XiaoMi-AI文件搜索系统
World File Search System浮点数

IBM Telum 处理器:为企业工作负载集成 AI IBM 的下一代处理器将 AI 集成到 IBM Z 中
加速器本身提供超过 6 TFLOPS 的 16 位浮点吞吐量,每个芯片可扩展到大约 200 TFLOPS。脉动阵列中的 1024 个处理器块组成矩阵阵列,256 个 fp16/32 块组成用于计算激活的加速器,并包含 RELU、tanH 和 log 的内置函数。该平台还提供企业级可用性和安全性,正如人们对 Z 的期望一样,具有虚拟化、错误检查/恢复和内存保护机制。虽然 6 TFLOPS 听起来并不令人印象深刻,但请记住,此加速器针对事务处理进行了优化。与语音或图像处理不同,大多数数据都是浮点数,并且高度结构化。因此,我们相信这款加速器将提供足够的性能,并且无疑比

应用于浮点染色体表示的遗传算法的传统技术
遗传算法最近已成为实用且可靠的优化方法。试图解决特定问题时要考虑的最重要的问题之一是选择适当的染色体表示。主要使用的染色体表示是二进制字符串,字符串,浮点数,数字,矩阵和其他数据结构的阵列[3,4,5,6,8,10]。对于给定的问题,与其他表示相比,总会有一个表现出更好的优化结果。然而,遗传算法理论主要集中在二进制表示上,对非二进制表示几乎没有什么可说的。遗传算法结构中的另一个重要问题,与染色体表示的选择密切相关,是编码和解码机制,它们在染色体表示和优化问题的变量之间执行转换[10]。这些机制取决于问题变量的性质。

机载计算机技术 - 学术共享
早期的机载数字计算机使用了微型真空管、分立半导体元件和混合电路。当集成电路得到开发和改进后,人们的偏好迅速转向集成电路。整个 20 世纪 60 年代中期,随着集成电路产量的增加,双极硅集成电路的使用几乎变得普遍。这与内存改进一起,带来了计算速度的普遍提高以及重量和功耗的降低。随着硬件代价的降低和可靠性的提高,并行算术运算在这一时期设计的计算机中得到普遍使用。字长变得更加标准化。浮点数表示开始出现。基本指令集中的指令数量开始更快地增长。同时,机载计算机的成本也变得更低。

印度信息技术学院达尔瓦德印度信息技术学院...
电子与通信工程节点和网格分析、叠加、戴维南定理、诺顿定理、线性电路(RL、RC、RLC)的时间和频域分析连续时间信号:傅里叶级数和傅里叶变换、线性时不变系统:属性、因果关系、稳定性、卷积、频率响应二极管电路:削波、钳位、整流器、BJT 和 MOSFET 放大器:偏置、小信号分析、运算放大器电路:放大器、微分器、积分器、有源滤波器、振荡器、数字表示:二进制、整数、浮点数、组合电路:布尔代数、逻辑门、序贯电路:锁存器、触发器、计数器、数据转换器:采样和保持电路、ADC、DAC、机器指令和寻址模式、算术逻辑单元(ALU)、数据路径、控制单元、指令流水线、反馈原理、传递函数、框图表示、信号流图、数字调制方案:ASK、PSK、FSK、QAM、带宽和通信系统。
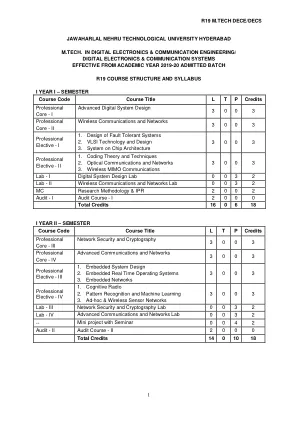
R18 B.Tech。 EEE教学大纲Jntu Hyderabad 1
高级数字系统设计(PC - I)单元 - I处理器算术:Two的补体编号系统 - 算术操作;固定点号系统;浮点数系统 - IEEE 754格式,基本二进制代码。单元-II组合电路:CMOS逻辑设计,组合电路的静态和动态分析,时机危害。功能块:解码器,编码器,三态设备,多路复用器,奇偶校验电路,比较器,加法器,减法器,随身携带的浏览器 - 定时分析。组合乘数结构。单位-III顺序逻辑 - 锁存和触发器,顺序逻辑电路 - 时序分析(设置和保持时间),状态机 - Mealy&Moore机器,分析,使用D触发器,FSM设计,FSM设计,FSM优化和分区;同步器和标准化。FSM设计示例:自动售货机,交通信号灯控制器,洗衣机。单元 - IV子系统设计使用功能块(1) - 设计(包括时间分析)的不同逻辑块的不同复杂性的不同逻辑块,主要涉及组合电路:
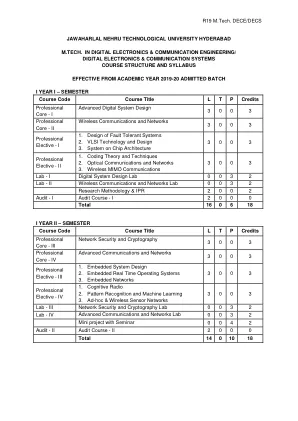
R19 技术硕士十/十
高级数字系统设计 (PC – I) 单元 - I 处理器算法:二进制补码系统 - 算术运算;定点数系统;浮点数系统 - IEEE 754 格式,基本二进制代码。单元 - II 组合电路:CMOS 逻辑设计,组合电路的静态和动态分析,时序风险。功能块:解码器、编码器、三态设备、多路复用器、奇偶校验电路、比较器、加法器、减法器、进位超前加法器 - 时序分析。组合乘法器结构。单元 - III 序贯逻辑 - 锁存器和触发器,序贯逻辑电路 - 时序分析(建立和保持时间),状态机 - Mealy & Moore 机,分析,使用 D 触发器的 FSM 设计,FSM 优化和分区;同步器和亚稳态。 FSM 设计示例:自动售货机、交通信号灯控制器、洗衣机。单元 - IV 使用功能块进行子系统设计 (1) - 设计(包括时序分析)不同复杂程度的不同逻辑块,主要涉及组合电路:

