XiaoMi-AI文件搜索系统
World File Search System变压器

SM91872AL BMS变压器
其数据表中列出的Bourns®产品的特征和参数是基于实验室条件,并且有关产品适用于某些类型应用程序的陈述是基于Bourns对通用应用中典型要求的了解。用户应用程序中Bourns®产品的特性和参数可能因(i)Bourns®产品与用户应用程序中其他组件的组合而变化,或者(II)用户应用程序本身的环境。Bourns®产品的特性和参数在不同的应用中也可以并且确实有所不同,并且实际性能可能会随着时间而变化。用户应始终在其特定设备和应用程序中验证Bourns®产品的实际性能,并就其在其设备或应用中设计的额外测试保证金的数量做出独立的判断,以补偿实验室和现实世界中的差异。

使用基于变压器的神经网络
摘要:在这项研究中,我们引入了一种新型的基于变压器的神经网络(DTNN)模型,用于预测锂离子电池的剩余使用寿命(RUL)。所提出的DTNN模型在准确性和可靠性方面显着优于传统的机器学习模型和其他深度学习档案。特别是,DTNN达到0.991的R 2值,平均百分比误差(MAPE)为0.632%,绝对RUL误差为3.2,比其他模型(例如随机森林(RF),决策树(DT),多层perceptron(MLP),REN NERTEN(RN),REN NERTIAL NERTIST(RN NERTIRER NERTIAL(RN))(RN)(rn)(RF)(RF)(RN)(RNN)(RNN)(RNN)(RNN NEFT)(RN NORN NERTER),RNN NOVERRENT NERTER,长期(RN)复发单元(GRU),Dual-LSTM和Decransformer。这些结果突出了DTNN模型在为电池RUL提供精确可靠的预测方面的效率,这使其成为各种应用中电池管理系统的有前途的工具。

SM91243L功率变压器
其数据表中列出的Bourns®产品的特征和参数是基于实验室条件,并且有关产品适用于某些类型应用程序的陈述是基于Bourns对通用应用中典型要求的了解。用户应用程序中Bourns®产品的特性和参数可能因(i)Bourns®产品与用户应用程序中其他组件的组合而变化,或者(II)用户应用程序本身的环境。Bourns®产品的特性和参数在不同的应用中也可以并且确实有所不同,并且实际性能可能会随着时间而变化。用户应始终在其特定设备和应用程序中验证Bourns®产品的实际性能,并就其在其设备或应用中设计的额外测试保证金的数量做出独立的判断,以补偿实验室和现实世界中的差异。

基于视觉变压器的图像分类
这项研究通过使用视觉变压器(VIT)体系结构引入了一种创新的图像分类方法。实际上,视力传输(VIT)已成为用于图像分析任务的卷积神经网络(CNN)的有前途的选择,提供可扩展性和提高的性能。Vision Transformer VIT模型能够捕获图像元素之间的全局规定和链接。这导致了特征表示的增强。当VIT模型在不同模型上训练时,它表现出在不同的IMEGE类别中的强大分类功能。VIT直接处理图像贴片的能力而不依赖空间层次结构,简化了分类过程并证明了计算效率。在这项研究中,我们使用TensorFlow提出了Python的启动,以采用(VIT)模型进行图像分类。将使用四类动物,例如(牛,狗,马和绵羊),用于分类。(VIT)模型用于从图像中提取微不足道的特征,并添加分类头以预测类标签。该模型在CIFAR-10数据集上进行了训练,并评估了准确性和性能。这项研究的发现不仅会揭示视觉变压器模型在图像分类任务中的有效性,而且还可以作为解决复杂的视觉识别问题的强大工具的潜力。这项研究通过引入一种新颖的方法来填补现有的知识空白,该方法挑战了计算机视觉领域的传统卷积神经网络(CNN)。虽然CNN是图像分类任务的主要体系结构,但它们在捕获图像数据中的长距离依赖性方面存在局限性,并且需要手工设计的层次层次特征提取。关键字

可再生能源收集器变压器
PTI Transformers LP,加拿大马尼托巴省温尼伯 ORCID:1. 0000-0002-1216-6513 doi:10.15199/48.2024.11.39 可再生能源收集器变压器摘要。太阳能发电站或风电场中的可再生能源集电变压器 (RCT) 将集电系统的电压转换为传输级电压。由于主要目标是提高电压,RCT 在此功能上与发电机升压 (GSU) 变压器相似,但有一些设计特点和操作特性使这些装置独一无二,例如典型的绕组配置星形-星形-埋置三角形,低压绕组通常通过中性点接地电抗器接地。设计必须考虑低压电流和电压中的谐波。抽象的。光伏站或风电场中的可再生能源站(RES站)的主变压器将来自主系统的电压转换为输电级电压。由于主要目的是提高电压,RCT 在这方面的功能与 GSU 变压器相似,但有一些设计特点和操作特性使这些装置独一无二,例如典型的三角形-星形绕组配置,低压绕组通常通过中性接地电感器接地。设计必须考虑低压电流和电压中谐波的存在。 (可再生能源发电站主变压器) 关键词:电力变压器、可再生能源发电站、过电压、谐波。可再生能源集电变压器 (RCT) 是一种专用电力变压器,它在太阳能发电站或风力发电场中,将电站集电系统的电压(通常为 34.5 kV)转换为传输电压水平,通常范围从 138 到 345 kV 或 500 kV。可再生能源站中 RCT 的位置如图 1 所示。虽然直接连接到逆变器的小功率变压器在论文和标准 [1, 2] 中有很好的描述,但集电变压器在已发表的参考文献或标准中并没有很好的描述。因此,本文的目标就是填补这一空白。图 1。集电变压器放置在集电母线和传输线之间;来自参考文献。 [1] 大多数可再生能源可能会出于不同的原因使用多个集电变压器,例如为了限制其物理尺寸(特别是为了运输或由于场地限制),或者利用电站设计理念的特点,例如分配负载或在故障期间在电站各部分之间转移负载,或紧急加载。由于 RCT 的主要目的是提高电压,因此该变压器的功能与发电机升压 (GSU) 变压器类似。然而,RCT 与 GSU 有许多区别,包括:(i)典型的绕组配置为星形-星形-埋地三角形,而 GSU 绕组采用星形-三角形连接,(ii)RCT 的低压绕组通常通过中性点接地电抗器 (NGR) 接地,而高压绕组

