XiaoMi-AI文件搜索系统
World File Search System图像

DeepFLASH:基于学习的医学图像配准高效网络
本文介绍了 DeepFLASH,一种用于基于学习的医学图像配准的高效训练和推理的新型网络。与从高维成像空间中的训练数据中学习空间变换的现有方法相比,我们完全在低维带限空间中开发了一种新的配准网络。这大大降低了昂贵的训练和推理的计算成本和内存占用。为了实现这一目标,我们首先引入复值运算和神经架构表示,为基于学习的配准模型提供关键组件。然后,我们构建了一个在带限空间中完全表征的变换场的显式损失函数,并且参数化要少得多。实验结果表明,我们的方法比最先进的基于深度学习的图像配准方法快得多,同时产生同样精确的对齐。我们在两种不同的图像配准应用中展示了我们的算法:2D 合成数据和 3D 真实脑磁共振 (MR) 图像。我们的代码可以在https://github.com/jw4hv/deepflash上找到。
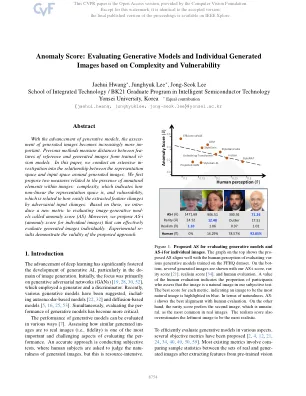
异常得分:根据复杂性和脆弱性评估生成模型和个体生成的图像
随着生成模型的发展,生成图像的评估变得越来越重要。先前的方法测量参考文献和从训练有素的VI-SION模型产生的图像之间的距离。在本文中,我们对表示图像周围的表示空间与输入空间之间的关系进行了广泛的影响。我们首先提出了与图像中不自然元素存在有关的两项措施:复杂性,这表明表示空间的非线性和脆弱性是与对抗性输入变化的轻易变化相关的脆弱性。基于这些,我们为评估称为异常评分的图像生成模式(AS)进行了新的指标。此外,我们提出了可以有效地评估生成的图像的AS-I(单个图像的异常得分)。实验性依据证明了所提出的方法的有效性。

像医学居民一样培训:对通用医学图像分割的上下文学习
临床成像工作流的主要重点是疾病诊断和管理,导致医学成像数据集与特定的临床目标密切相关。这种情况导致了开发特定于任务的分割模型的主要实践,而没有从广泛的成像群中获得见解。受到医学放射学居民培训计划的启发,我们提出了向普遍医学图像分割的转变,旨在通过利用临床目标,身体区域和成像方式的多样性和共同点来建立医学图像理解基础模型的范式。div of这个目标,我们开发了爱马仕,一种新颖的上下文 - 学习方法,以应对医学图像segmentation中数据杂基的挑战和注释差异。在五种模式(CT,PET,T1,T2和Cine MRI)和多个身体区域的大量各种数据集(2,438个3D图像)中,我们证明了通用范式比传统范式在单个模型中解决多个任务的传统范式的优点。通过跨任务的协同作用,爱马仕在所有测试数据集中都能达到最先进的性能,并显示出卓越的模型可伸缩性。其他两个数据集中的结果揭示了爱马仕在转移学习,分裂学习和对下游任务的概括方面的出色表现。爱马仕(Hermes)博学的先生展示了一个具有吸引力的特征,以反映任务和方式之间的复杂关系,这与既定的放射学解剖学和成像原则相吻合。代码可用1。

文本到图像生成模型中的开放式偏差检测
文本到图像生成模型正变得越来越流行,公众可以访问。由于这些模型看到大规模的部署,因此有必要深入研究其安全性和公平性,以免消散和永久存在任何形式的偏见。然而,存在的工作重点是检测封闭的偏见集,定义了先验的偏见,将研究限制为众所周知的概念。在本文中,我们解决了出现OpenBias的文本到图像生成模型中开放式偏见检测的挑战,该模型是一条新管道,该管道可识别和量化双质量的严重性,而无需访问任何预编译的集合。OpenBias有三个阶段。在第一阶段,我们利用大型语言模型(LLM)提出偏见,给定一组字幕。其次,目标生成模型使用相同的字幕绘制图像。最后,一个视觉问题回答模型认识到了先前提出的偏见的存在和范围。我们研究了稳定扩散1.5、2和XL强调新偏见的稳定扩散,从未研究过。通过定量实验,我们证明了OpenBias与当前的封闭式偏见检测方法和人类判断一致。

