XiaoMi-AI文件搜索系统
World File Search System司空见惯
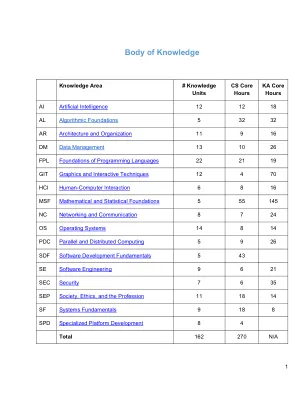
知识体
序言人工智能(AI)研究了难以解决传统算法方法难以解决的问题。这些问题通常让人想起被认为需要人类智能的问题,而由此产生的AI解决方案策略通常会概括为问题类别。AI技术现在在计算,支持电子邮件,社交媒体,摄影,金融市场和智能虚拟助手(例如Siri,Alexa)等日常应用中普遍存在。这些技术也用于对自主剂的设计和分析,这些自主剂感知其环境并与之合理地相互作用,例如自动驾驶汽车和其他机器人。传统上,AI包括符号和亚符号方法的混合。它提供的解决方案取决于一系列一系列一般和专业知识表示方案,解决问题机制和优化技术。这些方法涉及感知(例如语音识别,自然语言理解,计算机视觉),解决问题(例如搜索,计划,优化),产生(例如叙事,对话,对话,图像,图像,模型,模型),代理(例如,机器人技术,任务,任务 - 自动化,控制,控制)以及支持它们(E。e.G. g。机器学习可以在这些方面中的每个方面使用,甚至可以在所有这些方面端对端使用。在过去的十年中,“人工智能”一词在企业,新闻文章和日常对话中已变得司空见惯,这在很大程度上受到一系列高影响力的机器学习应用的驱动。人工智能的研究使学生准备确定何时适合给定问题的AI方法,确定适当的表示和推理机制,实施它们,并就表现及其更广泛的社会影响进行评估。通过大型数据集的广泛可用性,增加的计算能力和算法改进,使这些进步成为可能。尤其是,通过大型数据集优化自动学习的表示形式已经有了转变。由此产生的进步将诸如“神经网络”和“深度学习”等术语纳入了日常白话。企业现在将基于AI的解决方案宣传为其服务的增值,因此“人工智能”现在既是技术术语又是营销流行语。其他学科,例如生物学,艺术,建筑和金融,越来越多地利用AI技术来解决其学科中的问题。在我们历史上,更广泛的人口首次可以使用复杂的AI驱动工具,包括从及时的工具或诗歌中生成及时的诗歌,描述的艺术品以及描绘真实人的虚假照片或视频。AI技术现在已广泛用于股票交易,策划我们的新闻和社交媒体供稿,对求职者的自动评估,医疗状况的检测以及通过累犯预测影响监狱判决。因此,AI技术可以在开发和应用它时具有重大的社会影响和道德考虑。
引用本文:Ben Williamson & Rebecca Eynon (2020):教育、学习、媒体和技术领域人工智能的历史线索、缺失环节和未来方向,DOI:10.1080/17439884.2020.1798995
人工智能已成为日常生活中司空见惯的事情。通过网络获取信息、消费新闻和娱乐、金融市场的表现、监控系统识别个人的方式、驾驶员和行人如何导航以及公民如何领取福利金,这些只是人工智能渗透到人类生活、社会机构、文化实践以及政治和经济进程中的无数例子。用于实现人工智能的算法技术的影响是深远的,激发了相当多的时代炒作和希望,以及反乌托邦的恐惧,尽管它们在技术专家的社交网络之外仍然很大程度上不透明且理解甚少(Rieder 2020)。然而,人工智能的深刻社会和伦理影响正变得越来越明显,并成为人们关注的重要对象。人工智能是争议的焦点,例如,工作场所和公共服务的自动化;算法形式的偏见和歧视;不平等和劣势的自动再现;以数据为中心的监视和算法分析制度;无视数据保护和隐私;政治和商业微目标定位;以及科技公司控制和塑造其渗透的所有部门和空间的权力,从整个城市和公民群体到特定的集体、个人甚至人体(Whittaker 等人,2018 年)。已经制定了许多道德框架和专业行为准则,试图减轻人工智能在社会中的潜在危险和风险,尽管关于它们对公司的具体影响或这些框架和准则如何保护商业利益的重要争论仍然存在(Greene、Hofferman 和 Stark,2019 年)。目前,人工智能在网络、智能手机、社交媒体和通过互联物体和传感器网络在空间中的实例化的历史比最近一些划时代的说法所暗示的要长得多。人工智能的历史至少可以追溯到 20 世纪 40 年代计算机科学和控制论的诞生。 “人工智能”这一术语本身是在 20 世纪 50 年代中期达特茅斯学院的一个项目和研讨会中提出的。从 20 世纪 60 年代到 90 年代,人工智能经历了一段“寒冬”,其研究和开发首先侧重于对人类推理的编码原理进行模拟,然后侧重于“专家系统”,即基于定义的知识库模拟专家的程序性决策过程。