行矿产勘探
WorldView-3 于 2014 年发射,是一个由 DigitalGlobe(现为 Maxar Technologies)开发、Ball Aerospace & Technologies 建造的卫星星座。WorldView-3 遥感平台部分设计用于地质勘探。其单一全色 (pan) 光谱带用于快速收集高分辨率图像,这对于捕捉清晰的图像细节(30 厘米/12 英寸像素分辨率)特别有用。可见光和近红外 (VNIR) 系统收集八个高分辨率(1.2 米/4 英尺,1 英寸像素分辨率)多光谱带,主要用于铁矿物、稀土元素、植被健康以及沿海和土地利用应用。全色和 VNIR 系统由八个短波红外 (SWIR) 波段(3.7 米/12 英尺,2 英寸像素分辨率)补充,用于测量和绘制粘土矿物,以及一个称为 CAVIS(云、气溶胶、蒸汽、冰和雪)的大气传感器,该传感器带有另外 12 个光谱波段。CAVIS 波段可对图像进行非常精确的大气校正,以消除云、气溶胶、蒸汽、冰和雪的影响。

MEVO-GAN:用于水下图像增强的多尺度进化生成对抗网络
摘要:在水下成像中,实现高质量的成像是必不可少的,但由于诸如波长依赖性吸收和复杂的照明动力学之类的因素而具有挑战性。本文介绍了MEVO-GAN,这是一种新颖的方法,旨在通过将生成性对抗网络与遗传算法相结合来解决这些挑战。关键创新在于将遗传算法原理与生成对抗网络(GAN)中的多尺度发生器和鉴别器结构的整合。这种方法增强了图像细节和结构完整性,同时显着提高了训练稳定性。这种组合可以对溶液空间进行更有效的探索和优化,从而减少振荡,减轻模式崩溃以及对高质量生成结果的平滑收敛。通过以定量和定性的方式分析各种公共数据集,结果证实了Mevo-GAN在改善水下图像的清晰度,颜色保真度和细节准确性方面的有效性。在UIEB数据集上的实验结果非常明显,Mevo-GAN的峰值信噪比(PSNR)为21.2758,结构相似性指数(SSIM)为0.8662,为0.6597。

建立脑图像分析基础模型的方法
摘要。现有的用于脑图像分析的机器学习方法大多基于监督训练。它们需要大量的标记数据集,而这些数据集可能成本高昂甚至无法获得。此外,训练后的模型仅适用于标签定义的狭窄任务。在这项工作中,我们开发了一种基于基础模型概念的新方法来克服这些限制。我们的模型是一个基于注意力的神经网络,使用一种新颖的自监督方法进行训练。具体而言,该模型被训练以逐块方式生成脑图像,从而学习脑结构。为了便于学习图像细节,我们提出了一种新方法,该方法使用具有随机权重的卷积核对高频信息进行编码。我们在 10 个公共数据集上训练了我们的模型。然后,我们将该模型应用于五个独立的数据集,以执行分割、病变检测、去噪和脑年龄估计。结果表明,基础模型在所有任务上都取得了有竞争力或更好的结果,同时显著减少了所需的标记训练数据量。我们的方法能够利用大量未标记的神经影像数据集来有效地解决各种大脑图像分析任务,并减少获取标签的时间和成本要求。

额外的智能眼睛:人工智能在急诊放射学腹盆腔病变成像中的应用
摘要:紧急情况下的成像风险很高。随着对专用现场服务的需求增加,急诊放射科医生面临着越来越大的图像量,需要快速的周转时间。然而,新型人工智能 (AI) 算法可以帮助创伤和急诊放射科医生进行高效、准确的医学图像分析,从而有机会增强人类的决策能力,包括结果预测和治疗计划。虽然传统的放射学实践涉及对医学图像的视觉评估以检测和表征病理,但 AI 算法可以自动识别细微的疾病状态,并根据形态图像细节(例如几何形状和流体流动)提供疾病严重程度的定量表征。总的来说,在放射学中实施 AI 带来的好处有可能提高工作流程效率,为复杂病例带来更快的周转结果,并减少繁重的工作量。尽管腹盆腔成像中人工智能应用的分析主要集中在肿瘤检测、定位和治疗反应上,但已经开发出几种有前景的算法用于紧急情况。本文旨在对新兴图像任务中使用的人工智能算法建立一般理解,并讨论将人工智能实施到临床工作流程中所涉及的挑战。

