XiaoMi-AI文件搜索系统
World File Search System香港中文大学
香港中文大学研究生院
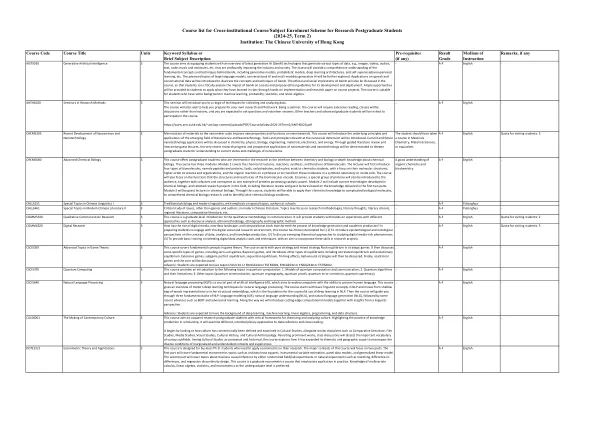
AIST5030 生成式人工智能 3 本课程旨在让学生了解最新的生成式人工智能 (GenAI) 技术,该技术可生成各种类型的数据,例如图像、视频、音频、文本、代码、音乐和分子等,对行业和社会产生深远影响。本课程将全面了解 GenAI 背后的基本概念和技术,包括生成模型、概率模型、深度学习架构和自监督/无监督学习等。将进一步探讨大型语言模型、对话式人工智能和多模态生成式人工智能的高级主题。将介绍语音和对话数据上的应用,以说明 GenAI 的概念和技术。本课程还将讨论 GenAI 的伦理和社会影响,以便学生能够批判性地分析 GenAI 对社会的影响并为其开发和部署提出道德准则。学生将有充足的机会通过实践和课程项目研究论文来应用他们在课堂上学到的知识。该课程适合具有机器学习、概率、统计和线性代数背景的学生。

深圳香港中文大学(cuhk- ...
Xiaopu Wang的实验室博士:(要求1或要求2)要求1:(1-2名学生)a。 水凝胶或聚合物的基本知识; b。 热情从事与微型机器人有关的研究; c。精通英语; d。化学实验的经验是一个加分。 e。细胞培养的经验是一个加分。需求2:(1-2个学生)a。 电磁场的理论知识; b。 热情从事微型机器人有关的研究。 c。 Python中出色的编程技能(C/C ++语言是一个加分); d。精通英语; e。喜欢在计算机视觉或图像处理方面的经验;Xiaopu Wang的实验室博士:(要求1或要求2)要求1:(1-2名学生)a。水凝胶或聚合物的基本知识; b。热情从事与微型机器人有关的研究; c。精通英语; d。化学实验的经验是一个加分。 e。细胞培养的经验是一个加分。需求2:(1-2个学生)a。电磁场的理论知识; b。热情从事微型机器人有关的研究。c。 Python中出色的编程技能(C/C ++语言是一个加分); d。精通英语; e。喜欢在计算机视觉或图像处理方面的经验;

研讨会 - Sta,Cuhk-香港中文大学
越来越多地需要使用观察数据的因果推断中的样本量和功率计算,但缺乏相关的工具。本文在因果推断的倾向评分分析中,为样本量和功率计算提供理论上有理由的分析公式。通过分析平均治疗效果的反概率加权估计器的方差(ATE),我们阐明了样本量计算的三个关键组成部分:倾向得分分布,潜在的结果分布及其相关性。我们设计了基于常见和可解释的摘要统计数据来识别这些组件的分析程序。我们阐明了治疗组之间协变量重叠在确定样本量的关键作用。特别是,我们建议将Bhattacharyya系数用作协变量重叠的量度,这与处理比例一起导致了独特的可识别且易于计算的倾向分数分布。所提出的方法适用于连续和二进制结果。我们表明,标准的两样本Z检验和方差通胀因子方法通常会导致有时不准确的样本量估计值,尤其是重叠率有限。我们还得出了治疗(ATT)和重叠人群(ATO)估计的平均治疗效果的公式。我们提供了模拟和真实的示例来说明所提出的方法。我们开发了一个关联的R软件包Pspower。这是Bo Liu和Xiaoxiao Zhou的联合作品。

年度活动报告 - 香港中文大学法学院
使命................................................................................................................................................. 3

CSCI5370.pdf - 香港中文大学计算机科学与工程系
课程:CSCI5370 课程 ID:002640 生效日期:2024-07-01 Crse 状态:有效 审批状态:已批准 [ 新课程 ] 量子计算 量子計算 本课程介绍量子计算中的以下主题:1.量子计算和通信模型;2.量子算法及其局限性;3.其他主题(量子通信、量子密码学、量子证明、量子纠错、量子霸权)。

国立大学法人広島大学
半导体关连产业が集积するリサーチ・コンプurekkusuの代名词であ るベルギーのimec (校际微电子中心)を 参考とし、卓越した研究力を中心に「人・知・资源の好循环」のハブとなる异分野融合エコshisutemu「广岛研究与创新谷(Hi-RIV)」を形成
浙江大学大学浙江大学浙江大学浙江 ...
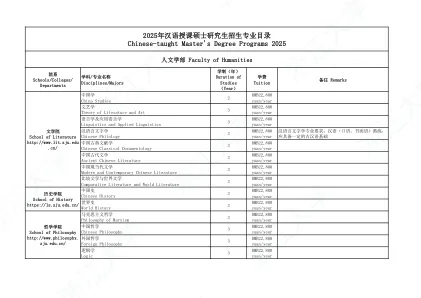
英语语言文学 English Language and Literature 2.5 RMB22,800 yuan/year 俄语语言文学 Russian Language and Literature 2.5 RMB22,800 yuan/year 法语语言文学 French Language and Literature 2.5 RMB22,800 yuan/year 德语语言文学 German Language and Literature 2.5 RMB22,800 yuan/year 日语语言文学 Japanese Language and Literature 2.5 RMB22,800 yuan/year 外国语言学及应用语言学 Linguistics and Applied Linguistics in Foreign Languages 2.5 RMB22,800 yuan/year 翻译学 Translatology 2.5 RMB22,800 yuan/year

大学课程神经退行性疾病
TECH是多功能的代名词:你将能够从任 何有互联网连接的设备上连接到虚拟教 室,无论是从电脑、平板电脑还是手机。 这个100%在线课程,让你 能够随时随地更新正常老 化的基这个认知过程"