带装饰的食品变压器、开关电源变压器、功率铁氧体变压器、开关电源反激变压器系列、EMI 抑制共模电感器、环形电感器、EMI 抑制调光电感器、鼓芯电感器、电流变压器系列、脉冲变压器系列、电力线通信耦合变压器
I 反激变压器系列 I 变压器/控制电路交叉参考列表 I 1 至 9 W EE 16 74090 – 74091 – 74092 – 74093 – 74094 – 74095 I 1 至 6 W EE 16 74000 – 74001 – 74002 – 74003 I 6 至 12 W EE 16 74010 – 74014 – 74015 I 10 至 18 W EL 19 74020 – 74021 – 74023 I 12 至 24 W EF 20 74080 – 74081 – 74082 I 15 至 30 W EE 25 74030 – 74032 I 35 至 60 W ETD 29 74040 I 35 至 60 W ERL 28 74043 I 60 至 90 W ETD 34 74050 I 70 至 140 W ETD 39 74060 I 120 至 180 W ETD 44 74070

配电变压器节能标准
1 本文件中对 EPCA 的所有引用均指经《2020 年能源法案》(Pub. L. 116-260,2020 年 12 月 27 日)修订的法规,该法规反映了影响 EPCA A 部分和 A-1 部分的最新法定修订。2 出于编辑原因,在美国法典编纂时,B 部分被重新指定为 A 部分。3 出于编辑原因,在美国法典编纂时,C 部分被重新指定为 A-1 部分。虽然 EPCA 在 A 部分和 A-1 部分都包含有关配电变压器的规定,但为了管理方便,DOE 已在 10 CFR 第 431 部分《某些商业和工业设备的能源效率计划》中制定了配电变压器的测试程序和标准。DOE 在本文件中通常将配电变压器称为“涵盖设备”。

配电变压器节能标准
在 2007 年制定配电变压器规则的过程中,《2005 年能源政策法案》(EPACT 2005),Pub.L. 109–58 修订了 EPCA,为低压干式 (LVDT) 配电变压器制定了标准。(EPACT 2005,第 135(c) 节;编纂于 42 U.S.C.6295(y))因此,DOE 将这些变压器从该规则制定范围中移除。72 FR at 58191(2007 年 10 月 12 日)。2007 年最终规则公布后,某些当事人向美国第二和第九巡回上诉法院提交了复审申请,对最终规则提出质疑,并且允许其他几个当事人介入支持这些申请。(所有这些当事人在下文中统称为“请愿人”。)请愿人声称,在制定配电变压器的节能标准时,DOE 没有遵守 EPCA 和 1969 年国家环境政策法案 (NEPA) 的某些适用规定,42 U.S.C.4321 等。DOE 和请愿人随后达成和解协议以解决该诉讼。和解协议概述了加快

IS 2026-3 (2009): 电力变压器第
如果变压器不满足其测试要求,并且故障发生在套管中,则允许暂时用另一个套管替换该套管,并继续对变压器进行测试直至完成,无需延迟。在进行局部放电测量的测试时,会出现一种特殊情况,某些类型的常用高压套管会因为其介电体中的局部放电水平相对较高而造成困难。当买方指定此类套管时,允许在变压器测试期间将其更换为无局部放电类型的套管,参见附件 A。
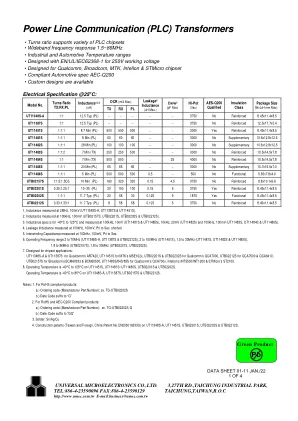
电力线通信 (PLC) 变压器
1.8 至 86MHz (UTB02157S), 1.8 至 30MHz (UTB02201S, UTB02202S)。7. 专为芯片组应用而设计:UT11348S-A 和 UT11387S 用于 Qualcomm 的 AR7420,UT11451S 用于 MTK 的 MSE102x,UTB02201S 和 UTB02202S 用于 Qualcomm 的 QCA7000,UTB02212S 用于 QCA7500 和 QCA6410,UTB02157S 用于 Broadcom 的 BCM60333 和 BCM60500,UT11483S/84S/85S 用于 Qualcomm 的 QCA700x、Intellon 的 INT5500/INT1200 和 STMicro 的 ST2100。