XiaoMi-AI文件搜索系统
World File Search System命令行

数据简介 - X-CUBE-AI - STM32Cube 的人工智能 (AI) 软件扩展
STM32Cube 是意法半导体的一项原创计划,旨在通过减少开发工作量、时间和成本来显著提高设计人员的工作效率。STM32Cube 涵盖整个 STM32 产品组合。STM32Cube 包括: • 一套用户友好的软件开发工具,涵盖从构思到实现的项目开发,其中包括: – STM32CubeMX,一种图形化软件配置工具,允许使用图形向导自动生成 C 初始化代码 – STM32CubeIDE,一种集外设配置、代码生成、代码编译和调试功能于一体的开发工具 – STM32CubeProgrammer ( STM32CubeProg ),一种提供图形和命令行版本的编程工具 – STM32CubeMonitor ( STM32CubeMonitor 、 STM32CubeMonPwr 、 STM32CubeMonRF 、 STM32CubeMonUCPD ) 强大的监控工具,可实时微调 STM32 应用程序的行为和性能 • STM32Cube MCU 和 MPU 包,针对每个微控制器和微处理器系列的综合嵌入式软件平台(例如用于STM32F7 系列),其中包括: – STM32Cube 硬件抽象层(HAL),确保在 STM32 产品组合中实现最大可移植性 – STM32Cube 低层 API,确保最佳性能和占用空间,同时用户对硬件具有高度控制权 – 一组一致的中间件组件,如 RTOS、USB、FAT 文件系统、图形和 TCP/IP – 所有嵌入式软件实用程序,带有全套外设和应用示例 • STM32Cube 扩展包,其中包含嵌入式软件组件,可补充 STM32Cube MCU 和 MPU 包的功能,具有: – 中间件扩展和应用层 – 在某些特定的 STMicroelectronics 开发板上运行的示例

使用GREP查找并计算...
简介:GREP是一种命令行工具,用于搜索特定的字符字符串。它为您提供包含您要寻找的字符串的文件中的行。它可以将结果打印到屏幕上或将其保存在新文件中。- 查看底漆序列并将其保存到新文件中:grep -s'taaacttcagggtgaccaaaaaaaaatca'query_file.file.fasta> output1.fasta此命令在文件query_file.fasta中查找所涉及的序列,并将其保存到uptum1.fasta中。GREP中的-s选项用于抑制有关不存在或不可读取文件的错误消息。当您将-s与GREP一起使用时,它会默默地忽略这些错误,而不是显示它们。- 将先前的线与查询行伸入一个新文件中:添加“ -b 1”使您可以将上一行带有包含所讨论的字符串的行。这对于获取FASTA文件的DNA序列和标题线很有用。grep -b 1 -s'taaacttcaggggggggggtgaccaaaaaaatca'query_file.fasta> output1.fasta -fasta -fasta -cousting with Grep:GREP也可以用于计数。例如:grep -c'taaacttcaggggggtgaccaaaaaaaatca'infile.fasta计数其中有多少个这些序列字符串出现在infile.fasta中。- 搜索多种模式:您还可以使用GREP在同一命令中找到作为一组模式。GREP将打印包含您指定的任何模式中的任何一种的行。为此,将其运行如下:三个(OR)的任何一个:GREP'tatter1 | pattern2 | pattern3'fileName所有三个模式(和)grep'tatter 1'fileName | GREP'pattern2'| grep'pattern3' - 在或示例中| |它代表或示例中或示例中,它将输出从一个命令传输到另一个命令。

带内核的量子优势探索者 (QuASK)
摘要 利用量子信息的特性来造福机器学习模型可能是量子计算领域最活跃的研究领域。这种兴趣支持了多种软件框架(例如 Qiskit、Pennylane、Braket)的开发,以实现、模拟和执行量子算法。它们中的大多数允许我们定义量子电路、运行基本量子算法并访问低级原语,具体取决于此类软件应该运行的硬件。对于大多数实验,这些框架必须手动集成到更大的机器学习软件管道中。研究人员负责了解不同的软件包,通过开发长代码脚本将它们集成起来,分析结果并生成图表。长代码通常会导致错误的应用程序,因为平均错误数量与程序长度成正比。此外,由于需要熟悉代码脚本中涉及的所有不同软件框架,其他研究人员将很难理解和重现实验。我们提出了 QuASK,这是一个用 Python 编写的开源量子机器学习框架,可帮助研究人员进行实验,特别关注量子核技术。QuASK 可用作命令行工具来下载数据集、预处理数据集、量子机器学习例程、分析和可视化结果。QuASK 实现了大多数最先进的算法,通过量子核来分析数据,并可以使用投影核、(梯度下降)可训练量子核和结构优化的量子核。我们的框架还可以用作库并集成到现有软件中,从而最大限度地提高代码重用率。

