XiaoMi-AI文件搜索系统
World File Search System图像质量

合成孔径雷达图像质量测量
布莱金厄理工学院 工程学院 电气工程系 导师:Viet Thuy Vu,布莱金厄理工学院,卡尔斯克鲁纳,瑞典 Prof. Paulo A. C. Marques,里斯本高等工程学院,葡萄牙里斯本 审查员:Dr. Paulo A. C. Marques Jörgen Nordberg,瑞典卡尔斯克鲁纳布莱金厄理工学院

图像质量和速度毫不妥协
这些优先事项与三个趋势直接相关。首先,磁共振的临床实用性不断提高,这增加了对更多患者进行高效扫描和缩短从初次扫描到最终诊断的路径的压力。其次,为了在报销额度下降的情况下保持利润率 2 ,磁共振部门正在寻找降低每次扫描成本以及减少重新扫描的方法,其中 20% 的重新扫描是由于运动伪影而必须进行的。3 第三,由于 Covid-19 大流行导致选择性手术暂停,限制解除后需求激增,导致许多磁共振部门的检查积压。

NFIQ 2 NIST 指纹图像质量
nfiq 2 是开源 NIST 指纹图像质量 nfiq 的修订版。2004 年,nist 开发了第一个公开可用的指纹质量评估工具 nfiq。nfiq 2 的主要创新是将图像质量与操作识别性能联系起来。这有几个直接的好处;它允许严格定义质量值,然后进行数字校准。反过来,这又允许标准化,以支持全球部署具有普遍可解释图像质量的指纹传感器。在操作上,nfiq 2 通过识别可能导致识别失败的样本,提高了指纹识别系统的可靠性、准确性和互操作性。如今,NFIQ 是全球所有大规模生物识别部署的一部分,包括 US-VISIT、联邦信息处理标准 (FIPS) 201、联邦雇员和承包商个人身份验证 (PIV)、欧盟申根签证信息系统、国际刑警组织和印度唯一身份识别机构。自 2004 年以来,指纹技术的进步使得 nfiq 必须更新。因此,nfiq 2 的开发于 2011 年启动,由德国国家标准与技术研究所 (NIST)、联邦信息安全办公室 (BSI) 和联邦刑事警察局 (BKA) 以及研发实体 MITRE、Fraunhofer IGD、达姆施塔特应用技术大学 (h_da) 和 Secunet 合作开发。nfiq 2 提供更高的分辨率质量分数(根据国际生物特征样本质量标准 ISO/IEC 29794-1:2016 [ 8 ],范围为 0-100,而非 1-5),更低的计算复杂度,以及对移动平台质量评估的支持。此外,nfiq 2 是技术报告 ISO/IEC 29794-4 生物特征样本质量 - 第 4 部分:手指图像数据 [ 7 ] 修订为国际标准的基础。具体而言,nfiq 2 质量特征正在作为 ISO/IEC 29794-4 生物特征样本质量 - 第 4 部分:手指图像数据的一部分正式标准化,nfiq 2 源代码作为该标准的参考实现。
使用像素γ校正的图像质量增强
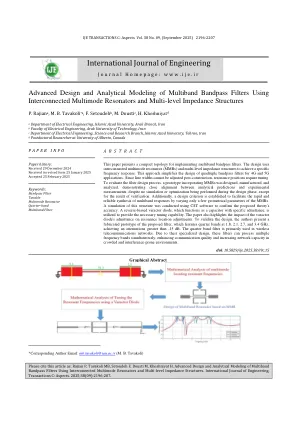
本文介绍了用于实施多播带通滤波器的紧凑拓扑。设计使用互连的多模谐振器(MMR)和多级阻抗结构来实现特定的频率响应。这种方法简化了针对4G和5G应用的四倍带通滤波器的设计。由于无法调整线路宽度后的构建后,共振位置需要调整。为了评估滤波器设计过程,尽管未在设计阶段进行模拟或优化,但设计,制造和分析了包含MMR的原型,并证明了分析预测和实验测量之间的紧密比对。此外,建立了设计标准,以通过仅改变MMR的几何参数来促进多频道响应的快速合成。使用CST软件对此结构进行了模拟,以确认所提出的理论的准确性。一种反向偏置的变量二极管,该变量二极管用作具有特定入学的电容器,可用于提供必要的调谐能力。本文还突出了变量二极管的接收对共振位置调整的影响。为了验证设计,作者提出了拟议过滤器的制造原型,该原型的特征是1.8、2.1、2.7和3.4 GHz的四分之一频段,达到了大于-15 dB的衰减。四分之一频段过滤器主要用于无线电信网络。由于其专门设计,这些过滤器可以同时处理多个频段,从而提高通信质量并增加拥挤和干扰的环境中的网络容量。