测试时间适应性的神经网络,用于强大的医学图像分割
卷积神经网络(CNN)在培训数据集代表预期在测试时遇到的变化时,可以很好地解决监督学习问题。在医学图像细分中,当培训和测试图像之间的获取细节(例如扫描仪模型或协议)之间存在不匹配和测试图像之间的不匹配时,就会违反此前提。在这种情况下,CNNS的显着性能降解在文献中有很好的记录。为了解决此问题,我们将分割CNN设计为两个子网络的串联:一个相对较浅的图像差异CNN,然后是将归一化图像分离的深CNN。我们使用培训数据集训练这两个子网络,这些数据集由特定扫描仪和协议设置的带注释的图像组成。现在,在测试时,我们适应了每个测试图像的图像归一化子网络,并在预测的分割标签上具有隐式先验。我们采用了经过独立训练的Denoising自动编码器(DAE),以对合理的解剖分段标签进行模型。我们验证了三个解剖学的多中心磁共振成像数据集的拟议思想:大脑,心脏和前列腺。拟议的测试时间适应不断提供绩效的改进,证明了方法的前景和普遍性。对深CNN的体系结构不可知,第二个子网络可以使用任何分割网络使用,以提高成像扫描仪和协议的变化的鲁棒性。我们的代码可在以下网址提供:https://github.com/neerakara/test- time- aptaptable-neural-near-netural-netural-networks- for- domain-概括。

ZK证明图像转换瓷砖在您的笔记本电脑上
[nt s&p2016] A. Naveh和E. Tromer,“ Photoproof:任何一组允许转换的加密图像身份验证” - S&P- 2016

一致的新型视图综合来自单个图像
我们介绍了Multidiff,这是一种新颖的方法,用于从单个RGB图像中始终如一地进行新颖的视图综合。从单个参考图像中综合新观点的任务是大自然的高度不足,因为存在多种对未观察到的区域的合理解释。为了解决这个问题,我们以单核深度预测变量和视频扩散模型的形式结合了强大的先验。单核深度使我们能够在目标视图的扭曲参考图像上调节模型,从而提高了几何稳定性。视频扩散先验为3D场景提供了强大的代理,从而使模型可以在生成的图像上学习连续和像素精度的对应关系。与依靠容易出现漂移和误差累积的自动格言形象生成的方法相反,Multidiff共同综合了一系列帧,产生了高质量和多视图一致的RE-

量子退火实现单幅图像超分辨率
本文提出了一种基于量子计算的算法来解决单图像超分辨率(SISR)问题。SISR 的一个著名经典方法依赖于成熟的逐块稀疏建模。然而,该领域的现状是深度神经网络(DNN)已表现出远超传统方法的效果。不过,量子计算有望很快在机器学习问题中变得越来越突出。因此,在本文中,我们有幸对将量子计算算法应用于 SISR 这一重要的图像增强问题进行了早期探索。在量子计算的两种范式,即通用门量子计算和绝热量子计算(AQC)中,后者已成功应用于实际的计算机视觉问题,其中量子并行性已被利用来有效地解决组合优化问题。本研究展示了如何将量子 SISR 公式化为稀疏编码优化问题,该问题使用通过 D-Wave Leap 平台访问的量子退火器进行求解。所提出的基于 AQC 的算法被证明可以实现比传统模拟更快的速度,同时保持相当的 SISR 精度 1 。


用于可变形医学图像配准的相关感知粗到精 MLP
可变形图像配准是医学图像分析的基本步骤。最近,Transformer 已用于配准,其表现优于卷积神经网络 (CNN)。Transformer 可以捕获图像特征之间的长距离依赖性,这已被证明对配准有益。然而,由于自注意力的计算/内存负载高,Transformer 通常用于下采样特征分辨率,无法捕获全图像分辨率下的细粒度长距离依赖性。这限制了可变形配准,因为它需要每个图像像素之间精确的密集对应关系。没有自注意力的多层感知器 (MLP) 在计算/内存使用方面效率高,从而可以捕获全分辨率下的细粒度长距离依赖性。然而,MLP 尚未在图像配准中得到广泛探索,并且缺乏对医学配准任务至关重要的归纳偏差的考虑。在本研究中,我们提出了第一个基于相关感知 MLP 的配准网络 (CorrMLP) 用于可变形医学图像配准。我们的 CorrMLP 在新颖的粗到细配准架构中引入了关联感知多窗口 MLP 块,该架构可捕获细粒度多范围依赖性以执行关联感知粗到细配准。对七个公共医疗数据集进行的大量实验表明,我们的 CorrMLP 优于最先进的可变形配准方法。