XiaoMi-AI文件搜索系统
World File Search System并行执行

DTS0191 - 高分辨率电动偏振控制器
OZ Optics 方便且经济高效的电动旋转器能够精确控制单个光学平台或具有多个光路的多平台系统的偏振状态。这些旋转器可以通过单个紧凑型控制单元进行控制和同步,以按顺序或并行执行精确旋转。控制单元与处理器和触摸屏一起集成在一个手掌大小的外壳中,通过直观的图形用户界面 (GUI) 控制多个电机。无论系统复杂程度如何,都可以通过可定制的 GUI 实现和启用即插即用功能,以满足苛刻的应用要求。

高级科学计算研究(ASCR)
• 科学计算和实验会产生数以 TB 或 PB 计的数据,必须高效存储。• 该数据存储在 ASCR 计算设施的磁盘驱动器和存档系统集合中。• 与 ASCR 的计算能力一样,高性能数据管理需要并行执行许多操作。• ASCR 投资于创新方法来存储、压缩、搜索和分析数据,以最大限度地提高并行性和性能。• ASCR 还投资于流数据和联合学习的进步,使地理位置分散的数据能够为科学建模做出贡献,而无需将所有数据存储在一个地方。
猎鹰工程师绝不平庸
深度学习领域的高性能计算 | Mohsin M. Jamali 博士,电气工程,500,000 美元 这项研究探索了加快深度学习计算速度的途径。深度学习有两个计算阶段;第一阶段是学习或训练数据,第二阶段是算法计算。由于深度学习本质上是并行的,因此计算也可以并行执行。深度学习领域的高性能计算研究可分为三大类。第一类是并行计算算法,第二类是缩短内存访问时间,而第三类是策略性地缩短字长。我们的高性能计算实验室已从 NVIDIA 获得了 DGX 工作站,用于在 GPU 上进行计算,我们目前正在获取基于 FPGA 的开发系统。这项工作由德克萨斯大学系统 STARs 计划资助。

HXRHPPC处理器RAD硬处理器
微处理器描述HXRHPPC处理器集成了五个执行单元 - 一个整数单元(IU),浮点单元(FPU),分支处理单元(BPU),负载/存储单元(LSU)和系统寄存器单元(SRU)。并行执行五个指令的能力以及使用快速执行时间的简单指令产生高系统效率和吞吐量。大多数整数指令具有一个时钟周期的吞吐量。FPU是管道的,因此可以在每个时钟周期中发出单精确的多重ADD指令。处理器提供独立的片上,16个kbyte,四向设置缔合性,物理上的caches,用于指令和数据以及芯片指令和数据存储器管理单位(MMU)。它还通过使用两个独立指令和数据块地址

品牌:使用深网模型进行闭环实验的平台
抽象的人工神经网络(ANN)是用于建模和解码神经活动的最先进工具,但是将它们部署在具有严格的正时限制的闭环实验中,因为它们在现有的实时框架中的支持有限,因此具有挑战性。研究人员需要一个平台,该平台完全支持高级语言的运行ANN(例如Python和Julia),同时维持对低延迟数据获取和处理至关重要的语言的支持(例如C和C ++)。为了满足这些需求,我们介绍了实时异步神经解码(品牌)的后端。品牌包括Linux过程,称为节点,它们通过数据流在图中相互通信。其异步设计允许在可能在不同时间范围内运行的数据流并行执行,并可以在不同的时间范围内并行执行分析。品牌使用REDIS在节点之间发送数据,该节点可以实现快速的过程间通信并支持54种不同的编程语言。因此,开发人员可以轻松地将现有的ANN模型部署在品牌中,并具有最小的实施变化。在我们的测试中,在发送大量数据时,品牌在过程之间达到了<600微秒的潜伏期(在1毫秒块中的1024个频道30 kHz神经数据)。品牌运行一个带有复发性神经网络(RNN)解码器的大脑计算机界面,从神经数据输入到解码器预测,延迟的延迟少于8毫秒。该系统还支持使用动态系统(例如潜在因子分析)进行复杂的潜在变量模型的实时推断。在系统的真实展示中,Braingate2临床试验中的参与者T11执行了标准的光标控制任务,其中30 kHz信号处理,RNN解码,任务控制和图形均在品牌中执行。通过提供一个快速,模块化和语言敏捷的框架,品牌降低了将神经科学和机器学习中最新工具集成到闭环实验中的障碍。