临床牙花尿酸的图像质量评估 -
目标:骨骼微结构的详细可视化对于评估计算机断层扫描(CT)中的腕骨骨折至关重要。本研究旨在与第三代二代双源CT扫描仪(EID-CT)相比,使用基于尿尿酸的临床摄氏光子计数检测器(PCD-CT)来评估CT系统的成像性能(PCD-CT)。材料和方法:两个CT系统均用于检查具有辐射剂量等效扫描方案的8个尸体手腕(低/标准/全剂量成像:CTDI VOL = 1.50/5.80/8.67 MGY)。所有手腕都用2种不同的光子计数CT(标准分辨率和超高分辨率)的操作模式进行扫描。使用可比的重建参数和卷积内核进行重新格式化后,3位放射科医生以7分制对图像质量进行了主观评估。为了估计间的可靠性,我们报告了类内相关系数(绝对一致,2向随机效应模型)。信噪比和对比度与噪声比率,以提供对图像质量的半定量评估。结果:与在标准分辨率模式下的全剂量PCD-CT相比,在超高分辨率模式下进行标准剂量PCD-CT检查的主观图像质量优越(P = 0.016)和全剂量EID-CT(P = 0.040)。在超高分辨率模式下低剂量PCD-CT和标准剂量扫描之间在标准分辨率模式下(P = 0.108)或EID-CT(p = 0.470)之间确定了差异。标准分辨率PCD-CT和EID-CT的观察者评估在全剂量和标准剂量扫描中提供了相似的结果(P = 0.248/0.509)。类内相关系数为0.876(95%置信区间,0.744 - 0.925; p <0.001),表明可靠性良好。(所有P's <0.001)。(所有P's <0.001)。

图像质量迁移的三维条件扩散模型
低场 (LF) MRI 扫描仪 (<1T) 在资源有限或电源不可靠的环境中仍然很普遍。然而,它们产生的图像的空间分辨率和对比度通常低于高场 (HF) 扫描仪。这种质量差异可能导致临床医生的解释不准确。图像质量迁移 (IQT) 旨在通过学习低质量和高质量图像之间的映射函数来提高图像质量。现有的 IQT 模型通常无法恢复高频特征,导致输出模糊。在本文中,我们提出了一种 3D 条件扩散模型来改进 3D 体积数据,特别是 LF MR 图像。此外,我们将跨批次机制整合到我们网络的自注意力和填充中,即使在小型 3D 块下也能确保更广泛的情境感知。在公开的人类连接组计划 (HCP) 数据集上进行的 IQT 和脑分区实验表明,我们的模型在数量和质量上都优于现有方法。该代码可在 https://github.com/edshkim98/DiffusionIQT 上公开获取。

使用像素γ校正的图像质量增强
冗余技术用于提高性能并实现以提高系统的寿命。如今,许多行业都应用了冗余方法。冗余的常见方法之一是其在开关系统中的利用。在交换系统中,一个或多个组件被视为活动模式,而其他组件则在待机状态下被视为开关,如有必要。为了充分利用冗余设备中的所有组件,开关单元必须完美地执行其功能,例如开关。用开关单元成功覆盖的范围以概率表示。在本文中,提出了一种新的开关成功可能性方法,并表明随着系统的增加,开关的效率和性能逐渐降低。该方法的分析基于应力强度方法。最后,应用了一些用于验证结果的数值示例。

低剂量的图像质量和定量宠物参数
1核医学和临床分子成像系,大学医院Tuebingen,72076德国Tuebingen; eduardo.calderon-ochoa@med.uni-tuebingen.de(e.c.); f.schmidt@med.uni-tuebingen.de(F.P.S.); wenhong.lan@med.uni-tuebingen.de(W.L.); salvador.castaneda@med.uni-tuebingen.de(s.c.-v.); nils.trautwein@med.uni-tuebingen.de(n.f.t。); helmut.dittmann@med.uni-tuebingen.de(H.D.); christian.lafougere@med.uni-tuebingen.de(c.l.f.)2 Werner Siemens成像中心,临床前成像和放射药,Eberhard-Karls University Tuebingen,72076德国Tuebingen 3 3 3诊断和介入放射学系,University Hospital Tuebingen,72076 Tuebingen,72076 Tuebingen,德国。 andreas.brendlin@med.uni-tuebingen.de 4卓越群体Ifit(EXC 2180)“图像指导和功能指导肿瘤疗法”,Tuebingen大学,72074德国Tuebingen,德国5德国癌症联盟(DKTK),DKTK),合作伙伴Tuebingen,72074 Tuebingen,Germany,Germany,Germany,Germany * soopersence,Germany * lena.kiefer@med.uni-tuebingen.de

人工智能可显著降低剂量并提高图像质量
* 在临床实践中,使用 Precise Image 可能会根据临床任务、患者体型和解剖位置减少 CT 患者的剂量。应咨询放射科医生和物理学家,以确定获得特定临床任务诊断图像质量的适当剂量。使用 Precise Image 的“更平滑”设置,使用 1.0 毫米切片的参考身体协议执行剂量减少评估,并在 MITA CT IQ Phantom(CCT189,Phantom 实验室)上进行测试,评估 10 毫米针头并与滤波投影进行比较。使用通道化 Hoteling 观察工具可以看到四个针头的范围,包括降低 85% 的图像噪声和在剂量减少 50% 至 80% 时从 0% 到 60% 的低对比度可检测性改进。 NPS 曲线偏移用于评估图像外观,在中心 50 毫米 x 50 毫米感兴趣区域内的 20 厘米水模上进行测量,平均偏移为 6% 或更低。

人工智能可显著降低剂量并提高图像质量
AI 系统可以使用符号规则或学习数字模型,它们还可以通过分析环境如何受到其先前行为的影响来调整其行为。作为一门科学学科,AI 包括多种方法和技术,例如机器学习(其中深度学习和强化学习是具体示例)、机器推理(包括规划、调度、知识表示和推理、搜索和优化)和机器人技术(包括控制、感知、传感器和执行器,以及将所有其他技术集成到网络物理系统中)。