2010 年之后,人工智能逐渐以一种新范式回归,不再是模拟人类智能或可编程专家系统,而是能够通过对大量“大数据”进行分类和关联来学习和做出预测的数据处理系统。计算过程包括数据分析、机器学习、神经网络、深度学习和强化学习是大多数当代人工智能的基础。人工智能可能只是一系列统计、数学、计算和数据科学实践和发展的新的总称,它们各自都有复杂且相互交织的谱系,但它也标志着这些历史脉络的独特联系(Schmidhuber 2019 , 2020 )。现代人工智能的重点不是创造计算“超级智能”(“强人工智能”),而是理想情况下致力于开发能够从自身经验中学习、适应变化的机器。

Jibo Kids Copus:儿童机器人的演讲数据集...
1。引言语言和扫盲技能的发展是基础教育的基石。然而,国家对教育进步评估的经验结果强调了现实:美国37%的四年级学生没有证明阅读能力与年级的期望相符(Irwin等人,2022)。扫盲基础是在关键的幼儿园和幼儿园时期建立的,在那里孩子们发展了诸如语音意识和信件知识之类的识字能力(Bus and van Ijzendoorn,1999年)。因此,这些早期发展阶段需要集中注意力和资源来促进语言增长。为了增强学习经验并利用这些进步,在教育空间中使用系统已变得司空见惯(Williams等人,2013年),但技术进步仍然必须解决一个重大障碍:当代的自动语音识别技术的表现不足,任务是为儿童的反应得分(Dutta等人,2022; Yeung and Alwan,2018年)。自动产生的儿童语音转录的容易出错的性质对他们整合到教育应用中构成了重大挑战。,1997; P´aez等。,2007年; Snow等。,2007年)。然而,综合儿童的语音数据库的显着稀缺性仍然存在于该领域,尤其是在纵向数据集中。,2022; Safavi等。,2012年; Yeung and Alwan,2018年)。,2018年; Kory等。研究的重点是幼儿园年龄的儿童强调了该年龄段的专门量身定制ASR系统的必要性,因为在Pre-K和幼儿园水平上开发的语音学和字母知识等识字能力可以支持识字技能的发展(Biemiller和Slonim,Slonim,Slonim,2001; Fishman and Pinkerman,2003; Hart et;这些纵向资源对于调查语言发展和精炼以儿童为中心的自动语音识别和说话者识别系统是无价的(Dutta等人。通过跟踪同一儿童,研究人员可以绘制语言获取的轨迹。这种理解可以指导专门针对儿童言语不断发展的特征的系统和技术的开发。(Yeung和Alwan,2019年)。纵向数据还促进了通过提供有关儿童语音模式如何发展,支持个性化学习环境和儿童手机互动等领域的应用程序的见解,从而促进了专门针对儿童声音的教育应用的发展。要有效地从儿童那里收集数据,研究人员必须设计涉及孩子体验的数据收集机制。社会机器人,具有交互式吸引儿童的能力,具有在临床和教育环境中实施这些数据驱动的见解的巨大潜力(Kanero等人,2013年; Westlund and Breazeal,2015年)。jibo被用来为幼儿园,幼儿园和一年级的儿童管理一系列结构化和半结构化任务。机器人可以促进针对各种目标的有针对性活动,包括评估语音发展和语音习得,以及加强发音技能。利用社会机器人的互动功能,Jibo(Spaulding and Chen,2018年),本文介绍了两年内收集的新颖的儿童演讲数据集。这些任务包括字母和数字标识以及说明任务。数据集的纵向组件,其中一部分参与者返回后续记录,促进了儿童言语中对发展轨迹的分析。作为较大的人类机器人相互作用(HRI)研究的一部分,评估了Yeung等人在课堂环境中社会机器人的有效性。(2019b),Yeung等。(2019a),Tran等。(2020),Johnson等。 (2022b)和Johnson等。 (2022a),本文对数据集的集合进行了全面讨论,包括设计注意事项和记录条件。(2020),Johnson等。(2022b)和Johnson等。(2022a),本文对数据集的集合进行了全面讨论,包括设计注意事项和记录条件。

selscan 2.0:在未经遗传数据中扫描扫描