Anchorna:通过保守的锚固区域的完整病毒基因组对齐
动机:由于诸如长序列,大插入/缺失(跨越了几种100个核苷酸),大数量序列,序列差异和高计算复杂性,例如在二级结构预测的上下文中,因此全病毒基因组的多序列比对可能具有挑战性。标准比对方法通常会面临这些问题,尤其是在处理高度可变的序列或对选定子序列需要特定的系统发育分析时。我们提出了基于Python的命令行工具Anchorna,旨在在编码序列中识别保守区域或锚定。这些锚定定义分裂位置,指导复杂病毒基因组的比对,包括具有重要二级结构的那些。AnchORNA通过专注于这些关键的保守区域来提高全基因组对齐的准确性和效率。在设计培养在病毒家族中的底漆时,提出的方法特别有用。结果:AnchORNA引导的对准与3个对齐程序的结果进行了比较。利用55个代表性的Pestivirus基因组的数据集,AnchORNA确定了56个锚点,对于指导对齐过程至关重要。这些锚的合并导致了所有测试的对齐工具的显着改进,突出了Anchorna在增强对齐质量方面的有效性,尤其是在复杂的病毒基因组中。可用性:Anchorna可根据MIT许可在GitHub上的MIT许可证上,网址为https://github.com/rnajena/anchorna,并在Zenodo上存档。该软件包包含一个带有Pestivirus数据集的教程,并且与支持Python的所有平台兼容。

操作系统讲稿...
1. 引导 引导是启动计算机的过程,操作系统启动计算机工作。它检查计算机并使其做好工作准备。 2. 内存管理 这也是操作系统的一项重要功能。没有操作系统,内存就无法管理。不同的程序和数据同时在内存中执行。如果没有操作系统,程序可能会相互混合。系统将无法正常工作。 3. 加载和执行 程序在执行前必须加载到内存中。操作系统提供轻松将程序加载到内存中然后执行的功能。 4. 数据安全 数据是计算机系统的重要组成部分。操作系统保护存储在计算机上的数据免遭非法使用、修改或删除。 5. 磁盘管理 操作系统管理磁盘空间。它以适当的方式管理存储的文件和文件夹。 6. 进程管理 CPU 一次可以执行一项任务。如果有许多任务,操作系统将决定哪个任务应该获得 CPU。 7. 设备控制 操作系统还控制连接到计算机的所有设备。硬件设备由称为设备驱动程序的小软件控制。 8. 提供界面 用户界面用于使用户界面与计算机相互作用。用户界面控制如何输入数据和指令以及如何在屏幕上显示信息。操作系统为用户提供两种类型的界面: 1. 图形行界面:它与视觉环境交互以与计算机通信。它使用窗口、图标、菜单和其他图形对象来发出命令。 2. 命令行界面:它通过键入命令提供与计算机通信的界面。

使用 VessMorphoVis 对脑血管网络形态骨架进行交互式可视化和分析
动机:精确的脑血管形态模型是建模和模拟现实血管网络中脑血流的关键。这种计算机模拟方法对于揭示神经血管耦合原理至关重要。验证这些血管形态需要执行某些无法通过通用可视化框架完成的视觉分析任务。这一限制对模拟中使用的血管模型的准确性有很大影响。结果:我们提出了 VessMorphoVis,这是一套集成的工具箱,用于交互式可视化和分析庞大的脑血管网络,这些网络由最初从成像或显微镜堆栈中分割出来的形态图表示。我们的工作流程利用了 Blender 的出色潜力,旨在建立一个集成的、可扩展的、特定领域的框架,该框架能够交互式可视化、分析、修复、高保真网格划分和高质量渲染血管形态。根据用户的初步反馈,我们预计我们的框架将成为未来血管建模和模拟的重要组成部分,填补目前尚未填补的空白。 可用性和实施:VessMorphoVis 在 Github 上可根据 GNU 公共许可证免费获取,网址为 https://github.com/BlueBrain/VessMorphoVis。形态分析、可视化、网格划分和渲染模块是基于其 Python API(应用程序编程接口)作为 Blender 2.8 的附加组件实现的。用户可以通过直观的图形用户界面使用附加功能,也可以通过以后台模式运行 Blender 的功能丰富的命令行界面调用 API 的详尽配置文件使用附加功能。 联系方式:marwan.abdellah@epfl.ch 或 felix.schuermann@epfl.ch 补充信息:补充数据可在 Bioinformatics 在线获取。

