XiaoMi-AI文件搜索系统
World File Search System孔上

R3干细胞注入程序TM*R3-Consumer-guide-Ibd炎症 - 孔孔。 ...R3-Consumer-guide-Ibd炎症 - 孔孔。 ...
更重要的是,服用这些药物可能导致各种不良反应。用皮质类固醇的使用证实与皮肤作用,体重增加,高血糖,骨质疏松症,肾上腺功能不全和白内障有关。此外,皮质类固醇治疗能够增加机会性感染的风险,尤其是与其他免疫抑制药物结合使用时。免疫调节剂产生的骨髓毒性和肝毒性的不耐受性或潜在发生可能使近四分之一的患者中断治疗。


地热的饱和湿孔孔仪表测试...
Egill Juliusson,以前是Landsvirkjun 1简介核和地热工业开始发布截至1950年代的饱和蒸汽流量研发。碳氢化合物生产行业在1990年代开始对湿天然气计量研发变得更加感兴趣。具有饱和蒸汽和湿天然气流是两相流量计量挑战,初始湿天然气流量计量研究包含现有的饱和蒸汽计量方法。但是,碳氢化合物行业的研发的随后方向与蒸汽行业的研发有所不同。碳氢化合物行业的两相测定开发并没有倾向于渗透回,或者至少没有被蒸汽行业采用。通常缺乏独立行业之间的沟通和思想转移。碳氢化合物生产行业已经开发了流量计量技术,如果只有知识转移,可能会使包括可再生能源领域在内的其他行业受益。


孔超导性
在1911年,Kamerlingh Onnes在实验中发现了某些称为“上跨导体”的金属,在过去[1] [1] [1] [2] [2]中发现了零电阻的状态。,如果在t> t c的超级导管的内部存在磁场,则当温度降低到t Meissner效应令人惊讶:在1933年之前,预计超导体会排除磁场,但不会排出磁场。 这是Fara-Day的定律,被称为“ Lippmann的定理” [4] [4] [5]:如果将磁场应用于零电阻材料中,则该材料将通过不让Eld渗透而产生的表面电流来反应,从而使磁场从其室内排除。 ,ever,法拉第定律 / lippmann的定理将预测,如果有限阻力的材料在其内部具有磁场,则将其冷却到零电阻的超导状态时,任何电流都不会流动,并且磁场将保持在内部,甚至在外部磁力源中,磁性磁性也可以恢复。 这不是超导体所做的:超导的金属自发产生一个表面电流,从而从其内部排出磁场[3]。 这似乎违反了法拉第定律。 BCS理论既没有基于电子 - 波相互作用,于1957年由Bardeen,Cooper和Schrieffer [7]提出。 对于其余三分之二,没有公认的理论。Meissner效应令人惊讶:在1933年之前,预计超导体会排除磁场,但不会排出磁场。这是Fara-Day的定律,被称为“ Lippmann的定理” [4] [4] [5]:如果将磁场应用于零电阻材料中,则该材料将通过不让Eld渗透而产生的表面电流来反应,从而使磁场从其室内排除。,ever,法拉第定律 / lippmann的定理将预测,如果有限阻力的材料在其内部具有磁场,则将其冷却到零电阻的超导状态时,任何电流都不会流动,并且磁场将保持在内部,甚至在外部磁力源中,磁性磁性也可以恢复。这不是超导体所做的:超导的金属自发产生一个表面电流,从而从其内部排出磁场[3]。这似乎违反了法拉第定律。BCS理论既没有基于电子 - 波相互作用,于1957年由Bardeen,Cooper和Schrieffer [7]提出。对于其余三分之二,没有公认的理论。伦敦兄弟[1,6]于1935年提出的伦敦方程式提供了对超导体的磁性行为的现象描述,但并未解释supoducducdors如何设法违反法拉第定律。bcs理论提供了超导体的显微镜描述,该描述准确地描述了其许多特性,通常认为它适用于称为“常规超导体”的材料,其中包括所有超导元件和许多化合物。大约有30种不同类别的超导材料[8],其中大约三分之一被同意为“常规超导体”。该领域是开放的,以进一步进步。


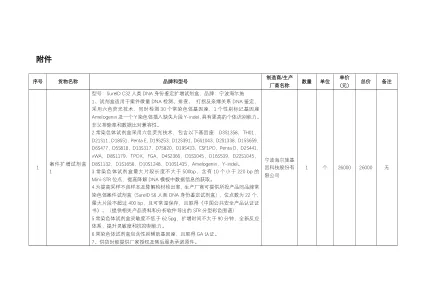


R3干细胞注入程序TM* R3-Consumer-guide-Ibd炎症 - 孔孔。 ...
更合理的使用单词可以促进,减轻或改进。这些材料中的生物学元素共同使用,以修复受损的组织,并促进自己的身体也有助于该过程。,由于人们独特而不同,取得了多少进步将会有所不同!在过去十年中,R3的中心在全球范围内进行了23,000多次干细胞手术。令人惊讶的是,我们的患者满意度一年一年度为85%。