基于单倍型的摘要统计数据 - 例如IHS(Voight等人2006),NSL(Ferrer-Admetlla等人 2014),XP-EHH(Sabeti等人。 2007)和XP-NSL(Szpiech等人 2021) - 在进化基因组学研究中司空见惯,以确定种群中的最新和持续的阳性选择(例如, Colonna等。 2014,Zoledziewska等。 2015,Ne´de´lec等。 2016,Crawford等。 2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021)。 当适应性等位基因扫描一个人群时,它留下了长期高频单倍型和等位基因附近遗传多样性低的特征模式。 这些统计数据旨在通过总结单倍型纯合性的衰减来捕获这些信号,这是一个距离被推定的区域(IHS和NSL)或两个种群(XP-EHH和XP-NSL)之间的距离。 这些基于单倍型的统计数据非常有力地检测最近的阳性选择(Colonna等人 2014,Zoledziewska等。 2015,Ne´de´lec等。 2016,Crawford等。 2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021),并且两个人群版本甚至可以在很大的参数空间上进行成对的FST扫描(Szpiech等人。 2021)。 此外,基于单倍型的方法也已证明对背景选择是可靠的(Fagny等人。2006),NSL(Ferrer-Admetlla等人2014),XP-EHH(Sabeti等人。 2007)和XP-NSL(Szpiech等人 2021) - 在进化基因组学研究中司空见惯,以确定种群中的最新和持续的阳性选择(例如, Colonna等。 2014,Zoledziewska等。 2015,Ne´de´lec等。 2016,Crawford等。 2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021)。 当适应性等位基因扫描一个人群时,它留下了长期高频单倍型和等位基因附近遗传多样性低的特征模式。 这些统计数据旨在通过总结单倍型纯合性的衰减来捕获这些信号,这是一个距离被推定的区域(IHS和NSL)或两个种群(XP-EHH和XP-NSL)之间的距离。 这些基于单倍型的统计数据非常有力地检测最近的阳性选择(Colonna等人 2014,Zoledziewska等。 2015,Ne´de´lec等。 2016,Crawford等。 2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021),并且两个人群版本甚至可以在很大的参数空间上进行成对的FST扫描(Szpiech等人。 2021)。 此外,基于单倍型的方法也已证明对背景选择是可靠的(Fagny等人。2014),XP-EHH(Sabeti等人。2007)和XP-NSL(Szpiech等人2021) - 在进化基因组学研究中司空见惯,以确定种群中的最新和持续的阳性选择(例如,Colonna等。2014,Zoledziewska等。 2015,Ne´de´lec等。 2016,Crawford等。 2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021)。 当适应性等位基因扫描一个人群时,它留下了长期高频单倍型和等位基因附近遗传多样性低的特征模式。 这些统计数据旨在通过总结单倍型纯合性的衰减来捕获这些信号,这是一个距离被推定的区域(IHS和NSL)或两个种群(XP-EHH和XP-NSL)之间的距离。 这些基于单倍型的统计数据非常有力地检测最近的阳性选择(Colonna等人 2014,Zoledziewska等。 2015,Ne´de´lec等。 2016,Crawford等。 2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021),并且两个人群版本甚至可以在很大的参数空间上进行成对的FST扫描(Szpiech等人。 2021)。 此外,基于单倍型的方法也已证明对背景选择是可靠的(Fagny等人。2014,Zoledziewska等。2015,Ne´de´lec等。 2016,Crawford等。 2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021)。 