XiaoMi-AI文件搜索系统
World File Search System范数

复杂模糊粗糙弗兰克聚集算子概念下的土木工程人工智能工具分类
近来,研究人员试图处理最多的信息,并使用那些不会丢失数据或信息丢失最少的技术和方法。模糊集和复杂模糊集等结构无法讨论上近似值和下近似值。此外,我们可以观察到模糊粗糙集无法讨论第二维,在这种情况下,可能会丢失数据。为了涵盖以前想法中的所有这些问题,笛卡尔形式的复杂模糊粗糙集概念是当今的需求,因为这种结构可以讨论第二维以及上近似值和下近似值。为此,在本文中,我们开发了笛卡尔形式的复杂模糊关系和复杂模糊粗糙集理论。此外,我们基于弗兰克 t 范数和 t 范数提出了复杂模糊粗糙数的基本定律。可以将整体输入转换为单个输出的基本工具称为聚合运算符 (AO)。因此,基于 AO 的特征,我们定义了复杂模糊粗糙 Frank 平均值和复杂模糊粗糙 Frank 几何 AO 的概念。利用已开发的理论来展示所提供方法的重要性和有效性是必要的。因此,基于已开发的概念,我们为此目的定义了一种算法以及一个说明性示例。我们利用引入的结构对土木工程 AI 工具进行分类。此外,对所提供方法的比较分析表明,与现有概念相比,引入的结构有所进步。

发作间期脑电图源定位的线性分布逆解
目的:比较 6 种线性分布逆解对癫痫发作间期放电源定位的空间精度:最小范数、加权最小范数、低分辨率电磁断层扫描 (LORETA)、局部自回归平均值 (LAURA)、标准化 LORETA 和精确 LORETA。方法:通过回顾性比较 30 名成功接受癫痫手术的患者中平均发作间期放电的最大源与切除的脑区,基于 204 通道脑电图,对空间精度进行了临床评估。此外,在计算机模拟中评估了逆解的定位误差,在传感器空间和源空间的信号中添加了不同程度的噪声。结果:在临床评估中,使用 LORETA 或 LAURA 时,50-57% 的患者源最大值位于切除的脑区内,而所有其他逆向解决方案的表现都明显较差(17-30%;校正 p < 0.01)。在模拟研究中,当噪声水平超过 10% 时,LORETA 和 LAURA 的定位误差明显小于其他逆向解决方案。结论:LORETA 和 LAURA 在临床和模拟数据中均提供了最高的空间精度,同时对噪声具有相当高的鲁棒性。意义:在测试的不同线性逆解算法中,LORETA 和 LAURA 可能是发作间期 EEG 源定位的首选。2021 年国际临床神经生理学联合会。由 Elsevier BV 出版这是一篇根据 CC BY 许可开放获取的文章(http://creativecommons.org/licenses/by/4.0/)。
![arXiv:2406.07305v1 [quant-ph] 2024 年 6 月 11 日](/simg/c\c1ffc5048c64fc8eddd28b8a08b4a494f004f771.png)
arXiv:2406.07305v1 [quant-ph] 2024 年 6 月 11 日
操作语境性是量子信息理论中一个发展迅速的子领域。然而,推动这一现象的量子力学实体的表征仍然未知,目前存在许多部分结果。在这里,我们通过将操作语境性与无广播定理一一联系起来,提出了解决这个问题的方法。这种联系在完整量子理论及其子理论的层面上都有效。我们在各种相关情况下证明了这种联系,特别表明,对于量子态,证明语境性的可能性恰恰由非交换性来表征,而对于测量,这由与可重复性密切相关的范数 1 属性来实现。此外,我们展示了如何使用广播技术来简化已知的语境性基础结果。

黎曼流形上的差分隐私
在这项工作中,我们考虑了发布驻留在黎曼流形上的差分隐私统计摘要的问题。我们提出了拉普拉斯或 K 范数机制的扩展,该机制利用了流形上的固有距离和体积。我们还详细考虑了摘要是驻留在流形上的数据的 Fréchet 平均值的特定情况。我们证明了我们的机制是速率最优的,并且仅取决于流形的维度,而不取决于任何环境空间的维度,同时还展示了忽略流形结构如何降低净化摘要的效用。我们用两个在统计学中特别有趣的例子来说明我们的框架:对称正定矩阵的空间,用于协方差矩阵,以及球面,可用作离散分布建模的空间。
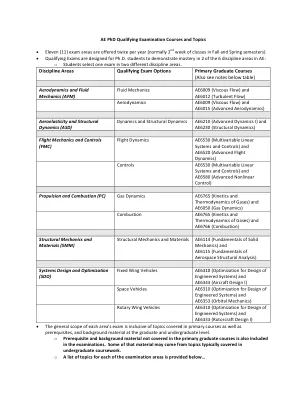
博士考试课程和主题_v3
• 频率响应 • 伯德增益和相位图 控制系统分析和设计 • 传递函数、框图和信号流图 • 稳定性分析、瞬态性能、稳态误差 • 劳斯稳定性标准 • 根轨迹技术 • PI、PD 和 PID 控制器 • 极点和零点对系统响应的影响、极点-零点抵消 控制系统的频域分析和设计 • 伯德增益和相位图 • 增益和相位裕度、相对稳定裕度、稳健性 • 超前和滞后动态补偿 • 奈奎斯特图和奈奎斯特稳定性标准 矩阵数学 • 矩阵分解(Jordan、Schur、奇异值) • 非负定矩阵和正定矩阵 • 矩阵范数、广义逆 • 矩阵指数


