XiaoMi-AI文件搜索系统
World File Search System基准

量子计算的基准测试
由 Sophia Helmrich 博士和 Johann Schmidt 博士编辑,数字战略与发展(部),DLR-PT 贡献者 Hossam Ahmed、Mazen Ali、Abhishek Awasthi、Dimitris Badou nas、Valeria Bartsch、Colin Kai-Uwe Becker、Pallavi Bhardwaj、Tim Bittner、Martin Braun、Sebastian Bock、Lukas Burgholzer、邓小龙、克劳迪娅·埃里格、克里斯托夫·艾希哈默、多梅尼克·艾希霍恩、马文·埃尔德曼、克里斯蒂安·埃特勒、弗雷德·菲安德、桑多尔·费克特、泰勒·加诺夫斯基、亚历山大·耿、伊利-丹尼尔·格奥尔基-波普、克里斯蒂安·格罗泽亚、温德林·格罗斯、萨沙·豪克、多米尼克·赫尔德温、帕特里克·霍尔泽、迈克尔·霍尔茨基、路易吉亚皮奇诺、马泰奥·安东尼奥·伊纳耶托维奇、迈克尔·约翰宁、凯特琳·琼斯 / 约翰内斯·荣格 / 马蒂亚斯·卡贝尔 / 菲利普·凯尔登尼奇 / 多米尼克·克鲁普克 / 格奥尔格·克鲁斯 / 索菲亚·拉赫斯 / 珍妮特·米里亚姆·洛伦茨 / 阿西西奥·卡斯塔尼达·梅迪纳 / 阿里·莫吉塞 / 安德烈亚斯·穆勒 / 巴拉德瓦吉·乔达里·穆马内尼 / 菲利克斯·保罗 / 马尼拉曼·佩里亚萨米 / 塞巴斯蒂安·里奇 / 马可·罗斯 / Raja Seggoju、Sebastian Senge、Hendrik Siebeneich、Theeraphot Sriarunothai、Jonas Stein、Rainer Strater、Nikolay Tcholtchev、Matthias Traube、Christian Tutschku、Friedrich Wagner、Mareike Weule、Armin Wolf

技术行业基准2024
•电池电动汽车在所有国家 /地区的受欢迎程度都在越来越高,尽管西欧国家和北欧国家的发展速度更快。•奥地利,比利时,丹麦,葡萄牙和瑞典在舰队中的BEV份额大幅增加,份额几乎翻了一番。

可持续采矿的新基准
此情况说明书仅用于信息目的。WYLOO公司集团的成员,或其分支机构,代理商和允许的分配(集体,“ Wyloo”或“ Company”)的成员,没有任何代表或保修,明示或隐含的信息,不应将其包含在此处包含的信息,并且不应将其包含在此上。 市场和统计数据是从各种来源获得的;公司尚未独立验证假设,也不能保证该信息的准确性或完整性。 此事实说明书包含前瞻性语句。 某些前瞻性陈述基于假设或未来事件,这些事件可能不准确,并且不应对此情况说明书中的任何前瞻性陈述放置任何依赖。WYLOO公司集团的成员,或其分支机构,代理商和允许的分配(集体,“ Wyloo”或“ Company”)的成员,没有任何代表或保修,明示或隐含的信息,不应将其包含在此处包含的信息,并且不应将其包含在此上。市场和统计数据是从各种来源获得的;公司尚未独立验证假设,也不能保证该信息的准确性或完整性。此事实说明书包含前瞻性语句。某些前瞻性陈述基于假设或未来事件,这些事件可能不准确,并且不应对此情况说明书中的任何前瞻性陈述放置任何依赖。