基于 FPGA 的 YOLO 可重构 CNN 加速器
摘要 卷积神经网络(CNN)在图像处理领域得到了广泛的应用,基于CNN的目标检测模型,如YOLO、SSD等,已被证明是众多应用中最先进的。CNN对计算能力和内存带宽要求极高,通常需要部署到专用的硬件平台上。FPGA在可重构性和性能功耗比方面具有很大优势,是部署CNN的合适选择。本文提出了一种基于ARM+FPGA架构的带AXI总线的可重构CNN加速器。该加速器可以接收ARM发送的配置信号,通过分时方式完成不同CNN层推理时的计算。通过结合卷积和池化操作,减少卷积层和池化层的数据移动次数,减少片外内存访问次数。将浮点数转换为16位动态定点格式,提高了计算性能。我们分别在 Xilinx ZCU102 FPGA 上为 COCO 和 VOC 2007 上的 YOLOv2 和 YOLOv2 Tiny 模型实现了所提出的架构,在 300MHz 时钟频率下峰值性能达到 289GOP。

A20-TX v1.00 用户指南
● 全球 VHF 和 UHF 调谐范围从 169 MHz 到 1525 MHz。 ● 电池运行时间长达 12 小时。 ● 使用可充电锂电池或标准 AA 电池,环保运行。 ● 通过 USB-C 内置电池充电器。 ● 通过 A20-Remote 配套应用程序以及通过长距离 NexLink 从 A20-Nexus 和 A20-Nexus Go 完全远程控制 A20-TX。 ● 最先进的 100% 数字长距离调制可提供市场上任何系统的最长传输距离。 ● 射频功率输出从 2 mW 到 40 mW。 ● Lemo 输入支持 2 线或 3 线单声道领夹式麦克风、平衡麦克风、可切换 12、48V 幻象、平衡线路电平、AES3、AES42(兼容 Schoeps SuperCMIT)和吉他(带可选的 A20-TX 智能吉他线)。 ● GainForward 架构 – 无需担心 A20-TX 上的增益控制。● 完整的 10 Hz - 20 kHz 音频带宽。● 内置 8 系列、全平衡麦克风前置放大器(140 dB 动态范围)。● 超静音领夹式麦克风前置放大器(134 dB 动态范围)。● 内置 32 位浮点数,48 kHz 录音到可移动微型 SD 卡(不包括在内)。● 内置超稳定时间码,通过无线 NexLink 自动卡住。● 阳光下可读的电子纸屏幕,用于控制和显示。关机时显示内容保持不变。● USB-C 用于与 A20-Nexus 配对、文件卸载、充电和时间码卡住。● 可选的 A20-TX 开关,用户可编程、磁感应、物理可拆卸、卡口式开关。

choreutils.pdf
2.1备份选项。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>2 2.2块大小。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>3 2.3信号规格。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。5 2.4 Chown,Chgrp,Chroot,ID:歧义用户名和ID。。。7 2.5随机数据来源。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。7 2.6目标目录。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。8 2.7拖尾。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。9 2.8穿越符号链接。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。9 2.9治疗 /特殊。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。10 2.10特殊的内置公用事业。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。10 2.11退出状态。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。10 2.12浮点数。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。11 2.13标准符合条件。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。11 2.14 Coreutils:多通用程序。。。。。。。。。。。。。。。。。。。。。。。。。。。。。 div>。 div>。 div>。 div>12 div>

DeepGoplus推断的数值稳定性
卷积神经网络(CNN)目前是可用的最广泛使用的深神经网络(DNN)架构之一,并实现了许多问题的最新性能。最初应用于计算机视觉任务,CNN可与具有空间关系的任何数据(图像之外)很好地运行,并且已应用于不同的领域。然而,最近的作品强调了DNN中的数值稳定性挑战,这也与它们对噪声注入的已知敏感性有关。这些挑战可能会危害其性能和可靠性。本文研究了预测蛋白质功能的CNN DeepGoplus。deepgoplus已经达到了最先进的性能,并可以成功利用并注释蛋白质组学中出现的蛋白质序列。我们通过量化基础流量数据扰动而产生的数值不确定性来确定模型推理阶段的数值稳定性。此外,我们探索了使用降低精确的浮点数格式进行DeepGoplus推断的机会,以减少记忆消耗和延迟。这是通过使用Monte Carlo Arithmetic仪器执行的来实现的,该技术可以在实验上量化点功能操作误差和VPREC,该工具以可自定义的流量流动点上的精度格式模仿结果。焦点放在推理阶段,因为它是DeepGoplus模型的主要交付,广泛适用于不同环境。总的来说,我们的结果表明,尽管DeepGoplus CNN在数值上非常稳定,但只能通过较低精确的流动点格式选择性地实现。我们得出的结论是,从预先训练的DeepGoplus模型中获得的预测在数值上非常可靠,并且有足够的现有旋转点格式有效。