XiaoMi-AI文件搜索系统
World File Search System猜词

合作游戏环境中人工智能代理的心理模型
摘要 随着越来越多的人工智能形式变得普遍,了解人们如何开发这些系统的心理模型变得越来越重要。在这项工作中,我们通过合作猜词游戏研究人们对人工智能的心理模型。我们进行了出声思考研究,人们与人工智能代理一起玩游戏;通过主题分析,我们确定了参与者开发的心理模型的特征。在一项大规模研究中,我们让参与者在线与人工智能代理玩游戏,并使用赛后调查来探究他们的心理模型。我们发现获胜次数更多的人对人工智能代理的能力有更好的估计。我们提出了建模人工智能系统的三个组成部分,提出了解底层技术不足以开发适当的概念模型(行为分析也是必要的),并建议未来研究心理模型随时间推移的修订。

多词和机器学习,用于预防和管理女性生殖健康
女性通常承担哺乳动物的大部分繁殖负担。在人类中,这种负担进一步加剧了,因为大型人类大脑的进化优势以女性生殖健康的巨大成本产生了巨大的代价。妊娠因此在妇女的身体和情感上成为高度要求的阶段,因此需要监测以确保最佳结果。此外,越来越多的社会趋势朝着生殖并发症迈进,部分原因是母亲的年龄增加和全球肥胖大流行需求对女性生殖健康的监测更加紧密。这篇评论首先提供了女性生殖生物学的概述,并进一步探讨了大规模数据分析和 - 组技术(基因组学,转录组学,蛋白质组学和代谢组学)对诊断,预后和对女性生殖障碍的管理的利用。此外,我们还探索了用于预防和管理的预测模型的机器学习方法。此外,移动应用程序和可穿戴设备提供了不断监测健康的希望。这些互补技术可以合并为监测女性(与生育有关的)健康以及对提供干预溶液的任何早期并发症的检测。总而言之,技术进步(例如,OMICS和可穿戴设备)对女性生殖疾病的诊断,预后和管理有希望。 在女性生殖医疗保健中迫切需要在社会利益的国家医疗保健系统中进一步实施这些技术的系统整合。总而言之,技术进步(例如,OMICS和可穿戴设备)对女性生殖疾病的诊断,预后和管理有希望。在女性生殖医疗保健中迫切需要在社会利益的国家医疗保健系统中进一步实施这些技术的系统整合。

使用元词,基因组学和异源表达方法的组合
自2005年FDA批准Sorafenib以来,口服多次激酶抑制剂已成为转移性肾细胞癌(MRCC)的基石治疗。2021年更新的欧洲泌尿外科协会肾细胞癌指南建议将免疫检查点抑制剂加上口服酪氨酸激酶抑制剂(TKI)组合,以对MRCC进行第一线治疗。相对于单独的口服TKI,这种方法在无进展和整体生存(OS)方面取得了可观的增长。对于无法服用或耐受检查点抑制剂的患者以及对免疫疗法反应的患者,仍考虑口服TKI单一疗法。MRCC患者中的1个口腔TKI治疗序列的研究很少2,可能构成疾病进展的预后标志。3,4

量子启发的表示,用于长尾词感官歧义
数据不平衡,也称为数据的长尾分布,是数据驱动模型的重要挑战。在“意义上的歧义”(WSD)任务中,单词感官分布的长尾现象更为普遍,这使得很难有效地表示和识别长尾感官(LTSS)。因此,探索不严重依赖训练样本量的表示形式是对抗LTSS的重要方法。考虑到许多新状态,即叠加状态,可以从量子力学中的几个已知状态构建,因此超级态态提供了从从较小的样本量中学到的下较低表示中获得更准确的表示的可能性。受量子叠加状态的启发,提出了一种在希尔伯特空间中的表示方法,以赋予对大样本量的依赖性,从而使LTSS对抗。理论上证明了该方法的正确性,并在标准WSD评估框架下验证其有效性并获得最新性能。fur-hoverore,我们还测试了构建的LT和最新的跨语言数据集,并取得了令人鼓舞的结果。

跨模态完形填空任务:脑到词解码的新任务
从非侵入性大脑活动中解码语言引起了神经科学和自然语言处理研究人员越来越多的关注。由于脑记录的噪声性质,现有的研究将脑到词的解码简化为二元分类任务,即区分脑信号是其对应的单词还是错误的单词。然而,这种成对分类任务不能促进实用神经解码器的发展,原因有二。首先,它必须枚举测试集中的所有成对组合,因此预测大词汇表中的单词效率低下。其次,完美的成对解码器无法保证直接分类的性能。为了克服这些问题并进一步实现现实的神经解码器,我们提出了一种新颖的跨模态完形填空 (CMC) 任务,即以上下文为提示,预测神经图像中编码的目标单词。此外,为了完成这项任务,我们提出了一种利用预训练语言模型来预测目标词的通用方法。为了验证我们的方法,我们对来自两个脑成像数据集的 20 多名参与者进行了实验。我们的方法在所有参与者中平均实现了 28.91% 的 top-1 准确率和 54.19% 的 top-5 准确率,远远超过了几个基线。这一结果表明我们的模型可以作为 CMC 任务的最新基线。更重要的是,它证明了从大脑神经活动中解码大词汇表中的某个单词是可行的。

