XiaoMi-AI文件搜索系统
World File Search System处理方案

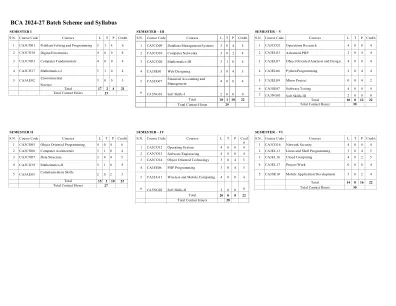
BCA 2024-27批处理方案和教学大纲
单元数系统系统:二进制,八进制,十六进制,从一个碱基到另一个碱基的转换,二进制算术,未签名的二进制数,签名的幅度数,2的补体表示,2的补充算术。ASCII代码,BCD代码,EBCDIC代码,多余的代码和灰色代码。算术电路:加法器,减法器,二进制乘数和分隔线。单元II逻辑门:不,或,或,或,或,或,或者,或者,nor,ex-Or和ex-nor Gates,二极管和晶体管作为开关。 布尔代数:布尔代数的定律,逻辑大门,使用k-映射对布尔方程的简化。 单元III组合电路:多路复用器,弹能器及其用作逻辑元素,解码器。 加法器/字样。 编码器,解码器触发器:S-R- J-K。 T. D,时钟的触发器,围绕状态竞争,主人触发器。 单元IV位移登记册:串行串行,并行序列,并行串行和平行 - 外向,双向移位寄存器。 计数器:异步和同步戒指计数器和约翰逊计数器,Tristate Logic。 a/d和d/a转换器:采样并保持电路。 单元-V内存:内存单元格,主内存 - RAM,ROM,PROM,EPROM,EPROM,EEPROM,CACHE内存,闪存存储器,DDR,DDR,辅助内存及其类型,物理内存和虚拟内存的介绍,内存访问方法:串行和随机访问。 教科书:数字原理和应用,Malvino&Leach,McGraw Hill。 数字集成电子产品,Taub&Schilling,MGH Thomas C Bartee,数字计算机基础,MacGrawhill参考:R.P.单元II逻辑门:不,或,或,或,或,或,或者,或者,nor,ex-Or和ex-nor Gates,二极管和晶体管作为开关。布尔代数:布尔代数的定律,逻辑大门,使用k-映射对布尔方程的简化。单元III组合电路:多路复用器,弹能器及其用作逻辑元素,解码器。加法器/字样。编码器,解码器触发器:S-R- J-K。 T. D,时钟的触发器,围绕状态竞争,主人触发器。单元IV位移登记册:串行串行,并行序列,并行串行和平行 - 外向,双向移位寄存器。计数器:异步和同步戒指计数器和约翰逊计数器,Tristate Logic。a/d和d/a转换器:采样并保持电路。单元-V内存:内存单元格,主内存 - RAM,ROM,PROM,EPROM,EPROM,EEPROM,CACHE内存,闪存存储器,DDR,DDR,辅助内存及其类型,物理内存和虚拟内存的介绍,内存访问方法:串行和随机访问。教科书:数字原理和应用,Malvino&Leach,McGraw Hill。数字集成电子产品,Taub&Schilling,MGH Thomas C Bartee,数字计算机基础,MacGrawhill参考:R.P.Jain,数字电子产品,麦格劳山莫里斯·马诺(McGraw Hill Morris Mano),数字设计,Phi Gothmann,数字电子,Phi Tocci,数字系统原理和应用,Pearson Education Asia Asia Asia Donald D Givone,数字原理和设计,TMH

通过特征处理方案优化药物 - 目标亲和力预测方法
结果:在这项研究中,为了获得具有高精度和强大可解释性的模型,我们利用了各种传统和尖端的特征选择和降低维度降低技术来处理自我相关特征和相邻的相关特征。然后将这些优化的特征送入学习排名以实现有效的DTA预测。在两个常用数据集上进行的广泛实验结果表明,在各种特征优化方法中,基于回归树的特征选择方法对于构建具有良好性能和稳健性的模型是最有益的。然后,通过利用Shapley添加说明值和增量功能选择AP-PRACH,我们可以获得高质量的功能子集由前150D特征组成,而Top 20D功能对DTA预测产生了突破性的影响。总而言之,我们的研究彻底验证了DTA预测中特征优化的重要性,并作为构建高性能和高解释模型的灵感。

通过特征处理方案优化药物 - 目标亲和力预测方法
结果:在这项研究中,为了获得具有高精度和强大可解释性的模型,我们利用了各种传统和尖端的特征选择和降低维度降低技术来处理自我相关特征和相邻的相关特征。然后将这些优化的特征送入学习排名以实现有效的DTA预测。在两个常用数据集上进行的广泛实验结果表明,在各种特征优化方法中,基于回归树的特征选择方法对于构建具有良好性能和稳健性的模型是最有益的。然后,通过利用Shapley添加说明值和增量功能选择AP-PRACH,我们可以获得高质量的功能子集由前150D特征组成,而Top 20D功能对DTA预测产生了突破性的影响。总而言之,我们的研究彻底验证了DTA预测中特征优化的重要性,并作为构建高性能和高解释模型的灵感。

