XiaoMi-AI文件搜索系统
World File Search System编码序列

西方国家的老年人的糖尿病自我管理教育(DSME):范围审查
1型糖尿病(T1D)的病因是一种以自身免疫性破坏胰腺β细胞为特征的复杂疾病[1]。目前尚无治疗方法或有效的预防策略,直到最近才进行了免疫干预措施,以延迟FDA批准(teplizumab)[2]。在没有完全阻塞T1D开始和发展为临床疾病的情况下,唯一的治疗方法是终身胰岛素治疗。因此,需要确定治疗干预的新目标。从遗传关联研究(例如T1D)的遗传关联研究可以提供对病原体的新见解,揭示了潜在的治疗靶标[3],并为前靶靶标提供了人类的遗传支持[4]。但是,将遗传发现转化为生物学和治疗见解存在主要障碍。遗传关联研究的结果对于许多科学而言是无法访问的,因为利用和解释大型遗传“摘要”文件需要在数据操作和域特异性生物信息学工具方面的知识方面的专业知识。此外,大多数T1D风险变体映射到非编码序列,其中基因组的详细功能注释对于预测受影响的细胞类型和基因是必要的[5]。最后,在细胞和动物模型中测试变体和基因功能仍然是一项实质性的事业,通常需要多年的工作。

使用新型 Lb Cas12a 变体对大麦进行高效基因组编辑以及 sgRNA 结构的影响 Tom Lawrenson、Alison Hinchliffe、Macarena
CRISPR、Cas12a、CPF1、大麦、诱变、单子叶植物、基因组编辑摘要我们报告了首次成功、高效使用大麦中的 Lb Cas12a,并描述了两种新型 Cas12a 变体的开发和应用。总共我们使用二十种不同的指南比较了五种编码序列 (CDS) 变体,包括两种新型变体和两种指南架构,针对 5 种不同的靶基因。我们发现不同 CDS 版本 (0-87%) 和指南架构 (0-70%) 之间的编辑效率存在很大差异,并且表明我们的两个新型 CDS 版本在该物种的测试中大大优于其他版本。我们展示了产生的突变的遗传性。我们的研究结果强调了优化单个物种的 CRISPR 系统的重要性,并可能有助于在其他单子叶植物中使用 Lb Cas12a。正文 毛螺菌科细菌 Cas12a (Lb Cas12a) 可能是继化脓性链球菌 Cas9 (Sp Cas9) 之后植物基因组编辑中第二广泛使用的可编程核酸酶,并且具有一些潜在优势。首先,由于其对 TTTV PAM 的要求与 NGG 的 Sp Cas9 要求不同,它可用于 GC 沙漠,而 GC 沙漠通常存在于内含子、UTR 和启动子区域中。其次,Lb Cas12a 通常比 Sp Cas9 产生更大的缺失,这可能在缺失研究中有用。第三,虽然 Sp Cas9 在靶标的 PAM 近端切割产生平端,但 Lb Cas12a 在 PAM 远端区域切割产生粘端;这两个特征可能解释了使用 Lb Cas12a 实现的基因靶向发生率更高 (Wolter 和 Puchta,2019)。已知在植物中起作用的三种版本的 Lb Cas12a 针对一个大麦靶标进行了测试。首先,是水稻优化的编码序列 (CDS) (Os Cas12a) (Tang et al., 2017);其次是人类优化的 CDS (Hs Cas12a),在双子叶植物中具有功能 (Bernabé-Orts et al., 2019);第三是拟南芥优化的 CDS,包含 D156R“耐高温”突变 (tt At Cas12a) (Schindele and Puchta, 2020)。我们还创建了两个新版本,携带 D156R 突变的 Hs Cas12a (tt Hs Cas12a) 和携带 8 个内含子的 tt At Cas12 (tt At Cas12+int)。这些内含子之前曾显著提高过 Sp Cas9 的效率(Grutzner 2021),因此我们使用相同的在线工具(NetGene2 - 2.42 - Services - DTU Health Tech)在我们的 tt At Cas12+int 设计中为拟南芥选项获得了较高的剪接置信度。

dnaapler:一种重新定向循环微生物基因组的工具
许多生物学实体在内,包括细菌,古细菌,质粒,噬菌体和其他病毒都可以具有圆形基因组。一旦组装,圆形基因组序列表示为线性字符串,并以某种方式标记,以表明其应为圆形。线性序列开始的点是随机的,这是由于从测序读取中组装基因组时使用的算法的性质。这种任意的起点会影响下游基因组注释和分析。它们可能发生在编码序列(CD)中,可能会破坏移动遗传因素(如预言)的预测潜力,并难以基于基因顺序进行pangenome分析。因此,通常需要将微生物序列重新定向,以从某些基因开始:细菌染色体的DNAA染色体复制引发剂基因,质粒的RepA质粒复制起始基因和TERL大型末端末端基因酶基因的细菌亚nunit基因的细菌属基因。在这里,我们提出了DNAAPLER,这是一种柔性微生物序列的重新定向工具,可快速,一致地取向圆形微生物基因组,例如细菌,质粒和噬菌体。Dnaapler在github上托管在github.com/gbouras13/dnaapler上。

