XiaoMi-AI文件搜索系统
World File Search System均方根

从便携式脑电图耳机解码效价和唤醒的神经特征
近年来,使用脑电图 (EEG) 数据和机器学习技术进行情绪分类的现象日益增多。然而,过去的研究使用的是医疗级 EEG 设置的数据,这些设置时间较长,且环境受限。本文重点介绍使用各种特征提取、特征选择和机器学习技术在效价-唤醒平面上对情绪进行分类。我们评估了不同的特征提取和选择技术,并提出了用于情绪识别的最佳特征和电极集。OASIS 图像数据集中的图像用于引发效价和唤醒情绪,并使用 Emotiv Epoc X 移动 EEG 耳机记录 EEG 数据。分析是在公开可用的数据集上进行的:DEAP 和 DREAMER 用于基准测试。我们提出了一种新颖的特征排名技术和增量学习方法来分析性能对参与者数量的依赖性。进行了留一交叉验证,以识别情绪引发模式中的受试者偏见。计算了不同电极位置的重要性,可用于设计用于情绪识别的耳机。收集的数据集和管道也已发布。我们的研究在 DREAMER 上取得了 0.905 的均方根得分 (RMSE),在 DEAP 上取得了 1.902 的均方根得分 (RMSE),在我们的数据集上取得了 2.728 的价标签得分,在 DREAMER 上取得了 0.749 的得分,在 DEAP 上取得了 1.769 的得分,在我们提出的数据集上取得了 2.3 的唤醒标签得分。

LSTM 与Informer 融合预测冠层区域温度
摘 要: 针对传统温度预测方法难以充分捕捉多尺度信息,导致模型预测性能不佳等问题,该研究提出了一种基于 Informer 架构和长短时记忆网络( long short-term memory, LSTM )与多源数据融合的冠层区域温度预测模型。在编码层 中,采用稀疏注意力机制提取输入因子的多尺度信息及其与长时序数据之间的耦合关系;在解码层中,利用 LSTM 提取 短期时序依赖,以增强时间序列的连贯性,同时引入改进的反向残差前馈网络( improved residual feedforward network, IRFFN )以优化模型结构。首先采用孤立森林法对数据进行异常值清理,并进行了归一化处理;然后使用斯皮尔曼相关 系数法对冠层区域温度进行相关性分析,并选择相关程度较高的环境因子作为模型的输入特征;最终通过网格搜索法对 超参数进行优化,并通过迭代训练实现模型的最优配置。通过与其他 4 种主流算法进行对比分析,提出的 Informer- LSTM 在冠层区域温度预测方面表现出更高的精度,其平均绝对误差( mean absolute error, MAE )、均方根误差( root mean square error, RMSE )和决定系数( R 2 )分别达到了 0.166 、 0.224 ℃和 97.8% ,与基础模型 Informer 相比,冠层区 域温度的预测精度提高了 32.36% 。该模型在时间序列预测方面具有较高的精度,为区域气象温度的中短期精准预测提 供了一种新的技术方法。 关键词: 冠层 ; 温度 ; 非线性时间序列 ; 长短期记忆神经网络 ; Informer doi : 10.11975/j.issn.1002-6819.202409001 中图分类号: TP18 ; S165 文献标志码: A 文章编号: 1002-6819(2025)-07-0001-11