当适应性等位基因扫描一个人群时,它留下了长期高频单倍型和等位基因附近遗传多样性低的特征模式。 这些统计数据旨在通过总结单倍型纯合性的衰减来捕获这些信号,这是一个距离被推定的区域(IHS和NSL)或两个种群(XP-EHH和XP-NSL)之间的距离。 这些基于单倍型的统计数据非常有力地检测最近的阳性选择(Colonna等人 2014,Zoledziewska等。 2015,Ne´de´lec等。 2016,Crawford等。 2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021),并且两个人群版本甚至可以在很大的参数空间上进行成对的FST扫描(Szpiech等人。 2021)。 此外,基于单倍型的方法也已证明对背景选择是可靠的(Fagny等人。2015,Ne´de´lec等。2016,Crawford等。 2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021)。 当适应性等位基因扫描一个人群时,它留下了长期高频单倍型和等位基因附近遗传多样性低的特征模式。 这些统计数据旨在通过总结单倍型纯合性的衰减来捕获这些信号,这是一个距离被推定的区域(IHS和NSL)或两个种群(XP-EHH和XP-NSL)之间的距离。 这些基于单倍型的统计数据非常有力地检测最近的阳性选择(Colonna等人 2014,Zoledziewska等。 2015,Ne´de´lec等。 2016,Crawford等。 2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021),并且两个人群版本甚至可以在很大的参数空间上进行成对的FST扫描(Szpiech等人。 2021)。 此外,基于单倍型的方法也已证明对背景选择是可靠的(Fagny等人。2016,Crawford等。2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021)。 当适应性等位基因扫描一个人群时,它留下了长期高频单倍型和等位基因附近遗传多样性低的特征模式。 这些统计数据旨在通过总结单倍型纯合性的衰减来捕获这些信号,这是一个距离被推定的区域(IHS和NSL)或两个种群(XP-EHH和XP-NSL)之间的距离。 这些基于单倍型的统计数据非常有力地检测最近的阳性选择(Colonna等人 2014,Zoledziewska等。 2015,Ne´de´lec等。 2016,Crawford等。 2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021),并且两个人群版本甚至可以在很大的参数空间上进行成对的FST扫描(Szpiech等人。 2021)。 此外,基于单倍型的方法也已证明对背景选择是可靠的(Fagny等人。2017,Meier等。2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021)。 当适应性等位基因扫描一个人群时,它留下了长期高频单倍型和等位基因附近遗传多样性低的特征模式。 这些统计数据旨在通过总结单倍型纯合性的衰减来捕获这些信号,这是一个距离被推定的区域(IHS和NSL)或两个种群(XP-EHH和XP-NSL)之间的距离。 这些基于单倍型的统计数据非常有力地检测最近的阳性选择(Colonna等人 2014,Zoledziewska等。 2015,Ne´de´lec等。 2016,Crawford等。 2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021),并且两个人群版本甚至可以在很大的参数空间上进行成对的FST扫描(Szpiech等人。 2021)。 此外,基于单倍型的方法也已证明对背景选择是可靠的(Fagny等人。2018,Lu等。2019,Zhang等。 2020,Salmo´n等。 2021)。 当适应性等位基因扫描一个人群时,它留下了长期高频单倍型和等位基因附近遗传多样性低的特征模式。 这些统计数据旨在通过总结单倍型纯合性的衰减来捕获这些信号,这是一个距离被推定的区域(IHS和NSL)或两个种群(XP-EHH和XP-NSL)之间的距离。 