分析依赖量表的生物多样性变化与MOBR
描述用于统计和机器学习的元包包,其统一界面用于模型拟合,预测,绩效评估和结果的呈现。用于模型拟合和预测数值,分类或审查的事件时间结果的方法包括传统的回归模型,正则化方法,基于树的方法,支持向量机,神经网络,合奏,数据预处理,滤清,滤波,过滤和模型调音和选择和选择。提供了用于模型评估的性能指标,并且可以通过独立的测试集,拆分抽样,交叉验证或引导程序重新采样来估算。重新样本估计可以并行执行以进行更快的处理,并在模型调整和选择的情况下嵌套。建模结果可以用描述性统计数据来汇总;校准曲线;可变重要性;部分依赖图;混淆矩阵;和ROC,LIFT和其他性能曲线。

自动形态合奏的极性代码解码器6G URLLC
根据作者克劳斯·凯斯特尔(Claus Kestel),马文·盖塞尔哈特(Marvin Geiselhart),卢卡斯·约翰逊(Lucas Johannsen),斯蒂芬·恩·布林克(Stephan Ten Brink)和诺伯特·韦恩(Norbert Wehn)的作者克劳斯·凯斯特尔(Claus Kestel)和诺伯特·韦恩(Norbert Wehn),的题为“ 6G urllc的自动化集合代码解码器”,这是即将到来的6G标准标准的urllc sereario。 实现接近ML的性能是具有挑战性的,尤其是对于短块长度。 极性代码是此应用程序的有前途的候选人。 上述论文讨论了连续的取消列表(SCL)解码算法,该算法提供了良好的误差校正性能,但在高计算解码的复杂性下。 本文引入了自动形态集合解码(AED)方法,该方法在并行执行了几种低复杂性解码。 本文介绍了AED架构,并将其与最先进的SCL解码器进行了比较。 因此,鉴于Kestel等人的理论和实验证明,我们在这里概述了由TLB GmbH管理的PCT应用保护的这项技术发明的位置和背景。的题为“ 6G urllc的自动化集合代码解码器”,这是即将到来的6G标准标准的urllc sereario。实现接近ML的性能是具有挑战性的,尤其是对于短块长度。极性代码是此应用程序的有前途的候选人。上述论文讨论了连续的取消列表(SCL)解码算法,该算法提供了良好的误差校正性能,但在高计算解码的复杂性下。本文引入了自动形态集合解码(AED)方法,该方法在并行执行了几种低复杂性解码。本文介绍了AED架构,并将其与最先进的SCL解码器进行了比较。因此,鉴于Kestel等人的理论和实验证明,我们在这里概述了由TLB GmbH管理的PCT应用保护的这项技术发明的位置和背景。