通过树结构双重动态编程
动机:从多个组织样品的大量DNA测序中重建肿瘤的进化史仍然是一个具有挑战性的计算问题,需要同时对肿瘤组织的反卷积及其进化史的推论。最近,系统发育重建方法通过将重建问题分为两个部分,从而取得了重大进展:固定拓扑的回归问题和对树空间的搜索。尽管已经为后一种搜索问题开发了有效的技术,但由于缺乏快速,专业的算法,回归问题仍然是方法设计和实施的瓶颈。结果:在这里,我们介绍了FastPPM,这是一种快速工具,可以通过树结构的双动态编程来解决回归问题。FastPPM支持任意可分离的凸损耗函数,包括ℓ2,分段线性,二项式和β-二元损失,并为现有算法提供了ℓ2和分段线性损失的渐近改进。我们发现,FastPPM的表现优于专业和通用回归算法,获得了50-450×加速度,同时提供了与现有方法一样准确的解决方案。将FASTPPM纳入几种系统发育推理算法中,立即产生高达400倍的速度,仅需要对现有软件的程序代码进行少量更改。最后,FASTPPM可以在模拟数据和结直肠癌的患者衍生的小鼠模型中分析低覆盖量的大量DNA测序数据,从精度和运行时都优于最先进的系统发育推断算法。可用性:FastPPM在C ++中实现,并在github.com/elkebir-group/fastppm.git上作为命令行接口和Python库可用。

dix-seq:快速扩增子数据分析的集成管道
8 DeepBiome。Co. Ltd.,上海200031,中国 *通信:yongjunwei@zzu.edu.cn(y.w. ); liming@henau.edu.cn(M.L。 ); zhanglei@logictek.cn(L.Z.) 收到:2024年10月18日;接受:2025年2月21日;在线发布:2025年2月22日; https://doi.org/10.59717/j.xinn-life.2024.100120©2025作者。 这是CC下的开放访问文章(https://creativecommons.org/licenses/4.0/)。 引用:Dong P.,Chen Y.,Wei Y.等。 (2025)。 dix-seq:用于快速扩增子数据分析的集成管道。 创新生活3:100120。 在过去十年中,测序技术的快速进步推动了Amplicon Metagenome的广泛采用。 但是,当前的Amplicon数据分析软件/管道通常需要手动干预跨越多个步骤,因此需要清楚了解参数,并阻碍缺乏经验的用户自动化其工作流程。 在这里,我们介绍了Dix-Seq,这是一种完全容器化的工具,用于快速,自动化和可扩展的扩增子数据分析。 使用一个单个命令,DIX-Seq可以将原始扩增子序列处理为各种统计和可视化结果,生成基于HTML的报告和恢复的日志文件。 dix-seq利用单个参数表可以大大简化其命令行接口,从而使其不受欢迎的用户更容易实现,同时改善了研究可重复性。 DIX-SEQ的模块化设计使得将新方法和数据库的快速采用到其软件框架中。Co. Ltd.,上海200031,中国 *通信:yongjunwei@zzu.edu.cn(y.w.); liming@henau.edu.cn(M.L。); zhanglei@logictek.cn(L.Z.)收到:2024年10月18日;接受:2025年2月21日;在线发布:2025年2月22日; https://doi.org/10.59717/j.xinn-life.2024.100120©2025作者。这是CC下的开放访问文章(https://creativecommons.org/licenses/4.0/)。引用:Dong P.,Chen Y.,Wei Y.等。(2025)。dix-seq:用于快速扩增子数据分析的集成管道。创新生活3:100120。在过去十年中,测序技术的快速进步推动了Amplicon Metagenome的广泛采用。但是,当前的Amplicon数据分析软件/管道通常需要手动干预跨越多个步骤,因此需要清楚了解参数,并阻碍缺乏经验的用户自动化其工作流程。在这里,我们介绍了Dix-Seq,这是一种完全容器化的工具,用于快速,自动化和可扩展的扩增子数据分析。使用一个单个命令,DIX-Seq可以将原始扩增子序列处理为各种统计和可视化结果,生成基于HTML的报告和恢复的日志文件。dix-seq利用单个参数表可以大大简化其命令行接口,从而使其不受欢迎的用户更容易实现,同时改善了研究可重复性。DIX-SEQ的模块化设计使得将新方法和数据库的快速采用到其软件框架中。当前,已将21个以上的算法,软件和第三方程序集成到DIX-Seq中的八个模块中,而越来越多。这种方法还允许经验丰富的用户微调工作流程,从而促进定制分析。在实际案例研究的数据集上执行的基准测试了DIX-Seq的能力,该功能在生成统计信息和提取生物学上有意义的模式的完整数字中生成了发布的数字。此外,它在检测模拟测序深度下降的方差方面仍然非常有效,结果在所有和某些方面(例如植物网络多样性和Pearson的相关性),结果保持稳健至11000和1000的深度。总而言之,Dix-Seq是用于扩增数据分析的方便但高度可自定义的工具,使其成为入门级和经验丰富的用户的理想选择。