评估调节基因组学预训练的DNA语言模型的代表性
基因组语言模型(GLM)的出现提供了一种无监督的方法,用于学习非编码基因组中的广泛的顺式调节模式,而无需湿LAB实验产生的功能活动标签。先前的评估表明,可以利用预训练的GLM来提高广泛的监管基因组学任务的预测性能,尽管使用了相对简单的基准数据集和基线模型。由于这些研究中的GLM在对每个下游任务的重量进行微调时进行了测试,从而确定GLM表示是否体现了对顺式调节生物学的基本理解仍然是一个悬而未决的问题。在这里,我们评估了预训练的GLM的代表性,以预测和解释跨越DNA和RNA调控的细胞类型特异性功能基因组学数据。我们的发现表明,与使用单热编码序列的常规机器学习方法相比,探测预训练的GLM的表示没有实质性优势。这项工作强调了当前GLM的主要差距,从而在非编码基因组的常规培训策略中提出了潜在的问题。

甘氨酸最大酰基 - 酰基 - 酰基载体蛋白硫酯酶B基因...
与饱和脂肪酸合成的脂肪酰基 - 酰基载体蛋白硫酯酶B(FATB)基因在脂肪酸含量和储存脂质的组成中起着重要作用。然而,FATB在大豆中的作用(甘氨酸最大)的特征很差。本文提出了10个假设FATB成员的初步生物信息学和分子生物学研究。结果表明,GMFATB1B,GMFATB2A和GMFATB2B包含许多参与防御和压力反应以及分生组织组织表达的响应元素。此外,GMFATB1A和GMFATB1B的编码序列比其他基因明显更长。它们的表达在生长过程中在大豆植物的不同器官中有所不同,GMFATB2A和GMFATB2B显示出较高的相对表达。此外,亚细胞定位分析表明,它们主要存在于叶绿体中。Overexpression of GmFATB1A , GmFATB1B , GmFATB2A and GmFATB2B in transgenic Arabidopsis thaliana plants increased the seed oil content by 10.3%, 12.5%, 7.5% and 8.4%, respectively, compared to that in the wild-type and led to signi fi cant increases in palmitic and stearic acid content.因此,这项研究增强了我们对大豆中FATB家族的理解,并为随后改善大豆质量提供了理论基础。

通过 CRISPR / Cas9D10A 切口酶生成两种 Nr2e3 小鼠模型的数据
NR2E3 编码一个孤儿核受体,该受体在光感受器中起转录激活剂和抑制剂的双重功能,是视锥细胞命运抑制以及视杆细胞分化和体内平衡所必需的。该基因突变会导致色素性视网膜炎 (RP)、增强型 S 视锥综合征 (ESCS) 和 Goldmann-Favre 综合征 (GFS)。据报道,一种 Nr2e3 异构体包含所有 8 个外显子,第二种 — 以前未报道 — 较短的异构体仅跨越前 7 个外显子,其功能仍然未知。在这篇数据文章中,我们通过使用 CRISPR/Cas9-D10A 切口酶靶向 Nr2e3 的外显子 8 设计并生成了两种新型小鼠模型,以剖析这两种异构体在 Nr2e3 功能中的作用并阐明 NR2E3 突变引起的不同疾病机制。这种策略产生了几个经过修饰的等位基因,改变了最后一个外显子的编码序列,从而影响了转录因子的功能域。等位基因 27 是 27 bp 的框内缺失,消除了二聚化域,而等位基因 E8(外显子 8 的完全缺失)只产生了缺乏二聚化和抑制域的短同种型。两者的形态和功能改变

