XiaoMi-AI文件搜索系统
World File Search System原始数据

AI 训练数据基本指南 - TELUS Digital
您可以通过多种方式注释数据点。因此,您标记数据点的方式会导致所需数据点数量的显著变化。假设我们有 1,000 个句子的输入数据。对于情绪分析,您可能只会将每个句子标记为一次,即积极、消极或中性。但是,对于实体提取,您可能在每个句子中标记五个单词。尽管拥有相同的原始数据,但一个任务产生的标签比另一个多五倍。如果一个数据点可以包含大量标签,那么您可能可以使用较小的整体数据集。

IBM欢迎CERN作为IBM量子网络中的新枢纽
到目前为止,科学家一直在使用经典的机器学习技术来分析粒子探测器捕获的原始数据,并自动选择最佳候选事件。,但我们认为通过用量子来增强机器学习,我们可以大大改善这一筛选过程。尤其是,比指数级的Qubit Hilbert空间,量子计算机应该能够比传统的,经典的机器学习算法更有效,准确地捕获粒子碰撞数据集中的量子相关性。这种能力应导致对实验的更好解释。

揭开私人气候融资的面纱……
• 首次尝试开发和试行方法以了解印度尼西亚的公共气候融资状况 • 使用原始数据,包括政府支出、外援和捐助者投资的国家级数据。 • 印度尼西亚是世界上第一个采用新气候融资跟踪和报告系统的国家,该系统基于 CPI 的《印度尼西亚公共气候融资状况》研究。现在要求所有部委实施绿色预算标记系统以用于气候缓解活动(财政部长令第 94/PMK.02/2017 号)

| 大气探测处理环境
打开文件后,发声的处理就开始。分析的进度显示在主屏幕左下角的状态框中,但是在处理完成之前,屏幕将保持空白。在完成探测分析后,初始屏幕将充满基于选项卡的显示,其中每个选项卡代表数据的不同视图。选项卡按数据处理的一般顺序从左到右(请参见下图),即从原始数据到QC和级别计算到编码消息。阅读选项卡显示部分以进行进一步说明。


信息和通信技术(ICT)
4.3.4. 质量保证 统计数据的质量通过遵守 2014 年 1 月 29 日联合国大会通过的《官方统计基本原则》以及 2017 年 5 月 26 日第 93 号国家《官方统计法》的规定来保证。在统计信息生成活动中,国家统计局非常重视确保数据的高质量。在这方面,在统计过程的每个阶段都采取了许多质量保证措施:组织统计调查、收集、处理和开发统计信息。我们采取了重要措施来确保统计调查中的受访者提供的数据丰富且质量上乘。我们会发现错误、不一致和可疑数据,以便进行核实和纠正。我们会从内部一致性(问卷内部)、时间一致性(与前期数据)、其他类似单位的数据以及其他统计调查和行政数据来源提供的数据的角度来验证和分析原始数据。如果需要,可以填补缺失或不一致的数据。在分析汇总数据阶段,将报告编号 1-tic 中关于商品和服务网络销售营业额和 EDI 型商品和服务销售营业额(第 6 章电子商务)的指标与财务报表年度报告中的销售收入(总计)指标进行核对。为了确保原始数据的质量,组织了与访谈员(受访者)的会议(研讨会),以解释定义、填写问卷的正确方法,尤其是在修改或实施问卷时。

单次试验 MEG 数据可通过交叉去噪...
脑成像中普遍存在的一个挑战是噪声的存在,这会阻碍对潜在神经过程的研究,尤其是脑磁图 (MEG) 具有非常低的信噪比 (SNR)。提高 MEG 信噪比的既定策略包括对与同一刺激相对应的多次重复数据进行平均。然而,重复刺激可能是不可取的,因为潜在的神经活动已被证明会在试验过程中发生变化,而重复刺激会限制受试者体验到的刺激空间的广度。特别是,一次观看电影或故事的自然主义研究越来越受欢迎,这需要发现新的方法来提高 SNR。我们引入了一个简单的框架,通过利用受试者在经历相同刺激时神经反应的相关性来减少单次试验 MEG 数据中的噪声。我们在 8 名受试者的自然阅读理解任务中展示了它的用途,在他们阅读同一故事一次时收集了 MEG 数据。我们发现我们的程序可以减少数据中的噪声,并可以更好地发现神经现象。作为概念验证,我们表明 N400m 与单词惊讶的相关性(文献中已证实的发现)在去噪数据中比在原始数据中更明显。去噪数据还显示出比原始数据更高的解码和编码准确度,这表明与阅读相关的神经信号在去噪过程后得到保留或增强。

校正:DNA拓扑异构酶II的催化抑制剂II抑制雄激素受体信号传导和前列腺癌进展
纠正了本文:Oncotarget在本文中调查了对重复图像的担忧。在图3中,面板3D中的小管蛋白带是面板3C中H3带的重复。此外,肌动蛋白频带是早期文章的图4C所示的重复,其中包括两位与Oncotarget论文共同的作者[1]。我们还发现了补充图1(三种Lancap细胞系的AR-V7 Western印迹)在[1]的图7C中与WB带重叠。这两篇文章的对应作者Xuesen Dong博士都说:“这些错误的原因是Haolong Li博士同时一直在研究两份出版物(Oncotarget和Cell and Cell and Death and Disey)。每个项目都涉及大量的蛋白质印迹测定;负载控件的所有图像看起来非常相似,并且很容易放错位置。无论如何,这些小错误并没有影响我们得出的结论。”作者提供了原始的Western印迹,上面有校正数字的日期邮票,并指出图3a肌动蛋白(2 h处理),图3D小管蛋白(第二个面板,293T细胞,用质粒编码AR(F876L)转染的293T细胞(F876L)和补充图1 AR-V7 Blot在图组合过程中被放错了。 使用原始数据获得的校正图3和补充图1如下所示。 作者声明这些更正不会改变本文的结果或结论。使用原始数据获得的校正图3和补充图1如下所示。作者声明这些更正不会改变本文的结果或结论。

第 2 章(CCT-him 的组件).pmd - NCERT
计算机的名称确实源于其基本功能,即计算。从基本意义上讲,任何计算都需要原始数据和它们之间执行的操作。这意味着接收数据、处理数据、在操作的不同阶段将数据保存在内存中、拥有一些对所有操作都至关重要的数据集并提供操作结果。因此,计算机本质上意味着一个组件系统 (i) 输入数据和显示输出,即输入和输出设备;(ii) 称为中央处理单元 (CPU) 的处理单元和 (iii) 可以是只读存储器 (ROM) 或随机存取存储器 (RAM) 的内存空间。人们应该意识到,理解计算机的不是外观,而是它的功能。
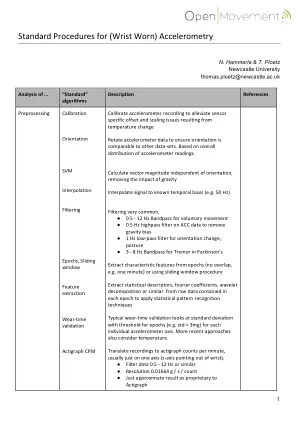
(腕戴式)加速度计的标准程序 - Axivity
从各个时期提取特征特征(无重叠,例如一分钟)或使用滑动窗口程序从每个时期包含的原始数据中提取统计描述符、傅立叶系数、小波分解或类似内容,以应用统计模式识别技术典型的佩戴时间验证着眼于每个加速度计轴的各个时期的标准偏差和阈值(例如std < 3mg)。较新的方法还考虑了温度。将记录转换为每分钟的活动记录仪计数,通常只在一个轴上(z 轴指向手腕外)。