讲座 4:量子电路 1 回顾 2 练习 - 推迟......
回想一下,概率计算可以通过将 Hadamard 门 H 应用于 | 0 ⟩ 并观察分量来模拟。这提供了一种基本的硬币翻转机制。但是,这需要部分(仅一个量子位)和中间的测量。我们不想一直测量整个系统,因为这样做会使系统崩溃并消除干扰,从而失去量子计算的能力。另一种思考部分测量的方式是从几何角度考虑。我们可以将要测量的状态投影到两个子空间上,其中一个是所有要测量的量子位处于零状态的向量,另一个是量子位处于一状态的正交空间。部分测量是将状态投影到这两个子空间上。这样做,我们知道 2 范数由于勾股定理而得以维持(因为两个子空间是正交的),因此我们可以折叠其中一个向量并重新规范化。

专著系列 - IPI PAN
在信息时代,对大型复杂数据集进行适当的融合是必要的。只需处理少量记录,人类大脑就不得不寻找数据中的模式并绘制整体图景,而不是将现实视为一组单独的实体,因为处理和分析这些实体要困难得多。同样,使用适当的方法减少计算机上的信息过载,不仅可以提高结果的质量,还可以显著减少算法的运行时间。众所周知,依赖单一信息源的信息系统(例如,从一个传感器收集的测量值、单个权威决策者的意见、一个且只有一个机器学习算法的输出、单个社会调查参与者的答案)通常既不准确也不可靠。聚合理论是一个相对较新的研究领域,尽管古代数学家已经知道并使用了各种特定的数据融合方法。自 20 世纪 80 年代以来,聚集函数的研究通常集中于构造和形式化数学分析各种方法来汇总元素在某个实区间 I = [ a, b ] 中的数值列表。这涵盖了不同类型的广义均值、模糊逻辑连接词(t 范数、模糊蕴涵)以及 copula。最近,我们观察到人们对偏序集上的聚集越来越感兴趣,特别是在序数(语言)尺度上。在面向应用数学的古典聚集理论方面,具有开创性的专著包括 Beliakov、Pradera 和 Calvo 撰写的《聚集函数:从业者指南》[49] 以及 Grabisch、Marichal、Mesiar 和 Pap 撰写的《聚集函数》[230]。我们注意到,聚合理论家使用的典型数学武器库包括代数、微积分、序和测度理论等方法的非常有创意的组合(事实上,聚合理论的结果也对这些子领域做出了很大的贡献)。此外,以下教科书深入研究了聚合函数的特定子类:三角范数[277],作者

量子态集的几何方面
谈到量子力学,人们总是会谈到概率。但区分系统的不确定性是源于其量子性质(=量子不确定性)还是仅仅没有足够的信息来更详细地描述它(=经典不确定性)非常重要。量子力学的典型表述通过希尔伯特空间 H 中的范数向量 | Ψ ⟩ 来描述系统,可以很好地描述系统的量子不确定性。然而,当试图引入经典确定性时,人们会意识到这种表述非常不直观。描述经典概率的更自然的方式是通过所谓的密度矩阵。当有一个希尔伯特空间向量 | Ψ ⟩ 时,可以形成相应的密度矩阵 ρ = | Ψ ⟩⟨ Ψ | 。当想要描述一个系统处于状态 | 的(经典)概率为 1/2 时,密度矩阵的优势显而易见。 Ψ ⟩ 和 1/2 表示状态 | Φ ⟩ 。这可以通过密度矩阵来描述

量子计算的线性代数
正则化向量或单位向量是范数等于 1 的向量。如果所有向量都是正则化的并且相互正交,则称基是正交的。具有内积的有限向量空间称为希尔伯特空间。为了使无限向量空间成为希尔伯特空间,它除了具有内积之外,还必须遵循其他属性。由于我们主要处理有限向量空间,因此我们使用术语希尔伯特空间作为具有内积的向量空间的同义词。有限希尔伯特空间 V 的子空间 W 也是希尔伯特空间。与 W 的所有向量正交的向量集是希尔伯特空间 W - 称为正交补。V 是 W 和 W - 的直接和,即 VDW˚W-。N 维希尔伯特空间将用 HN 表示以突出其维数。与系统 A 相关的希尔伯特空间将用 HA 表示。