这些基于单倍型的统计数据非常有力地检测最近的阳性选择(Colonna等人 2014,Zoledziewska等。 2015,Ne´de´lec等。 2016,Crawford等。 2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021),并且两个人群版本甚至可以在很大的参数空间上进行成对的FST扫描(Szpiech等人。 2021)。 此外,基于单倍型的方法也已证明对背景选择是可靠的(Fagny等人。2019,Zhang等。2020,Salmo´n等。2021)。当适应性等位基因扫描一个人群时,它留下了长期高频单倍型和等位基因附近遗传多样性低的特征模式。这些统计数据旨在通过总结单倍型纯合性的衰减来捕获这些信号,这是一个距离被推定的区域(IHS和NSL)或两个种群(XP-EHH和XP-NSL)之间的距离。这些基于单倍型的统计数据非常有力地检测最近的阳性选择(Colonna等人2014,Zoledziewska等。 2015,Ne´de´lec等。 2016,Crawford等。 2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021),并且两个人群版本甚至可以在很大的参数空间上进行成对的FST扫描(Szpiech等人。 2021)。 此外,基于单倍型的方法也已证明对背景选择是可靠的(Fagny等人。2014,Zoledziewska等。2015,Ne´de´lec等。 2016,Crawford等。 2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021),并且两个人群版本甚至可以在很大的参数空间上进行成对的FST扫描(Szpiech等人。 2021)。 此外,基于单倍型的方法也已证明对背景选择是可靠的(Fagny等人。2015,Ne´de´lec等。2016,Crawford等。 2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021),并且两个人群版本甚至可以在很大的参数空间上进行成对的FST扫描(Szpiech等人。 2021)。 此外,基于单倍型的方法也已证明对背景选择是可靠的(Fagny等人。2016,Crawford等。2017,Meier等。 2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021),并且两个人群版本甚至可以在很大的参数空间上进行成对的FST扫描(Szpiech等人。 2021)。 此外,基于单倍型的方法也已证明对背景选择是可靠的(Fagny等人。2017,Meier等。2018,Lu等。 2019,Zhang等。 2020,Salmo´n等。 2021),并且两个人群版本甚至可以在很大的参数空间上进行成对的FST扫描(Szpiech等人。 2021)。 此外,基于单倍型的方法也已证明对背景选择是可靠的(Fagny等人。2018,Lu等。2019,Zhang等。 2020,Salmo´n等。 2021),并且两个人群版本甚至可以在很大的参数空间上进行成对的FST扫描(Szpiech等人。2019,Zhang等。2020,Salmo´n等。2021),并且两个人群版本甚至可以在很大的参数空间上进行成对的FST扫描(Szpiech等人。2021)。此外,基于单倍型的方法也已证明对背景选择是可靠的(Fagny等人。2014,Schrider 2020)。 然而,这些统计数据中的每一个都认为单倍型相是已知或据估计的。 作为非模型生物的基因组测序数据的产生正在变得常规(Ellegren 2014),有很多很大的机会来研究整个生命之树的最新适应性(例如, Campagna和Toews 2022)。 但是,这些生物/种群通常没有特征良好的人口历史或重组率2014,Schrider 2020)。然而,这些统计数据中的每一个都认为单倍型相是已知或据估计的。作为非模型生物的基因组测序数据的产生正在变得常规(Ellegren 2014),有很多很大的机会来研究整个生命之树的最新适应性(例如,Campagna和Toews 2022)。但是,这些生物/种群通常没有特征良好的人口历史或重组率