XiaoMi-AI文件搜索系统
World File Search System即时性


分布式 AI 任务的即时通信
1 简介 人工智能领域的最新进展由 ChatGPT [ 18 ] 和 SORA [ 19 ] 等大型模型推动,带来了巨大的计算挑战。扩展这些模型通常需要多 GPU 或多节点系统 [ 2 , 14 ],利用张量并行等并行策略 [ 25 ] 来处理计算负载。例如,Llama 3.1-405B 模型训练使用了 16,000 个 H100 GPU [ 16 ]。然而,分布式计算引入了通信作为主要瓶颈,占执行时间的 80%,如 Llama 2-7B 模型所示 [ 1 ]。如 [ 3 ] 所示,将 Llama 2-13B [ 27 ] 训练从 8 个 GPU 扩展到 1,024 个 GPU 会因通信开销而将模型 FLOP 利用率 (MFU) 从 47% 大幅降低至 4%。这凸显了一个关键问题:尽管硬件功能有所进步,但由于引入了通信开销,硬件(尤其是 GPU)往往未得到充分利用。为了提高 MFU,先前的研究探索了通过通信 [ 20 、 22 、 28 、 30 ] 或数据加载 [ 9 ] 来提高硬件利用率的潜力。然而,这些策略主要侧重于重叠计算运算符和独立通信运算符。如果存在依赖关系(例如在推理阶段),则计算和通信都位于关键路径上,运算符间重叠是不可行的。认识到这一机会,我们引入了 DistFuse,这是一个即使在存在依赖关系的情况下也能促进细粒度重叠的系统。DistFuse 的核心旨在协调计算和通信,这样 GPU 就可以在部分数据准备就绪时立即启动通信,而不是等待整个数据。我们进行了一项概念验证实验,通过在单个节点上将 DistFuse 与 Llama 3-70B 的推理相结合来展示性能提升,该节点可以隐藏高达 44.3% 的通信延迟。我们目前的原型专注于 LLM 任务,但即时通信的核心概念是多功能的,可以应用于其他场景,例如卷积模型。鉴于数据中心中大型模型工作负载的日益普及以及对高效通信的需求不断增长,我们预计通过我们的技术将显着提高性能。此外,我们

PURELL® 高级即时洗手液 无香型
化学品的建议用途和使用限制 建议用途:洗手液 使用限制:这是一款个人护理或化妆品,在正常和合理可预见的使用情况下,对消费者和其他使用者来说是安全的。世界各地法规明确定义的化妆品和消费品无需向消费者提供 SDS。虽然这种材料不属于危险品,但该 SDS 包含宝贵的信息,这些信息对于在工业工作条件下以及在大量泄漏等不寻常和意外的暴露情况下安全处理和正确使用产品至关重要。应保留此 SDS 并供员工和该产品的其他用户使用。有关具体的预期用途指导,请参阅包装或说明书上提供的信息。
即时注释:免疫学,第二版
5HT 5'羟基戊胺ADA腺苷脱氨酶ADCC抗体依赖性细胞/细胞细胞毒性AFP AFPα-抗蛋白质AICD活化诱导的细胞死亡有助于获得的细胞死亡有助于获得的免疫综合征AIHA自身蛋白酶肌氨基蛋白酶阳离子孔(BB)bal骨蛋白酶囊孔囊孔, carcinoembryonic antigen CGD chronic granulomatous disease CMV cytomegalovirus CRD carbohydrate recognition domain CRH corticotrophin-releasing hormone CRP C-reactive protein CTL cytolytic/cytotoxic T lymphocyte CVID common variable immunodeficiency DAF decay-accelerating factor DAG diacyl glycerol DC dendritic cell DHEA dehydroepiandrosterone DHEAS dehydroepiandrosterone sulfate DTH delayed-type hypersensitivity EAE experimental allergic encephalomyelitis EBV Epstein–Barr virus ELISA enzyme-linked immunosorbent assay ER endoplasmic reticulum FDC follicular dendritic cell FRT female reproductive tract GALT gut-associated lymphoid tissue GC germinal center G-CSF granulocyte colony-stimulating factor GI gastrointestinal GOD generation of diversity HAMA human anti-mouse antibody HBV hepatitis B virus HEV high endothelial venules HHV8 human herpes virus 8 HIV human immunodeficiency virus HLA human leukocyte抗原
即时见解:如何跟踪AI搜索
想为营销人员学习生成AI吗?参加我们的自节奏课程:https://www.trustinsights.ai/aicourse对如何将AI集成到您的工作中有疑问吗?问我们!请访问www.trustinsights.ai/aiservices,以获取更多帮助。