考试问题分子生物学和生物技术
1。分子生物学的中心教条。半保守的DNA复制。证实半保守DNA复制的实验。2。核苷,核苷酸及其实例。嘌呤和嘧啶氮基碱。核苷酸在细胞中的生物学作用。3。真核和原核细胞中DNA包装的原理。核小体的结构。4。RNA的主要类型:结构和功能。5。遗传密码。基因编码的本质。遗传密码的基本特性和普遍性。6。核基因的结构:编码序列和启动子。7。真核基因的镶嵌结构(内含子和外显子),亲动机的组织。8。原核生物中的复制阶段:启动,伸长和终止。原核生物的复制酶。9。真核生物中的复制阶段:启动,伸长和终止。真核生物的复制酶:类型和功能。10。转录作为基因表达的中间阶段。转录阶段(启动,伸长和终止)。11。蛋白质的翻译。蛋白作为基因表达的产物。12。DNA修复机制。13。重组DNA技术:克隆向量。限制酶和连接酶。14。聚合酶链反应。原理,变体,应用。15。蛋白质的化学成分。氨基酸的分类和特性。

D1.3 突变和基因编辑 - 生物信件
• 前导序列:位于 CRISPR 基因座一端的非编码序列(长度为 80-500 个核苷酸),有助于启动 RNA 转录并整合新的入侵者基因组(间隔物)。 • 间隔物:与入侵者(即病毒物质)相匹配的短而独特的 DNA 序列,本质上是原核生物免疫系统的记忆。 • 重复序列:分隔每个间隔物的短而相同的 DNA 序列。它们有规律地间隔开来,通常是回文结构(从 5' 和 3' 方向对称),这就是 CRISPR 这个首字母缩略词的由来“成簇的、有规律间隔的、短回文重复序列”。 位于 CRISPR 阵列附近的是 cas 基因,它们是编码区,用于编码蛋白质复合物的合成,如 Cas 蛋白(因此得名 CRISPR-Cas 系统),Cas 蛋白是一种能够消化 DNA 的核酸酶。当病毒入侵原核生物时,与病毒遗传物质相匹配的 CRISPR 阵列会转录成单个向导 RNA (sgRNA),该 RNA 会与 Cas 蛋白结合并引导其朝向病毒的遗传物质。当 sgRNA 检测到匹配的病毒 DNA 时,Cas 蛋白会裂解/切割 DNA,从而有效地阻止病毒感染。
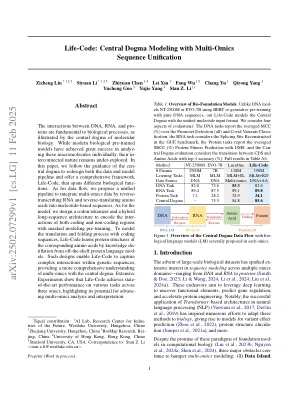
生命代码:具有多词序列统一的中央教条建模
如分子生物学的中心教条所示,DNA,RNA和蛋白之间的相互作用是生物过程的基础。现代生物学预训练的模型在分析这些大分子方面取得了巨大的成功,但它们的感染性质仍未得到探索。在本文中,我们遵循Central Dogma的指导来重新设计数据和模型管道,并提供一个全面的框架,即生命代码,这些框架涵盖了不同的生物功能。至于数据流,我们提出了一条统一的管道来通过将RNA转录并反向翻译为基于核苷酸的序列来整合多词数据。至于模型,我们设计了一个密码子令牌和混合长期架构,以用遮罩的建模预训练编码编码和非编码区域的相互作用。通过编码序列对翻译和折叠过程进行建模,生命代码通过从现成的蛋白质语言模型中的知识分离来学习相应的氨基酸的蛋白质结构。这样的设计使生命代码能够在遗传序列中捕获复杂的相互作用,从而更全面地了解了与中央教条的多摩学。广泛的实验表明,生命代码在三个OMIC的各种任务上实现了状态绩效,突出了其进步多摩学分析和解释的潜力。

分子进展使衣藻成为生物技术利用的宿主
由于近期取得的成就,莱茵衣藻正逐渐成为生物技术生产平台,我们将在本综述中简要总结这些成就。首先,由于近年来取得了一些令人印象深刻的改进,现在可以实现强大的核转基因表达。目前已有可实现高效、稳定核转基因表达的菌株,并且最近通过实现遗传杂交和识别其致病突变,使其更适合合理的生物技术方法。基于 Golden Gate 克隆的 MoClo 合成生物学策略是为衣藻开发的,它包括一个不断增长的工具包,其中包含 100 多个遗传部分,这些部分可以按照预定义的顺序进行稳健、快速的组装。这允许快速迭代转基因设计、构建、测试和学习。另一项重大进展来自各种改进转基因设计和表达的发现,例如系统地将内含子添加到密码子优化的编码序列中。最后,自 2016 年首次成功报道以来,CRISPR/Cas9 基因组编辑技术经历了多次改进,这为通过关闭竞争途径来优化生物合成途径提供了可能性。我们提供了一些例子,表明所有这些最新进展都牢固地确立了衣藻作为合成生物学底盘的地位,并允许将其代谢重新设计为新功能。