XiaoMi-AI文件搜索系统
World File Search System反向传播

采用反向传播人工神经网络算法设计基于人工智能的 3.84 kW 货运无人机电池组
尽管在有效载荷和航程方面存在限制,货运无人机在应急物流和远程配送方面仍具有广阔的应用前景。在本研究中,我们通过开发一种高容量 3.84 kW 电池来应对这些挑战,该电池专为在苛刻地形中运行的 50 公斤有效载荷货运无人机而设计。我们专注于应急货物的运输,研究无人机设计的关键方面和电池组开发的细节,包括电池选择、内部配置以及用于电池平衡、充电/放电和高级电池管理的关键电路。一项关键创新是集成反向传播人工神经网络 (BPANN) 算法来预测放电深度 (DoD) 和充电状态 (SoC)。研究结果表明,BPANN 提供高度准确的预测,DoD 的误差百分比低至 0.12%,SoC 的误差百分比低至 0.02%,确保电池运行优化和安全。进行了全面的现场测试,以评估所提出的电池平衡策略、强大的电池管理系统 (BMS) 和 BPANN 实施的有效性。我们研究了无人机在 DoD、SoC 和使用设计的电池组的整体现场操作方面的性能,并证明了其在实际应用中的可行性和潜力。

表面ECG的心脏电生理模型的数字孪生:一种测量反向传播方法
Eikonal方程已成为准确有效地对心脏电活激活进行建模的必不可少的工具。原则上,通过匹配临床记录和核心心电图(ECG)的匹配,可以纯粹的非侵入性方式构建患者特异性心脏生理学模型。尽管如此,拟合程序仍然是一项具有挑战性的任务。本研究介绍了一种新的方法,即测量BP,以解决逆向敌军问题。Geodesic-BP非常适合GPU加速机器学习框架 - 使我们能够优化Eikonal方程的参数以重现给定的ECG。我们表明,即使在存在建模不准确的情况下,Geodesic-BP也可以在合成测试案例中以高精度重建模拟的心脏激活。fur-hoverore,我们将算法应用于双心脑兔模型的公开数据集,并具有令人鼓舞的结果。鉴于未来向个性化医学的转变,Geodesic-BP具有帮助未来功能的心脏模型的功能 - 符合临床时间段落的同时保持最先进的心脏模型的生理准确性。

表面ECG的心脏电生理模型的数字孪生:一种测量反向传播方法
摘要 - Eikonal方程已成为一种不可或缺的工具,用于对心脏电动激活进行巧妙和有效地建模。原则上,通过匹配临床记录和基于艾科尼尔的心电图(ECG),可以以纯粹的非侵入性方式构建心脏电子生理学的患者特异性模型。否则,拟合过程仍然是一项具有挑战性的任务。本研究介绍了一种新的方法,即测量BP,以解决逆向艾科尼尔问题。Geodesic-BP非常适合GPU加速机器学习框架,从而使我们能够优化Eikonal方程的参数以复制给定的ECG。我们表明,即使在存在建模不准确的情况下,Geodesic-BP也可以在合成测试案例中以高精度重建模拟的心脏激活。此外,我们将al-gorithm应用于双室兔模型的公开数据集,并具有令人鼓舞的结果。鉴于未来向个性化医学的转变,Geodesic-BP具有帮助心脏模型的未来功能化,同时保持临床时间的限制,同时保持先进心脏模型的生理准确性。

深度学习中的生物学合理性考量
大脑和人工神经网络学习的背景知识。然后,我们研究神经硬件施加的实现约束以及反向传播算法违反这些约束的原因。为了应对这些约束,人们设计了几种学习算法,例如反馈对齐、目标传播和平衡传播,每种算法都试图克服反向传播遇到的一些困难。本综述的主要内容是对这些方法的分析,包括它们的成功和失败。其中一些成功案例相当令人惊讶,表明反向传播类算法对大脑来说并不像以前认为的那样不可行。正是出于这个原因,我们认为大脑的真正功能在本质上可能与反向传播相似。

