XiaoMi-AI文件搜索系统
World File Search System准确性

评估微波辐射计的准确性和……
摘要。为了评估风能应用的当前遥感能力,一项遥感系统评估研究称为XPIA(实验性的行星边界层仪器评估),于2015年春季在NOAA的Bolder大气天文台(BAO)举行。评估了几个遥感平台,以确定其对用于测试数字天气前词典模型准确性的验证和验证过程的适用性。对这些平台的评估是通过对精确的参考系统进行的:BAO的300 m塔,配备了六个级别(50、100、100、150、200、200、250和300 m),具有12个超音量计和六个温度(T)和相对湿度(RH)传感器;大约有60台辐射式发射。在这项研究中,我们首先采用了这些参考测量值来验证通过两个共同定位的微波辐射仪(MWRS)以及通过配备有无线电声音系统(RASSS)共同定位的风辐射雷达测得的温度(MWRS)以及通过共处于共同定位的风能辐射雷达(t)来检索的温度。结果表明,在大气的最低5 km中,微波辐射仪低于1.5 k的温度中的平均绝对误差(MAE),在大气中的虚拟温度中,在无线电声音系统中测得的虚拟温度中的平均绝对率在0.8 k覆盖的0.8 k层(这些测量层)(大约1.6 – div/dif)中的0.8 k层>

人工智能系统声明的准确性以及解释准确性的类比如何影响人类对该系统的依赖
人工智能系统越来越多地被用于支持人类决策。适当地遵循人工智能建议非常重要。然而,根据现有文献,用户通常对人工智能系统的依赖程度过低或过高,这导致团队绩效不佳。在这种情况下,我们通过对比贷款预测任务中系统信息的缺乏与系统准确性的存在来研究所述系统准确性的作用。我们通过调查数字能力水平并借助类比来解释系统准确性,探索人类理解系统准确性的程度如何影响他们对人工智能系统的依赖,这是一项首创的受试者间研究 (𝑁 = 281)。我们发现,用类比来解释系统的所述准确性并不能帮助用户适当地依赖人工智能系统(即,用户倾向于在系统正确时依赖系统,否则依赖自己)。为了消除对类比领域的主观态度的影响,我们进行了一项受试者内研究(𝑁 = 248),其中每个参与者都从事来自不同领域的基于类比的解释的任务。第二项研究的结果证实,用类比来解释系统的准确性不足以促进在贷款预测任务中对人工智能系统的适当依赖,无论个人用户有何差异。根据我们从这两项研究中得出的结论,我们推断,对人工智能系统的依赖不足可能是由于用户高估了自己解决给定任务的能力。因此,尽管熟悉的类比可以有效地提高系统所述准确性的可理解性,但对系统准确性的更好理解并不一定会导致系统依赖性和团队绩效的提高。

SenseWear™ 臂带的准确性和可靠性...
摘要——消费者和研究人员缺乏一种易于使用、可靠且经济高效的方法来准确评估身体活动和能量消耗,这是成功控制体重的关键因素。BodyMedia 通过开发 SenseWear 臂带满足了这一需求,该臂带利用 2 轴加速度计、热通量传感器、皮肤电反应传感器、皮肤温度传感器和近体环境温度传感器来收集数据,从而计算能量消耗。本文概述了相关研究,这些研究展示了 SenseWear 臂带如何提供非常低的能量消耗错误率,相对于更昂贵、限制更多且难以使用的设备,以及它如何是一种经济高效且简单的解决方案,可在实验室外应用以跟踪和探索能量消耗。索引术语——SenseWear 臂带、能量平衡、传感器阵列、能量消耗、TEE、AEE、REE、消耗评估身体活动评估、情境检测、自由生活环境、准确性和可靠性、可穿戴计算机。简介 增加身体活动量以及实现和维持能量平衡已成为 21 世纪重要的个人健康目标。卫生专业人员深知,许多主要的健康问题都是由缺乏身体活动以及摄入的热量多于消耗的热量而引起或加剧的。肥胖症流行及其相关问题,包括高血压、II 型糖尿病、冠状动脉疾病、关节炎和慢性背痛,都证明了久坐的生活方式和超重会导致生活质量低下,在许多情况下还会导致过早死亡。虽然卫生专业人员以及有体重问题的个人都承认需要改善和维持他们的锻炼和饮食行为,但他们缺乏准确测量能量消耗所需的工具,而能量消耗是确定一个人消耗的能量是否多于摄入能量的重要身体测量指标。为了减肥,一个人首先必须能够准确量化活动量和能量消耗。只有这样,他们才能开始对日常生活进行必要的适当改变,以帮助他们提高活动量和调整卡路里摄入量。到目前为止,还没有一种易于使用、可靠且准确的方法可以在实验室环境之外定期评估身体活动量和能量消耗。这对体重有重大影响