使用液滴微流体技术进行可扩展且自动化的基于 CRISPR 的菌株工程
摘要 我们提出了一种基于液滴的微流体系统,该系统可在芯片上实现基于 CRISPR 的基因编辑和高通量筛选。微流体装置包含一个 10 × 10 元件阵列,每个元件包含用于两个电场驱动操作的电极组:用于合并液滴以混合试剂的电润湿和用于转化的电穿孔。该装置可以并行执行多达 100 个基因改造反应,为生成遗传途径组合优化和可预测生物工程所需的大量工程菌株提供了一个可扩展的平台。我们通过基于 CRISPR 的两个测试案例的工程改造展示了该系统的能力:(1)破坏大肠杆菌中酶半乳糖激酶(galK)的功能;(2)靶向改造谷氨酰胺合成酶基因(glnA)和蓝色色素合成酶基因(bpsA),以提高大肠杆菌中的靛蓝素产量。
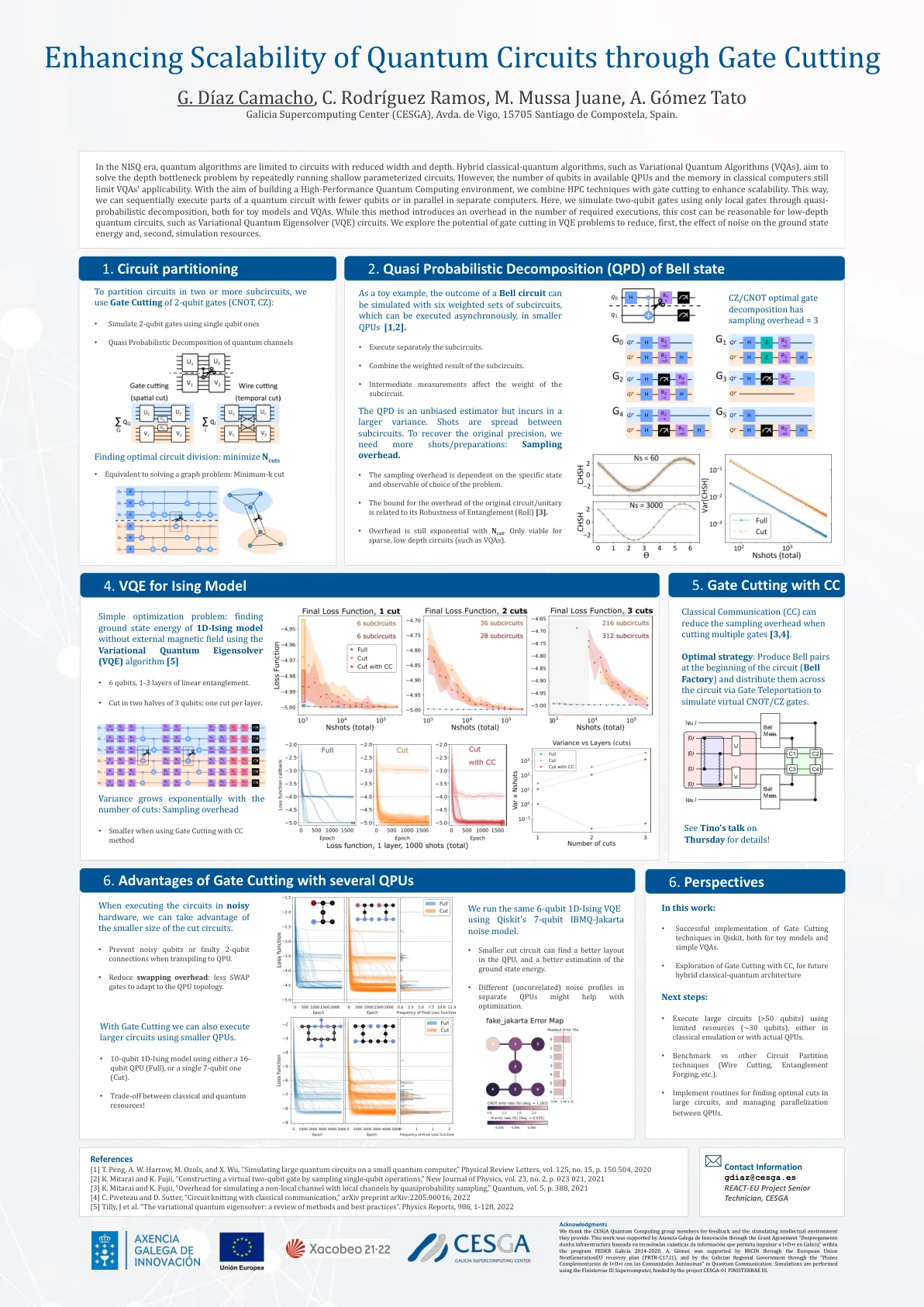
通过切割增强量子电路的可伸缩性
在NISQ时代,量子算法仅限于宽度和深度降低的电路。混合经典量子算法,例如变分量子算法(VQAS),旨在通过反复运行浅参数化电路来解决深度瓶颈问题。但是,可用QPU中的QPU和古典计算机中的内存数量仍然限制了VQAS的适用性。为了构建高性能量子计算环境,我们将HPC技术与门切割相结合以增强可扩展性。以这种方式,我们可以依次执行量子电路较少的量子电路的一部分,或在单独的计算机中并行执行。在这里,我们仅使用适用于玩具模型和VQA的准概率分解来模拟仅使用局部门模拟两倍的门。此方法引入了所需执行次数的开销,但对于低深度量子电路,例如变化量子eigensolver(VQE)电路可能是合理的。我们探讨了在VQE问题中切割门的潜力,首先是减少噪声对基态能量的影响,其次是仿真资源。

在世界各地开发和运送Covid-19-19
新疫苗通常需要十多年才能得到开发和批准。covid-19疫苗已经被批准用于紧急使用,并在通知WHO疾病的新疾病后大约八个月在国内注册。Covid-19疫苗的开发正在遵循“大流行范式”,即是一个压缩的时间框架,并在许多步骤中并行执行许多步骤。第一个候选疫苗在临床测试中仅在临床测试后仅两个月,这是SARS-COV-2的遗传序列,SARS-COV-2是导致COVID-19(自然)的病毒。增加发现和批准安全有效的疫苗的可能性,即使用“投资组合方法”,即投资多个候选疫苗进行测试。为了确保快速推出批准的疫苗,正在扩大制造能力,并在收到监管批准之前就开始生产。根据CEPI制造调查,于2020年8月发布,有能力在2021年底之前至少生产2-4亿剂的Covid-19-19(CEPI制造调查)