受大脑启发的预测编码提高了机器挑战性任务的性能
反向传播被认为是训练人工神经网络最有利的算法。然而,由于其学习机制与人脑相矛盾,反向传播因其生物学上的不合理性而受到批评。尽管反向传播在各种机器学习应用中取得了超人的表现,但它在特定任务中的表现往往有限。我们将此类任务统称为机器挑战任务 (MCT),旨在研究增强 MCT 机器学习的方法。具体来说,我们从一个自然的问题开始:模仿人脑的学习机制能否提高 MCT 的性能?我们假设,复制人脑的学习机制对于机器智能难以完成的任务是有效的。使用预测编码(一种比反向传播更具生物学合理性的学习算法)进行了多个对应于特定类型的 MCT 的实验,其中机器智能有提高性能的空间。本研究将增量学习、长尾和小样本识别视为代表性的 MCT。通过大量实验,我们检验了预测编码的有效性,它对 MCT 的表现远优于反向传播训练的网络。我们证明了基于预测编码的增量学习可以减轻灾难性遗忘的影响。接下来,基于预测编码的学习可以减轻长尾识别中的分类偏差。最后,我们验证了用预测编码训练的网络可以用少量样本正确预测相应的目标。我们通过将预测编码网络的特性与人脑的特性进行比较并讨论预测编码网络在一般机器学习中的潜力来分析实验结果。
与计算机视觉的深度学习
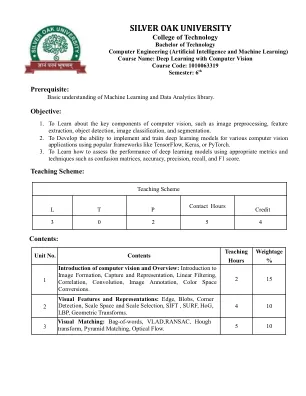
深度学习和神经网络:多层感知器:多层感知器体系结构,什么是隐藏的层?每一层中有多少层和多少个节点?激活函数:线性传输函数,重型阶跃功能(二进制分类器),sigmoid/logistic函数,软马克斯函数,双曲线切线函数(TANH),整流的线性单元,泄漏的relu。前馈过程:前馈计算,特征学习。错误函数:错误函数是什么?,为什么我们需要一个错误函数?错误总是正面的,均为正方形错误。跨凝性,关于错误和权重优化算法的最终说明:什么是优化?,批处理梯度下降,随机梯度下降,微型批次梯度下降,梯度下降点击。反向传播:什么是反向传播?,反向传播外卖。

飞行时间解析的刺激拉曼散射显微镜使用反向传播的Ultraslow Bessel Light Bullets Generation
摘要我们提出了一种新颖的旋转时间分辨出贝塞尔轻弹刺激的拉曼散射(B 2 -SRS)显微镜,用于更深的组织3D化学成像,而无需机械Z扫描。为完成任务,我们想到了一种独特的方法,可以通过在样品中生成反式泵和stoke bessel轻子弹来实现光学切片,在该泵中,Bessel Light Bullets的组速度是Ultraslow的组速度(例如VG≈0.1C),并通过引入Anglable Angemable Plights spationd spations spationgions spat-spationd。我们从理论上分析了共线多色Bessel Light Bullet Bullet Generations和速度控制的工作原理,并使用相对的SRS 3D深组织成像的相对时间分辨出的检测。我们还构建了B 2 -SRS成像系统,并在各种样品中使用Bessel Light子弹进行了B 2 -SRS显微镜的第一个演示,用于3D化学成像(例如,聚合物珠幻像(,是春季洋葱组织和猪脑脑),具有高分辨率的聚合物珠幻象,具有生物样品)。与常规的SRS显微镜相比,B 2 -SRS技术在猪脑组织的成像深度上提供了> 2倍的改善。使用B 2 -SRS中开发的反式超声贝塞尔轻子弹在组织中的光学切片方法是通用且易于执行的,并且很容易扩展到其他非线性光学成像模式,以推动在生物医学和生物医学系统和超越生物学和生物医学系统中促进3D显微镜成像。

FFCL:具有皮质环路的前向-前向网络,无需反向传播即可在边缘进行训练和推理
前向-前向学习 (FFL) 算法是最近提出的一种无需占用大量内存的反向传播即可训练神经网络的解决方案。在训练期间,标签会伴随输入数据,将其分类为正输入或负输入。每一层都会独立学习对这些输入的响应。在本研究中,我们通过以下贡献增强了 FFL:1) 我们通过在层之间分离标签和特征转发来优化标签处理,从而提高学习性能。2) 通过修改标签集成,我们增强了推理过程,降低了计算复杂性并提高了性能。3) 我们引入了类似于大脑皮层环路的反馈回路,信息在其中循环并返回到早期的神经元,使各层能够将来自前几层的复杂特征与低级特征相结合,从而提高学习效率。

研究论文 使用反向传播神经网络对高光谱遥感数据中的岩性信息进行提取和分类
为了解决高光谱遥感数据处理中遇到的同构问题,提高高光谱遥感数据在岩性信息提取与分类的精度,以岩石为研究对象,引入反向传播神经网络(BPNN),对高光谱图像数据进行归一化处理后,以岩性光谱与空间信息为特征提取目标,构建基于深度学习的岩性信息提取模型,并使用具体实例数据分析模型的性能。结果表明:基于深度学习的岩性信息提取与分类模型总体精度为90.58%,Kappa系数为0.8676,能够准确区分岩体性质,与其他分析模型相比具有较好的性能。引入深度学习后,提出的BPNN模型与传统BPNN相比,识别精度提高了8.5%,Kappa系数提高了0.12。所提出的提取及分类模型可为高光谱岩矿分类提供一定的研究价值和实际意义。

产品创新背景下的人工智能/机器学习和模拟
类似网络 - 前馈:• 在此步骤中,NN 根据当前权重 𝒘 和输入预测 Ŷ。• 计算误差 ( 𝒥 ( 𝑤 )) = (Y- Ŷ) 范数 - 反向传播: