XiaoMi-AI文件搜索系统
World File Search System变压器

Navformer:用于机器人目标的变压器体系结构 -
摘要 - 在未知的混乱和动态环境(例如灾难场景)中,移动机器人需要执行目标驱动导航才能找到感兴趣的人或对象,其中提供的有关这些目标的唯一信息是单个目标的图像。在本文中,我们介绍了Navformer,这是一种新颖的端到端变压器体系结构,为在未知和动态环境中为机器人目标驱动导航而开发。Navformer利用两者的优势1)变压器进行顺序数据处理和2)自我监督学习(SSL),以进行视觉表示,以推理空间布局并在动态设置中执行避免碰撞。该体系结构唯一地结合了由静态编码器组成的双视觉编码器,用于提取空间推理的不变环境特征,以及用于避免动态障碍物的一般编码器。主要的机器人导航任务分解为两个子任务以进行训练:单个机器人勘探和多机器人碰撞避免。我们执行交叉任务培训,以使学习技能转移到复杂的主要导航任务中。模拟实验表明,Navformer可以在不同的未知环境中有效浏览移动机器人,从而优于现有的最新方法。进行了全面的消融研究,以评估Navformer的主要设计选择的影响。此外,现实世界实验验证了Navformer的普遍性。索引术语 - 动态和未知环境,图像引导搜索,目标驱动机器人导航。

复合单词变压器:学习构成全...
要将神经序列模型(例如变形金刚)应用于音乐发电任务,必须通过一系列有限的代币来代表一段音乐。这样的词汇通常涉及各种类型的令牌。例如,要描述音符,一个人需要单独的令牌来指示音符的音高,持续时间,速度(动态)和放置时间(起始时间)。虽然不同类型的令牌可能具有不同的适当性,但现有模型通常以与自然语言建模单词相同的方式对待它们。在本文中,我们提出了一种概念上不同的方法,该方法明确考虑了令牌的类型,例如注释类型和度量标准类型。,我们提出了一种新的变压器解码器 - 使用不同的馈送头来建模不同类型的kens。通过扩展压缩技巧,我们通过对相邻令牌进行分组,大大降低了令牌序列的长度,从而将一段音乐转换为一系列复合单词。我们表明,在动态有向超图中,可以将结果模型视为学习者。,我们采用它来学会创作全面的长度长度(每首歌曲最多涉及10k个个人to-kens)的表现力的流行钢琴音乐,无论是有条件地和无条件的)。我们的实验表明,与最先进的模型相比,所提出的模型在训练时收敛了5至10倍(即,在一天的GPU上,在具有11 GB内存的单个GPU上),并且在生成的音乐中具有可比的质量。

从卫星图像中基于变压器的雷达复合材料的现象
摘要:天气雷达数据对于现象和数值天气预测模型的组成部分至关重要。虽然天气雷达数据以高分辨率提供了有价值的信息,但其基于地面的性质限制了其供应能力,这阻碍了大规模应用。相比之下,气象卫星覆盖了较大的域,但具有更粗糙的重置。然而,随着数据驱动方法和地球静止卫星上的现代传感器的快速发展,新的机会正在出现,以弥合地面和太空观测之间的差距,最终导致更熟练的天气预测以高准确性。在这里,我们提出了一个基于变压器的模型,用于使用最多2小时的卫星数据进行基于接地的雷达图像序列。预测在不同的天气现象下发生的雷达场,并显示出鲁棒性,以防止快速生长/衰减的领域和复杂的场结构。模型解释表明,以10.3 m m(C13)为中心的红外通道包含所有天气条件的熟练信息,而闪电数据在恶劣天气条件下的相对特征最为重要,尤其是在较短的交货时间。该模型可以支持在大型范围内进行降水,而无需明确需要雷达塔,增强数值天气预测和水文模型,并为数据筛选区域提供雷达代理。此外,开源框架有助于朝着操作数据驱动的NOWCASTING的进步。

56F80x 旋转变压器驱动器和硬件接口
旋转变压器驱动器利用 56F80x 的两个 ADC 通道和一个定时器。在此特定应用中,必须将 ADC 通道配置为同时采样正弦和余弦信号。定时器提供方波信号的生成。该信号进一步由外部硬件调节为便于激励旋转变压器的形式。控制器根据旋转变压器测量的正弦和余弦信号估计转子轴的实际角度。然而,控制器不仅专用于实现 R/D 转换,因此旋转变压器的软件驱动程序必须以能够链接并在现有应用程序(例如 PMSM 矢量控制应用程序)中运行的方式进行设计。

