XiaoMi-AI文件搜索系统
World File Search System引出

我改进 | 我创新 | 数字化 - 业务分析
• 敏捷业务分析 – 迭代需求引出、故事阐述和管理 • 需求管理 – 业务、利益相关者和解决方案需求定义、可追溯性和生命周期管理 • 数字业务分析 – 个性化您的渠道交付以推动更好的客户连接 • 价值流和客户旅程 – 改善客户在交付您的产品和服务时的体验 • 流程改进 – 当前和未来状态流程设计、流程改进和自动化、与价值流和客户旅程相一致的服务数字化 • 数据分析和管理 – 数据治理、可视化、数据建模、报告设计和分析

定义可解释人工智能的心理模型方法
摘要背景:人们普遍担心在医疗保健等敏感环境中使用黑盒建模方法。尽管性能有所提升且备受炒作,但这些问题阻碍了人工智能 (AI) 的普及。人们认为可解释的人工智能有助于缓解这些担忧。但是,现有的可解释定义并未为这项工作奠定坚实的基础。方法:我们批评了最近关于以下文献的评论:团队中人工智能的代理;心理模型,尤其是它们应用于医疗保健时,以及它们引出的实际方面;以及现有和当前的可解释性定义,尤其是从人工智能研究人员的角度来看。在此文献的基础上,我们创建了可解释的新定义和支持术语,提供了可以客观评估的定义。最后,我们将可解释的新定义应用于三个现有模型,展示了它如何应用于先前的研究,并为基于此定义的未来研究提供指导。结果:现有的解释定义以全球适用性为前提,并未解决“谁可以理解?”的问题。如果将人工智能视为团队成员,那么引出心理模型可以比作创建可解释的人工智能。在此基础上,我们根据模型的背景来定义可解释性,包括模型和解释的目的、受众和语言。作为示例,此定义应用于手术室团队中的回归模型、神经网络和人类心理模型。结论:现有的解释定义在确保解决实际应用问题方面存在局限性。根据应用背景来定义可解释性会迫使评估与模型的实际目标保持一致。此外,它将允许研究人员明确区分针对技术受众和普通受众的解释,从而允许对每种解释应用不同的评估。关键词:可解释性、xAI、黑盒模型、心理模型
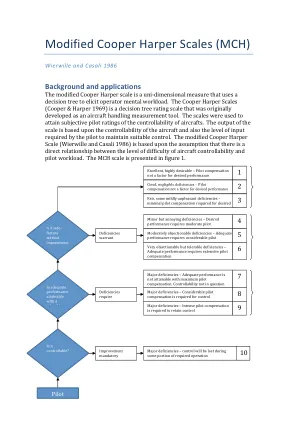
改良 Cooper Harper 量表 (MCH) - SKYbrary
背景和应用 改进的 Cooper Harper 量表是一种使用决策树来引出操作员心理工作负荷的单维测量方法。Cooper Harper 量表(Cooper & Harper 1969)是一种决策树评定量表,最初是作为飞机操纵测量工具开发的。该量表用于获得飞行员对飞机可控性的主观评级。量表的输出基于飞机的可控性以及飞行员保持适当控制所需的输入水平。改进的 Cooper Harper 量表(Wierwille 和 Casali 1986)基于以下假设:飞机可控性的难度水平与飞行员工作负荷之间存在直接关系。MCH 量表如图 1 所示。
改良 Cooper Harper 量表 (MCH) - SKYbrary
背景和应用 改进的 Cooper Harper 量表是一种使用决策树来引出操作员心理工作量的单维测量方法。Cooper Harper 量表(Cooper & Harper 1969)是一种决策树评级量表,最初是作为飞机操纵测量工具开发的。该量表用于获得飞行员对飞机可控性的主观评级。量表的输出基于飞机的可控性以及飞行员保持适当控制所需的输入水平。改进的 Cooper Harper 量表(Wierwille and Casali 1986)基于以下假设:飞机可控性的难度与飞行员工作量之间存在直接关系。MCH 量表如图 1 所示。