气候变化对未来小麦的影响(Triticum Aestivum ...
摘要:气候变化在未来的未来中对小麦生长构成了新的威胁。需要探索这些威胁,以确保可持续的小麦生产。为此,使用从不同水平的灌溉和氮剂量进行的实验的数据校准了盐模型。根据均方根误差(RMSE)的值,归一化的均方根误差(NRMSE),确定系数(r 2)和残留质量(CRM)系数评估盐模型的性能,范围为0.23-1.82,0.23-1.82,0.23-1.82,0.91-0.17,0.91-.17,0.91 - 0.93和0.01-0.93和0.01-01-2-2。 0.31–1.89,0.11–0.31,0.87–0.90和-0.02–0.01,分别用于验证。对未来气候生长的未来气候场景的预测表明,到本世纪末,在RCP4.5场景下,在RCP8.5场景下播种了九天,而在RCP8.5的场景下,播种日期,而收获日期则在RCP4.5和21岁以下的RCP8.5下播种。因此,在RCP4.5下,在RCP8.5的RCP4.5和十八天下,整个农作物持续时间缩短了15天。进一步的模拟显示,在RCP4.5下,小麦产量下降了14.2%,在RCP8.5下,小麦产量下降了14.2%。在RCP4.5下,干物质减少了14.9%,而RCP8.5下降了23.3%。在RCP4.5下,灌溉额预计将增加14.9%,在RCP8.5下增加18.0%;在RCP4.5下,水生产率预计将在RCP8.5下降低25.3%,直到世纪末。假设的情况表明,在RCP4.5下,增加氮多于额外的20–40%可以提高小麦产量和干物质10.2-23.0%和11.5–24.6%,分别为RCP8.5,分别为12.0–23.4%和12.9-23.4%和12.9-29.6%。这项研究提供了对气候变化对未来小麦生产的影响的宝贵见解,因此政策制定者可以制定有效的应急计划,并由利益相关者采用以提高小麦生产率。

使用改进的 WEEC 通用模型通过电池存储缓解光伏电源间歇性
摘要:光伏和风能系统等可再生能源越来越多地融入电网,这凸显了对可靠控制机制的需求,以缓解这些能源固有的间歇性。据巴西电网运营商 (ONS) 称,近年来可再生能源分布式系统 (RED) 出现了连锁断开现象,凸显了对稳健控制模型的需求。本文通过使用 WECC 通用模型验证光伏电站与电池储能系统 (BESS) 相结合的有功功率上升率控制 (PRRC) 函数来解决这一问题。所提出的模型在一段较长的分析期内经过了严格的验证,使用均方根误差 (RMSE) 和 R 平方 (R 2 ) 指标对连接点 (POI) 注入的有功功率、光伏有功功率和 BESS 充电状态 (SOC) 显示出良好的准确性,为中长期分析提供了宝贵的见解。爬升率控制模块在工厂功率控制器 (PPC) 中实现,利用西部电力协调委员会 (WECC) 开发的第二代可再生能源系统 (RES) 模型作为基础框架。我们使用 Anatem 软件进行了模拟,将结果与以 100 毫秒到 1000 毫秒为间隔从巴西配备 BESS 的光伏电站收集的实际数据进行了比较。所提出的模型经过了长期的严格验证,所呈现的结果基于两天的测量。用于表示此控制的正序模型表现出良好的准确性,这由均方根误差 (RMSE) 和 R 平方 (R 2 ) 等指标证实。此外,本文强调了在计算爬升率时准确考虑功率采样率的关键作用。
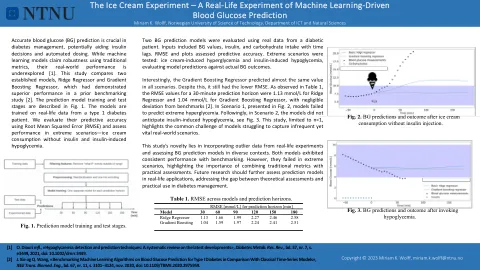
机器学习驱动的血液现实实验......
准确的血糖 (BG) 预测对糖尿病管理至关重要,可能有助于胰岛素决策和自动给药。虽然机器学习模型声称使用传统指标具有稳健性,但它们的实际性能尚未得到充分探索 [1]。本研究比较了两个成熟的模型,即 Ridge 回归和 Gradient Boosting 回归,这两个模型在之前的基准研究中表现出色 [2]。预测模型训练和测试阶段如图 1 所示。这些模型是根据 1 型糖尿病患者的真实数据进行训练的。我们使用均方根误差 (RMSE) 评估它们的预测准确性,并评估它们在极端情况下的性能——未注射胰岛素的冰淇淋消费和胰岛素引起的低血糖。
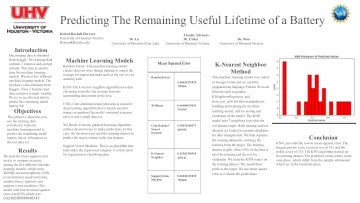
预测电池的剩余有用寿命
方法此机器学习模型是在Google Colab中编码的,我们使用了编程语言Python。我们使用诸如Pandas,KneighBorsRegressor和Train_test_split之类的库进行数据操纵,构建和培训机器学习模型,以及对模型的测试和验证。KNN模型使用7个邻居来预测测试数据集目标。将培训和测试数据集加载到熊猫数据框架上进行数据操作。然后,我们通过将功能与目标分离来分开训练数据集。培训数据集被拆分,其中80%的数据用于培训,其余数据用于验证。我们在培训数据集上训练KNN模型。然后该模型预测目标。我们使用均方根误差来评估预测。