基于高效深度网络模型的智能工厂机器视觉关键技术
现有的智能空间机器视觉技术大多面向具体应用,不利于知识共享和重用,大部分智能设备需要人参与控制,不能主动为人提供服务。针对以上问题,本研究提出基于深度网络模型的智能工厂,能够基于庞大的数据库进行数据挖掘和分析,使工厂具备自学习能力,在此基础上完成能耗优化、生产决策自动判断等任务。基于深度网络模型,提高了模型对图像分析的准确率。增加隐层数会导致神经网络出现误差,增加计算量,可根据模型特点选择合适的神经元个数。当IoU阈值取0.75时,其性能同比提升1.23%。由非对称多个卷积核组成的残差结构,不仅增加了特征提取层数,还可以让非对称图像细节得到更好的保留。训练好的深度网络模型识别准确率达到99.1%,远高于其他检测模型,其平均识别时间为0.175s。在机器视觉技术研究中,基于深度网络模型的智能工厂不仅保持了较高的识别准确率,还满足了系统的实时性要求。

基于序列到序列变压器结构
摘要:近年来,图像复制移动伪造(CMFD)的检测已成为验证数字图像的真实性的关键挑战,尤其是随着图像操纵技术的迅速发展。虽然深度卷积神经网络(DCNN)已被广泛用于CMFD任务,但它们通常受到一个显着限制的阻碍:编码过程中空间分辨率的逐步减少,这导致了关键图像细节的丢失。这些细节对于图像复制移动伪造的准确检测和定位至关重要。为了克服现有方法的局限性,本文提出了一种基于变压器的CMFD和本地化方法,作为传统DCNN技术的替代方法。所提出的方法采用变压器结构作为编码器来以序列到序列方式处理图像,用自我发项计算代替以前方法的特征相关计算。这使该模型可以捕获图像中的远程依赖性和上下文细微差别,从而保留了通常在基于DCNN的方法中丢失的更细节。此外,还利用了适当的解码器来确保图像特征的精确重建,从而提高了检测准确性和定位精度。实验结果表明,所提出的模型在USCISI等基准数据集上实现了出色的性能,用于图像复制移动伪造的检测。这些结果表明了变压器体系结构在推进图像伪造检测领域的潜力,并为未来的研究提供了有希望的方向。

应用数学和非线性科学
一位在唐朝的女士的照片对于以其精致的绘画技巧和丰富的文化价值研究古老的服装艺术已经至关重要。但是,由于时间的流逝,绘画中的服装细节受到严重损害,这给研究带来了挑战。本研究使用计算机辅助的数字恢复技术来重现女士服装的原始外观,并带有粉丝的女士。这项研究通过高精度扫描和图像处理,结合了历史文档和物理材料,通过高精度扫描和图像处理来实现唐朝女士服装的数字重建。在研究过程中,我们首先使用40百万像素的高分辨率扫描了“女士”,以确保图像细节的清晰度。之后,采用了基于深度学习的图像修复算法来处理绘画的损坏部分,并恢复了95%的服装区域。通过对唐纳(Tang Dynasty)的服装颜色进行统计分析,我们构建了一个包含120种典型颜色的数据库,该数据库中有120种典型的颜色,并基于此,我们对服装进行了颜色匹配和渲染。实验结果表明,修复的衣服的颜色饱和度增加了30%,模式清晰度达到98%。与唐朝的现有服装相比,恢复服装的样式准确率达到了90%。此外,我们还使用了三维建模技术在三个维度上恢复服装,其结构为85%,类似于文献中记录的Tang Dynasty服装。