自主性和自主性指标 - 圣母大学
在整个历史中,对自主性的追求一直是人类文化中一个普遍的主题。本文提出并讨论了自主系统的一般定义,这自然会引出衡量系统自主性水平的指标的建立。该定义基于系统在不确定情况下实现目标的能力,并不涉及实现目标的手段,如传感和反馈。本文认为任何自主系统都是一个控制系统,为了实现更高水平的自主性,可能需要添加传统上在运筹学和人工智能等领域开发的方法。本文介绍的工作基于作者早期关于自主航天器功能架构的研究。

航空航天工程技术选修课程
描述各种架构框架(主要是 DODAF)。通过构建离散事件操作模型了解客户需求。使用操作模型引出系统外部和人机界面。导出系统状态和模式。开发可重复使用的功能系统架构并导出性能要求。定义实现功能并满足性能要求的物理系统架构。设计分析周期。相对于架构模型的交易研究定义。从操作、功能和物理系统模型推动安全评估。先决条件:[ARO 专业];[ARO 201L 或 ARO 2011L 成绩为 C 或更高]。

下一代:人工智能实验
我们通过确定关键领域、方向和含义,研究大型语言模型 (LLM) 在实验中增强科学实践的潜力。首先,我们讨论这些模型如何改进实验设计,包括改进引出措辞、编码实验和生成文档。其次,我们讨论使用 LLM 实施实验,重点是通过创建一致的体验、提高对指令的理解以及实时监控参与者的参与度来增强因果推理。第三,我们重点介绍 LLM 如何帮助分析实验数据,包括预处理、数据清理和其他分析任务,同时帮助审阅者和复制者调查研究。这些任务中的每一项都会提高报告准确发现的可能性。

人工智能公平性与效用的联合优化
如今,人工智能越来越多地被用于许多高风险决策应用中,其中公平性是一个重要问题。目前,已经有许多人工智能存在偏见并做出可疑和不公平决策的例子。人工智能研究界提出了许多方法来衡量和减轻不必要的偏见,但其中很少有方法涉及人类决策者的意见。我们认为,由于不同的公平标准有时无法同时满足,并且实现公平通常需要牺牲模型准确性等其他目标,因此,关键是要了解并遵守人类决策者关于如何在这些目标之间进行权衡的偏好。在本文中,我们提出了一个框架和一些示例方法来引出这些偏好并根据这些偏好优化人工智能模型。


语言研究理论与实践目录
摘要——多年来,指导性 SLA 研究强调不同教学情境中的纠正反馈 (CF) 互动,并表明 CF 在 L2 发展中的促进作用。然而,很少有研究调查教师的 CF 实践与他们的信念及其对学习者在传统语言学习情境中吸收的影响。通过结构化观察和半结构化访谈,本研究在美国一所 K-12 学校的一个中低 (LI) 班和一个中高 (HI) 班中考察了两位教师的 CF 实践、信念及其对阿拉伯语作为传统语言 (AHL) 情境中的 L2 学习的影响。从两个有 30 名学生的班级收集了总共 20 小时的观察数据,并根据 Lyster 和 Ranta (1997, 2007) 的 CF 类型分类法进行编码。访谈数据是从两位班主任那里收集的,并基于扎根理论方法进行主题编码和分析。结果表明,两位教师都对 CF 抱有积极的看法,并且偏爱隐性 CF 和提示。LI 教师的 CF 实践在很大程度上反映了他们的 CF 信念,而 HI 教师的实践则完全反映了他们的 CF 信念。LI 教师主要针对学习者的词汇错误提供反馈,而 HI 教师主要针对学习者的语法错误做出回应。LI 教师使用引出、重述和元语言反馈被证明可以有效地提高吸收率和修复率。另一方面,在 HI 教师的课堂上,引出和澄清要求是最有效的 CF 类型。研究结果表明,具有 CF 知识的教师可以提供 CF,最终可能导致高吸收率和修复率。索引术语 — 纠正反馈、学习者吸收、CF 信念、CF 实践、母语使用