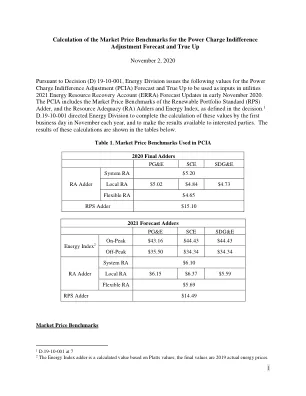
2020估计的市场价格基准。 ...
PCIA的计算是在D.11-12-018中建立的,最近在D.19-10-001中进行了完善。3 PCIA或公用事业的冷漠量相当于公用事业公司在给定年内的市场价值降低其市场价值。市场价值在d.19-10-001中定义为“以美元计量的估计财务价值,这归因于能源资源的公用事业投资组合,目的是计算给定年份的电费无差调整。” D.19-10-001将市场价格基准(MPB)定义为“与公用事业投资组合中三个主要价值相关的每单位价值(不是总投资组合价值)的估计(能源,资源充足性和可再生能源)”。作为市场价值总体计算的一部分,将4个MPB乘以相关投资组合量。预测的加法器是旨在减少冷漠量的不确定性的机制,而真正的UP加成器是旨在将实际实现的市场收入与预测值相结合的机制。ra加法器是MPB,它反映了公用事业投资组合中每个容量单位的估计值,可用于满足资源充足义务,为每千瓦年度的美元价值($/kW年)。RA加法器具有三个子组件,反映了遵守RA计划所需的每种RA产品:系统,本地和灵活。5

视觉的元构基准
近年来,变形金刚[9]在各种计算机视觉任务[10],[11],[12],[13]中表现出了不前期的成功。变压器的能力长期以来一直归因于其注意力模块。因此,已经提出了许多基于注意力的令牌混合器[4],[5],[14],[15],[16],目的是为了增强视觉传输(VIT)[11]。尽管如此,一些工作[17],[18],[19],[20],[21]发现,通过用空间MLP [17],[22],[23]或傅立叶变换[18]等简单操作员更换变压器中的注意模块,结果模型仍然会产生令人鼓舞的性能。沿着这条线,[24]将变压器摘要为一种称为元构造器的通用体系结构,并假设是元构造者在实现竞争性能中起着至关重要的作用。To verify this hypothesis, [24] adopts embarrassingly simple operator, pooling, to be the token mixer, and discovers that PoolFormer effectively outperforms the delicate ResNet/ViT/MLP-like baselines [1], [2], [4], [11], [17], [22], [25], [26], which con- firms the significance of MetaFormer.

SSRO 基准利润指导版本 8
除非合同被修改,否则将重新确定,在这种情况下将适用新规定。作为 2024 年 4 月 1 日生效的立法变化的一部分,确定合同利润率的流程从六个步骤减少到四个步骤。必须采用四步流程来计算自 2024 年 4 月 1 日起签订的新合同或合同定价修订(或其组成部分)的合同利润率。对于在 2024 年 4 月 1 日之前签订的合同或定价修订,如果采用使用六步流程计算的合同利润率,这些合同将继续采用相同的合同利润率,无需重新计算。根据之前的六步流程确定的 POCO 调整的合同现在受新规定的约束,可通过允许成本进行调整。有关这方面的更多指导,请参阅《允许成本指南》第 I 部分第 5 节。


迈向计算室内声学的基准
过渡到操作系统,举办了两次混响建模研讨会 - RMW - 最后一次是在 2008 年 5 月。RMW 的基本目标是提供明确定义的问题和一致的解决方案,以支持新模型的验证和确认、海军标准模型的升级以及基于混响数据的地声反演技术。设计研讨会的基本问题是,即使是海军感兴趣的最简单的混响问题也没有闭式解,而且仍然 - 本质上 - 超出了我们使用标准“精确”数值技术解决的计算能力。所有当前实用的水下混响模型都通过使用散射和损失函数或表格来取代物理问题。我们讨论了一系列定义明确的问题(基于物理),具有等效的损失/散射输入,复杂性有所增加。我们还讨论了在此过程中获得的经验教训,并指出了研讨会的一些意外结果,并为未来的基准研讨会提出了建议。� 海军研究办公室支持的工作。�

能量确定协调员:基准能力...
31 de Mar。de 2023 - 该河流行动计划已广泛利用玛格丽特河中的吉纳维芙·汉兰·史密斯(Genevieve Hanran-Smith)和艾伦·麦金尼(John McKinney)的艾伦·布鲁克(Ellen Brook)行动计划中的作品。