FALCON FDV-206 - WESTERMO - AUDIN
以太网技术 IEEE 802.3 用于 10BaseT IEEE 802.3u 用于 100BaseTX 和 100Base FX IEEE 802.3ab 用于 1000BaseT IEEE 802.3z 用于 1000BaseX VDSL/ADSL 技术 ITU-T G.993.2 VDSL2 (附件 A、B、J) ITU-T G.992.1 ADSL (附件 A、B (非重叠)) ITU-T G.992.2 ADSL Lite (附件 A (非重叠)) ITU-T G.992.3 ADSL2 (附件 A、B、I、J、L、M (非重叠)) ITU-T G.992.5 ADSL2+ (附件 A、B、I、J、M (非重叠)) RFC2684 Bridged LLC 和 Bridged VC-MUX ATM 封装 (ADSL)串行端口技术 RS-232 串行 IP(串行扩展器和虚拟串行端口) 弹性和高可用性 网络拓扑快速重构 (FRNT) FRNT 链路健康协议 (FLHP) IEEE 802.1D 生成树协议 (STP) IEEE 802.1w 快速 STP (RSTP) 第 2 层交换 IEEE 802.1Q 静态 VLAN 和 VLAN 标记 IEEE 802.3x 流量控制 IGMPv2/v3 监听 AVT 动态 VLAN(Westermo 自适应 VLAN 中继) 管理 VLAN(Westermo 管理接口概念) 静态多播 MAC 过滤器 第 2 层 QoS IEEE 802.1p 服务等级 灵活分类 VLAN 标记、VLAN ID、IP DSCP/ToS、端口 ID) IP 路由、防火墙和 VPN 静态 IP 路由 动态 IP 路由 • OSPFv2 • RIPv1/v2 VRRP 防火墙、NAT、端口转发 IPSec VPN 可管理性管理工具 • Web 界面(HTTP 和 HTTPS) • 通过控制台端口和 SSHv2 的命令行界面 (CLI) • Westermo IPConfig 工具 • SNMPv1/v2c/v3 • 灵活管理配置和日志文件
bca-云计算
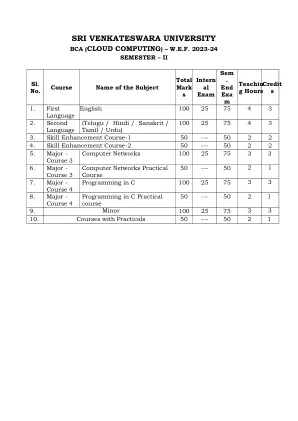
II 教学大纲 第一单元 算法和编程语言简介:算法 – 算法、流程图、编程语言的主要特性 – 编程语言的代 – 编程方法(范式) - C 语言简介:简介 – C 语言的特性 – C 程序的结构 – 编写第一个 C 程序 – C 程序中使用的文件 – 编译和执行 C 程序。 第二单元 编程结构:标记 – 使用注释 – C 语言中的基本数据类型 – 变量 – C 语言中的 I/O 语句 - C 语言中的运算符 - 编程示例。 决策控制和循环语句:决策控制语句简介 – 条件分支语句 – 迭代语句 – 嵌套循环 – Break 和 Continue 语句 – Goto 语句 第三单元 数组:简介 – 数组声明 – 访问数组元素 – 在数组中存储值 – 数组操作 – 一维、二维和多维数组。 字符串:声明和初始化字符串变量、字符和字符串处理函数。单元 IV 函数:简介 – 函数声明/原型 – 函数定义 – 函数调用 – 返回语句 – 函数类别 - 递归 - 参数传递技术 - 变量范围 – 存储类。指针:指针简介 – 声明和初始化指针变量 – 使用指针访问值 - 指针算法 – 动态内存分配。单元 V 结构和联合:简介 – 结构定义 - 访问结构成员 – 结构数组 - 联合定义 – 结构和联合之间的区别,枚举数据类型。文件:文件简介 – 在 C 中使用文件 – 从文件读取数据 – 将数据写入文件 – 检测文件末尾 – 命令行参数。