使用带有 PLC 的变压器自动负载分配...
1 浦那 COEP 科技大学电气工程系主任 2、3、4、5 浦那 COEP 科技大学电气工程系学生 摘要:在改进电力系统中变压器的工作方式方面,可编程逻辑控制器 (PLC) 变得非常重要。它们帮助我们管理电流,确保电网保持稳定可靠。本摘要讨论了如何使用 PLC 专门在变压器之间共享负载,解释了这为何重要以及它的工作原理。PLC 就像智能负载共享系统背后的大脑。它们使用复杂的指令并快速处理数据以确保变压器均匀分配负载。使用 PLC 使我们能够密切关注电力的分配方式并根据需要进行调整,尤其是在电力需求上升或下降时。基于 PLC 的负载共享通过将传感器、开关和通信工具连接在一起来工作。这让 PLC 能够收集有关用电量和系统状况等信息的实时信息。有了这些数据,他们就可以做出明智的决定,决定如何平衡变压器之间的负载。为了使基于 PLC 的负载共享工作良好,我们需要创建适合每个变压器需求的自定义指令。这些指令告诉 PLC 如何读取数据、预测用电量变化并相应地调整负载共享。PLC 还可以帮助系统的不同部分顺利地相互通信。这意味着它们可以轻松共享信息并协同工作以平衡整个电网的负载。使用强大的通信工具,PLC 可以创建一个统一的系统来监控和控制变压器的工作方式,无论它们位于何处。PLC 的一大优点是它们非常灵活。它们可以调整以适应不同情况和不同类型的电力系统。这意味着基于 PLC 的负载共享可以轻松添加到现有电网中,从而更容易处理电力需求的变化和增长。简而言之,使用 PLC 在变压器之间共享负载是使电力系统更好地运行的一种明智方法。它们帮助我们密切关注事物,根据需要进行调整,并确保一切顺利运行,从而提高整个系统的效率、可靠性和弹性。关键词:PLC、继电器、远程控制、

3D猫:脑肿瘤的通道注意变压器
摘要 - 脑肿瘤诊断是一项具有挑战性的任务,但对于计划治疗以停止或减慢肿瘤的生长至关重要。在过去的十年中,卷积神经网络(CNN)在医学图像中肿瘤的自动分割中的高性能急剧增加。最近,与CNN相比,视觉变压器(VIT)已成为医学成像的稳健性和效率的核心重点。在本文中,我们提出了一个新颖的3D变压器,称为3D catbrats,用于基于最先进的SWIN变压器的磁共振图像(MRIS),用于使用残留块和通道注意模块的最先进的SWIN变压器进行磁共振图像(MRI)。在Brats 2021数据集上评估了所提出的方法,并实现了在验证阶段超过当前最新方法的平均骰子相似性系数(DSC)的定量度量。索引项 - CNN,变形金刚,VIT,语义段

使用 ARDIOUNO 进行变压器负载剪切
变压器是一种在静止状态下将能量从一个级别转换为另一个级别的设备。本项目的目的是通过使用负载共享来防止变压器过载。变压器过载时,其效率会降低,绕组会变热,甚至可能烧毁。负载共享的结果是,变压器受到保护。这将通过使用微控制器将另一个变压器与 Arduino 并联来实现。两个控制器都将第一个变压器上的负载与参考值进行比较。当负载超过参考值时,第二个变压器将共享剩余负载。如果负载超过两个变压器的额定值,系统将关闭。每当通过 GSM 接收到通信时,操作员都会收到它。

用于患者的局部不变散射变压器......
基于连续脑电图 (cEEG) 的视觉频谱表示的患者独立癫痫活动检测已广泛用于诊断癫痫。然而,由于不同受试者、通道和时间点的细微变化,精确检测仍然是一项相当大的挑战。因此,捕获与高频纹理信息相关的脑电图模式的细粒度、判别性特征尚未解决。在这项工作中,我们提出了散射变压器 (ScatterFormer),这是一种基于不变散射变换的分层变压器,它特别关注细微特征。特别是,解缠结的频率感知注意力 (FAA) 使变压器能够捕获具有临床信息的高频成分,基于多通道脑电图信号的视觉编码提供了一种新的临床可解释性。在两个不同的癫痫样检测任务上的评估证明了我们方法的有效性。我们提出的模型在 Rolandic 癫痫患者中实现了 98.14% 和 96.39% 的中位 AUCROC 和准确率。在新生儿癫痫发作检测基准上,其平均 AUCROC 比最先进的方法高出 9%。
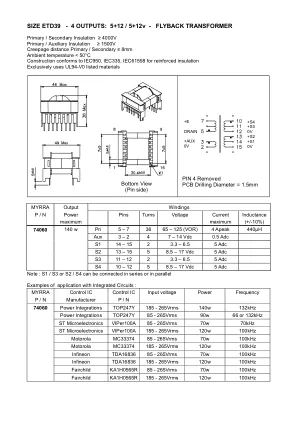
4 输出:5+12 / 5+12v - 反激变压器
尺寸 ETD39 - 4 输出:5+12 / 5+12v - 反激变压器 初级/次级绝缘 ≥ 4000V 初级/辅助绝缘 ≥ 1500V 初级/次级爬电距离 ≥ 8mm 环境温度 < 50°C 结构符合 IEC950、IEC335、IEC61558 加强绝缘标准 仅使用 UL94-V0 列出的材料
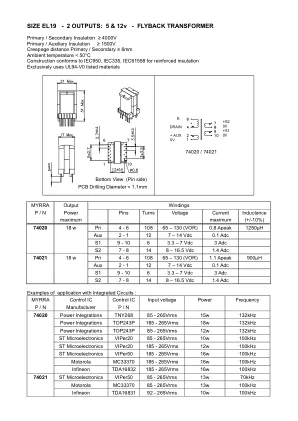
2 输出:5V 和 12V - 反激变压器
S1 9 - 10 6 3.3 – 7 Vdc 3 Adc S2 7 - 8 14 8 – 16.5 Vdc 1.4 Adc 74021 18 w Pri 4 - 6 108 65 – 130 (VOR) 1.1 Apeak 900µH Aux 2 - 1 12 7 – 14 Vdc 0.1 Adc S1 9 - 10 6 3.3 – 7 Vdc 3 Adc S2 7 - 8 14 8 – 16.5 Vdc 1.4 Adc 集成电路应用示例:MYRRA 控制 IC 控制 IC 输入电压 电源频率