服务合同确保流程准确性
好处 将校准工作外包给 Endress+Hauser 可以让现场工程师腾出时间处理故障和计划维护。“这减轻了我的压力!”Ben Pine 笑着说。“每个月都有同一个人来现场,这确实是一个好处,因为他了解现场,了解我们的员工,遵循我们的流程,不需要他亲自指导。我知道一切都会按时校准,不会有任何障碍或问题。” 该软件有助于确保遵守所有标准操作程序 (SOP),并且校准记录易于访问。“当我们进行审计时,我可以确信我们会遵守规定,”Ben Pine 说。“但最大的好处是人。校准工程师说到做到,我们的合同经理有定期的接触点,确保我们满意。这种关系是任何合同的基础。我通常不会推荐一家公司,但我会推荐 Endress+Hauser,而且已经推荐过了。”


公司财务困扰预测模型的准确性...
摘要本研究旨在获得Altman Z-Score,Zmijewski和Grover模型的准确性的证据,以预测印度尼西亚基础设施部门的财务困扰公司。此外,研究还旨在在公司进行财务预测困扰时获得最准确的模型证明。本研究使用以2018 - 2021年期间上市的基础设施部门公司的年度财务报表的形式进行的辅助数据,总共有26家公司的总样本。结果表明,Zmijewski模型成为一个预测模型,其精度最高为88.46%,这是由I型最低误差率为25%和II型的最低误差率,而II型的误差率为9.09%。因此,Zmijewski模型是印度尼西亚基础架构公司中使用的更合适的预测模型。关键字:预测模型,财务困扰,准确性,基础架构

定量相显微镜:准确性比较
抽象的定量相显微镜(QPM)在生物形象中起关键作用,提供了补充荧光成像的独特见解。他们提供了有关质量分布和运输的基本数据,无法访问荧光技术。此外,QPM不含标签,消除了光漂白和光毒性的关注。但是,在可用的QPM技术中导航可能很复杂,因此选择最适合特定应用程序的QPM技术。本教程审查对主要QPM技术进行了详尽的比较,重点是它们在测量精度和真实性方面的准确性。我们专注于8种技术,即数字全息显微镜(DHM),跨颗粒波前显微镜(CGM),基于QLSI(四边形剪切干涉术),衍射相显微镜(DPM),差异相位(DPC)显微镜(DPC)显微镜,相位 - 相位 - 相位 - 相位 - 相位 - 相位 - 相位 - 相位 - 相位 - 季节 - 季节 - 季节 - 季节 - 想象 - 想象相关(DPM)显微镜(FPM),空间光干扰显微镜(Slim)和强度方程(TIE)成像。为此,我们使用了基于离散偶极近似(IF-DDA)的自制数值工具箱。此工具箱旨在计算显微镜样品平面处的电磁场,而与物体的复杂性或照明条件无关。我们升级了此工具箱,以使其能够建模任何类型的QPM,并考虑射击噪声。简而言之,结果表明,DHM和PSI固有地没有人工制品,而却遭受了连贯的噪音。在CGM,DPC,DPM和TIE中,精确度和真实度之间存在权衡,可以通过改变一个实验参数来平衡。在大多数情况下,FPM和Slim遭受了固有的伪像,这些伪像无法在实验中被丢弃,这使得技术不是定量的,尤其是对于涵盖大部分视野视野的大物体,例如真核生物细胞。
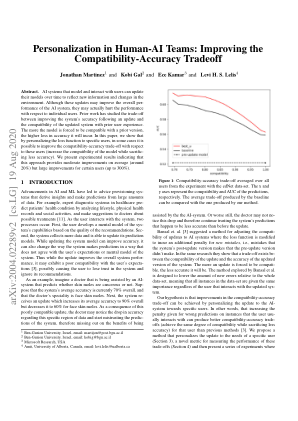
改善兼容性与准确性之间的权衡
摘要。建模并与用户交互的 AI 系统可以随时间更新其模型,以反映新信息和环境变化。虽然这些更新可能会提高 AI 系统的整体性能,但实际上可能会损害单个用户的性能。先前的研究研究了更新后系统准确性的提高与更新后系统与先前用户体验的兼容性之间的权衡。模型越被迫与先前版本兼容,其准确性损失就越大。在本文中,我们表明,通过针对特定用户个性化损失函数,在某些情况下可以改善这些用户的兼容性-准确性权衡(在牺牲较少准确性的同时提高模型的兼容性)。我们提出的实验结果表明,这种方法平均而言提供了中等程度的改进(约 20%),但对于某些用户而言,改进幅度很大(高达 300%)。

关于性能、准确性的独立研究... - uHoo
短期暴露于室内空气污染物会对健康造成不利影响,需要进行实时测量。最常见的室内污染物是二氧化碳 (CO 2 )、一氧化碳 (CO)、臭氧 (O 3 )、二氧化氮 (NO 2 )、总挥发性有机化合物 (TVOC) 和直径小于 2.5 μ m 的颗粒物 (PM 2.5 )。市面上有几种低成本的室内空气质量监测仪;然而,其中很少有经过准确测试的。本文开发了一个稳定、易于使用且可重复的平台。在这些实验室条件下,低成本传感器与计算浓度之间的比较显示为线性(PM 2.5、CO 2、CO、NO 2、TVOC(乙烯)和 O 3 的 R 2 分别为 0.980、0.972、0.990、0.958、0.987 和 0.816,r s 分别为 0.982、0.985、0.900、0.924、0.982 和 0.571)。使用实验室条件测试对 TVOC 传感器的可能交叉干扰;CO 2、CO 和 NO 2 分别增加 2500 ppm、100 ppb 和 100 ppb 导致曲线拟合从线性变为二次。通过在真实室内场所的应用,对低成本传感器进行了全面验证。PM 2.5、CO 2 和 O 3 的参考方法和 uHoo 测量值之间实现了良好的相关性(r s 分别为 0.765 至 0.894、0.721 至 0.863 和 0.523 至 0.622)。

关于代码复杂度指标的准确性
复杂性是软件质量的关键要素。本文探讨了测量代码复杂性的问题,并讨论了一项受控实验的结果,以比较测量代码复杂性的不同观点和方法。参与者(27 名程序员)被要求阅读并(尝试)理解一组程序,而这些程序的复杂性则通过不同的方法和视角进行评估:(a)经典的代码复杂性指标,如 McCabe 和 Halstead 指标,(b)基于评分代码构造的认知复杂性指标,(c)来自 SonarQube 等最先进工具的认知复杂性指标,(d)依赖于使用眼动追踪直接评估程序员行为特征(例如阅读时间和重访)的人本指标,以及(e)使用脑电图 (EEG) 评估的认知负荷/心理努力。以人为本的观点与参与者使用 NASA 任务负荷指数 (TLX) 对理解程序所需的心理努力的主观评估相得益彰。此外,代码复杂度的评估在程序级别和尽可能低的代码构造/代码区域级别上进行测量,以识别可能引发程序员对代码理解难度感知的复杂性激增的实际代码元素和代码上下文。使用 EEG 测量的程序员认知负荷被用作参考,以评估不同指标如何表达(人类)理解代码的难度。大量实验结果表明,流行的指标(如 V(g) 和 SonarSource 工具的复杂性指标)与程序员对代码复杂性的感知存在很大偏差,并且通常不会显示预期的单调行为。本文