衰老优化的收费控制多...
摘要:本文提出了一种方法,该方法可导致高度准确的电荷依赖性多阶段恒定电流(MCC)充电算法用于电动自行车电池,以减少充电时间,而不会通过避免使用Li-Plpling来加速老化。首先,通过三电极测量值对当前速率,最新电荷和Li-Plating之间的关系进行了实验分析。因此,提出了一种依赖社会的充电算法。其次,在MATLAB/SIMULINK中开发了基于扩展的Kalman滤波器的SOC估计算法,以进行高精度SOC估计并精确控制充电算法。实验的结果表明,SOC估计的均方根误差(RMSE)为1.08%,并且从0%到80%SOC的充电时间降低了30%。

EMRP-模板(文档)- EURAMET
数字计量是一个庞大且不断发展的领域,应用于从白色家电到精密医疗仪器和先进电子产品的所有工业领域。它现在是仪器仪表领域的首选方法,传感和测量越来越依赖于采样测量的模拟到数字转换。传感器的模拟电压或电流会尽快使用 ADC 转换为数字量。一旦电信号被数字化,诸如基本均方根 (RMS) 值、峰值、波峰因数和谐波含量等量都可以直接计算,而不需要每个量都需要特定的测量和校准。精密集成电路和测量设备的最新工业研究与开发带来了采样率和潜在精度的重大变化,然而,测量方法却未能跟上要求的步伐。

利用高性能数字隔离技术突破极限 (Rev. A)
增强隔离 增强隔离器是能够提供与两个串联基本隔离器等效绝缘的设备。增强隔离器本身被认为足以确保针对高压的电气安全。然而,增强隔离器必须满足日益严格的性能要求。电机驱动应用对增强隔离的要求最为严格,因为这些系统使用非常高的输入电源电压,并且涉及人类操作员可访问的接口。电机控制中的隔离要求在安全标准中定义。例如,IEC 61800-5-1 可调速驱动器的电气、热和能量安全标准。根据此标准,对增强隔离的要求随着系统电压的增加而增加,系统电压定义为输入电源线和地之间的均方根 (rms) 电压。

通过机器学习接近频道估计的MMSE界限
摘要 - 在无线通信系统中,该信号模型与高斯分布的通道和噪声线性线性,线性最小均方根误差(LMMSE)通道估计(CE)在均方误差(MSE)方面实现了最佳性能。但是,LMMSE CE取决于接收器可能无法使用的参数(例如,准确了解功率延迟profe(PDP))或过于复杂而无法实施实现(例如,LMMSE滤波器大小)。参数的次优选择可能会严重降低LMMSE CE性能。以这种观察的激励,我们研究了机器学习,作为重新填充和改善CE的工具。我们表明,我们提出的低复杂性学习辅助LMMSE CE可以克服次优参数的影响并接近理想的LMMSE性能。