研究论文 基于脑电图的波斯语多词想象语音分类
本研究的重点是利用脑电图信号为想象词提供一个简单、可扩展、多类的分类器。六个波斯语单词以及静默(或空闲状态)被选为输入类。这些单词可用于控制鼠标/机器人运动或填写简单的计算机表格。本研究的数据集是五名参与者在五次会话中收集的 10 条记录。每条记录重复了 20 次所有单词和静默。特征集由 1 至 32 Hz 频带中 19 个脑电图通道的归一化 1 Hz 分辨率频谱组成。二元 SVM 分类器组的多数规则用于确定特征集的相应类。通过蒙特卡洛交叉验证估计分类器的平均准确度和混淆矩阵。根据记录类间和类内样本的时间差异,定义了三种分类模式。在长时间模式下,即涉及整个数据库中单词的所有实例,单词-沉默的平均准确率约为 58%,单词-单词的平均准确率约为 60%,单词-单词-沉默的平均准确率约为 40%,七类分类(6 个单词+沉默)的平均准确率约为 32%。对于短时间模式,当仅使用相同记录的实例时,准确率分别为 96%、75%、79% 和 55%。最后,在混合时间分类中,每个类别的样本都来自不同的记录,平均准确率最高,约为 97%、97%、92% 和 62%。即使在长时间模式的最坏情况下,这些结果也明显优于随机结果,并且与该领域先前研究报告的最佳结果相当。

免疫词:免疫相互作用药物的免疫调节评估平台
当您与糖基团研究所合作时,您将获得我们最先进的基础设施和世界领先的科学专业知识。糖胶菌免疫母体平台研究所依赖于使用我们具有广泛配备的糖碱分析设施,该设施提供了用于定制印刷幻灯片的微阵列制造套件,以使用表面质子膜共振来表征结合动力学。糖叠式分析设施支持确定蛋白质,整个真核和原核细胞,寄生虫和病毒的聚糖结合曲线,以确定这些结合相互作用的表征。

长covid中的因果基因发现的综合多词框架
1* Unisa STEM,南澳大利亚大学,Mawson Lakes,Adelaide 6,5095,SA,澳大利亚。7 2农业和食品,英联邦科学与工业研究8组织,26 Pembroke Rd,Marsfield,2122,新南威尔士州,澳大利亚。9 3澳大利亚精密健康中心,南澳大利亚大学,阿德莱德10号,澳大利亚,5000,澳大利亚。11 4 Unisa Allied Health and Human Expormast,南12澳大利亚大学,阿德莱德,SA,5000,澳大利亚。13 5南澳大利亚卫生与医学研究所(SAHMRI),南澳大利亚大学14号,阿德莱德大学,澳大利亚5000,澳大利亚。15 6南澳大利亚大学未来工业学院,莫森16湖,阿德莱德,5095,澳大利亚,澳大利亚。17 7应用人工智能研究所,迪金大学,75 Pigdons 18 Rd,Victoria,3216,澳大利亚墨尔本。19 8达利大学工程学院,达利2号,达利,671003,中国20号。21
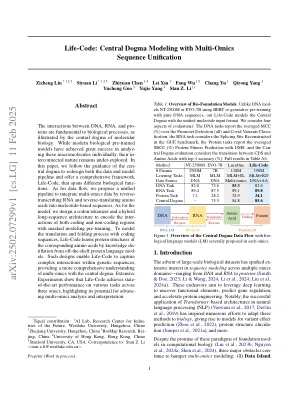
生命代码:具有多词序列统一的中央教条建模
如分子生物学的中心教条所示,DNA,RNA和蛋白之间的相互作用是生物过程的基础。现代生物学预训练的模型在分析这些大分子方面取得了巨大的成功,但它们的感染性质仍未得到探索。在本文中,我们遵循Central Dogma的指导来重新设计数据和模型管道,并提供一个全面的框架,即生命代码,这些框架涵盖了不同的生物功能。至于数据流,我们提出了一条统一的管道来通过将RNA转录并反向翻译为基于核苷酸的序列来整合多词数据。至于模型,我们设计了一个密码子令牌和混合长期架构,以用遮罩的建模预训练编码编码和非编码区域的相互作用。通过编码序列对翻译和折叠过程进行建模,生命代码通过从现成的蛋白质语言模型中的知识分离来学习相应的氨基酸的蛋白质结构。这样的设计使生命代码能够在遗传序列中捕获复杂的相互作用,从而更全面地了解了与中央教条的多摩学。广泛的实验表明,生命代码在三个OMIC的各种任务上实现了状态绩效,突出了其进步多摩学分析和解释的潜力。

协作护理文档模板和智能词此文档提供了ORGA
最好直接与患者/父母/照顾者交谈以引入COCM计划,但这并不总是可能。当您无法直接与患者/父母/照顾者联系时,您可以使用此智能短语通过门户网站启动有关COCM的推荐或将COCM引入患者/父母/父母/护理人员。亲爱的***,我正在与您联系,因为您的医疗提供商@Medical提供者已将您推荐给精神病学协作护理(COCM)计划。COCM计划的目标之一是帮助您和您的医疗提供者管理您的心理保健服务,而无需您去找其他医生。我们主要集中于减轻抑郁症和焦虑的症状。作为COCM的一部分,您将获得我的定期联系,以帮助您跟踪进度。此联系人可以通过电话,电子邮件,门户或面对面的访问。此外,我将咨询一位精神科医生,他将协助提出药物建议。您将不会与精神科医生会面,但是我将有机会提出和讨论您可能与他们提出的任何药物问题或问题。然后,精神科医生将向@Medical提供商名称 @提出建议,这可能对您有所帮助。可以继续用药。您的医疗提供者将与您讨论这些选择,而你们两个将决定治疗计划。我会保留