医疗保健领域对人工智能的接受度
3 另外,道具的展示顺序也是随机的。 4 由于10个项目中有4个被呈现,因此如果随机呈现,每个项目出现的次数可能会有所不同。因此,可以使用平衡的不完全区组设计(Louviere 和 Flynn,2010)来确保项目出现的频率相等。然而,由于本章的样本量非常大,达到 150,010(使用下面描述的计数方法),我们确定由于随机呈现而导致的出现次数差异很小。

CD-0123(EU)即时散开2相喷雾
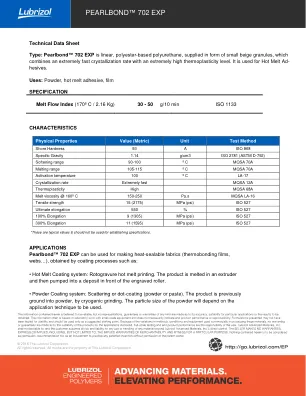
Pearlbond™702 EXP适合用于挤出和粉末应用中,其中以下功能对客户具有很高的价值:低粘度下的高速过程,并且在几分钟内,在出色的润湿性中,在几分钟内具有高粘结强度。它也可以与更多刚性树脂或反应性系统结合使用,以提高柔韧性和弹性行为(化合物)降低其TG。材料制备以达到最佳效果,建议的干燥条件在70ºC时为3小时,在热空气循环,真空或干燥空气烘干机中。挤出

即时量子电路转换降低噪音
摘要 — 在当今嘈杂的中尺度量子 (NISQ) 设备上运行量子程序充满挑战。许多挑战源于测量过程中的快速退相干和噪声、量子比特连接、串扰、量子比特本身以及通过门进行的量子比特状态转换产生的误差特性。量子比特不仅不是“生来平等的”,而且它们的噪声水平也会随时间而变化。据说 IBM 每天校准一次量子系统,并在校准时报告噪声水平(误差)。随后,此信息用于将电路映射到更高质量的量子比特和连接,直到下一个校准点。这项工作提供了证据,表明这个每日校准周期还有改进的空间。它提供了一种在执行一个或多个敏感电路之前立即测量与量子比特相关的噪声水平(误差)的技术,并表明即时噪声测量可以有益于后期的物理量子比特映射。通过这种即时重新校准的转译,结果的保真度比 IBM 的默认映射(仅使用其每日校准)有所提高。该框架评估了两个主要的噪声源,即读出误差(测量误差)和双量子比特门/连接误差。实验表明,使用基于应用程序执行前误差测量的即时电路映射,电路结果的准确性平均提高了 3-304%,最高可提高 400%。索引术语 — 量子计算、错误、动态编译

即时:自然行为中的凝视引导
自然眼球运动主要研究了泡茶、做三明治和洗手等过度学习的活动,这些活动具有固定的相关动作顺序。这些研究表明,低级认知图式的顺序激活有助于完成任务。然而,当任务新颖且必须立即规划一系列动作时,这些动作图式是否会以相同的模式激活尚不清楚。在这里,我们记录了自然任务中的凝视和身体运动,以研究面向动作的凝视行为。在虚拟环境中,受试者在真人大小的架子上移动物体以达到给定的顺序。为了强制认知规划,我们增加了排序任务的复杂性。与动作开始一致的注视表明凝视与动作序列紧密相关,任务复杂性适度影响了任务相关区域上的注视比例。我们的分析表明,凝视恰好及时分配给与动作相关的目标。规划行为主要对应于在动作开始前对任务相关对象的更大视觉搜索。研究结果支持了这样一种观点:自然行为依赖于对工作记忆的节俭使用,人类不会对环境中的物体进行编码来规划长期行动。相反,他们更喜欢即时规划,即搜索当前与行动相关的物品,将他们的身体和手引导到该物品上,监控该行动直到行动终止,然后继续执行下一个行动。