超声处理方案及其对植入物相关感染微生物诊断的贡献:当前情况的回顾
针对植入物相关感染的微生物诊断中存在的问题以及当前关于超声液体培养 (SFC) 的真正精确度的争论,本综述的目的是描述该方法并分析和比较当前该主题研究的结果。此外,本研究还讨论并提出了执行超声处理的最佳参数。我们在文献中搜索了最近 (2019-2023) 的关于该研究主题的研究。结果,正如预期的那样,在所分析的研究中采用了不同的超声处理方案,因此,与传统培养方法 (假体周围组织培养 - PTC) 相比,该技术在灵敏度和特异性方面的结果存在显著差异。凝固酶阴性葡萄球菌 (CoNS) 和金黄色葡萄球菌被 SFC 和 PTC 鉴定为主要病原体,SFC 对于鉴定难以检测的低毒力病原体非常重要。与化学生物膜置换法 EDTA 和 DTT 相比,SFC 也产生了不同的结果。在此背景下,本综述概述了该主题的最新情况,并通过从各个方面(包括样品采集、储存条件、培养方法、微生物鉴定技术(表型和分子)和菌落形成单位 (CFU) 计数的临界点)评估最佳参数,为提高超声处理性能(特别是在灵敏度和特异性方面)提供了理论支持。这项研究证明了该技术标准化的必要性,并为超声处理方案提供了理论基础,该方案旨在实现最高水平的灵敏度和特异性,以便对与植入物和假体装置相关的感染(例如假体关节感染 (PJI))进行可靠的微生物诊断。然而,仍然需要实际应用和额外的补充研究。

山体滑坡评估报告 - DA2024-209
表 1:财产风险 定性风险重要性 - 岩土工程要求 非常高 VH 不进行处理则不可接受。需要进行广泛详细的调查和研究、规划和实施处理方案以将风险降低到低。可能过于昂贵且不切实际。工作成本可能超过财产的价值。 高 H 不进行处理则不可接受。需要详细调查、规划和实施处理方案以将风险降低到可接受的水平。相对于财产的价值,这项工作将花费大量资金。 中等 M 在某些情况下可以容忍(需经监管机构批准),但需要调查、规划和实施处理方案以将风险降低到低。应尽快实施将风险降低到低的处理方案。 低 L 通常为监管机构所接受。如果需要进行处理以将风险降低到这一水平,则需要持续维护。 非常低 VL 可接受。通过正常的斜坡维护程序进行管理。

PFAS 土壤处理工艺——操作范围和限制的回顾
5.2.2.1. 概述和 PFAS 去除机制 40 5.2.2.2. 适用于处理方案 41 5.2.2.3. 不同 PFAS 的处理效果与处理目标 41 5.2.2.4. 适用于土壤特性和共同污染 42 5.2.2.5. 操作考虑因素 42 5.2.2.6. 成本和商业考虑因素 43 5.2.2.7. 能源和化学品使用及可持续性考虑因素 43 5.2.2.8. 案例研究 43 5.2.2.9. 知识差距 43 5.2.3. 热解吸 43 5.2.3.1. 概述和 PFAS 去除机制 43 5.2.3.2. 适用于处理方案 45 5.2.3.3.不同 PFAS 的处理效果与处理目标 45 5.2.3.4. 对土壤特性和共同污染的适用性 47 5.2.3.5. 操作考虑因素 48 5.2.3.6. 成本和商业考虑因素 48 5.2.3.7. 能源和化学品使用及可持续性考虑因素 48 5.2.3.8. 案例研究 49 5.2.3.9. 知识差距 49 5.2.4. 阴燃 49 5.2.4.1. 一般描述和 PFAS 去除机制 49 5.2.4.2. 对处理方案的适用性 51 5.2.4.3. 不同 PFAS 的处理效果与处理目标 51 5.2.4.4. 对土壤特性和共同污染的适用性 52 5.2.4.5.操作考虑因素 52 5.2.4.6. 成本和商业考虑因素 52 5.2.4.7. 能源和化学品使用及可持续性考虑因素 53 5.2.4.8. 案例研究 53 5.2.4.9. 知识差距 53 5.3. 非破坏性方法 54 5.3.1. 异位土壤冲洗 54 5.3.1.1. 一般描述和 PFAS 去除机制 54 5.3.1.2. 适合处理方案 56 5.3.1.3. 不同 PFAS 的处理效果与处理目标 57 5.3.1.4. 对土壤特性和共同污染的适用性 58 5.3.1.5. 操作考虑因素 59 5.3.1.6.成本和商业考虑因素 59 5.3.1.7. 能源和化学品使用及可持续性考虑因素 60 5.3.1.8. 案例研究 61 5.3.1.9. 知识差距 61 5.3.2. 稳定化和固化 (S/S) 61 5.3.2.1. 一般描述和 PFAS 去除机制 61 5.3.2.2. 适合处理方案 65 5.3.2.3. 不同 PFAS 的处理效果与处理目标 66 5.3.2.4. 对土壤特性和共同污染的适用性 70 5.3.2.5. 操作考虑因素 71 5.3.2.6. 成本和商业考虑因素 72 5.3.2.7. 能源和化学品使用及可持续性考虑因素 73 5.3.2.8.案例研究 73 5.3.2.9. 知识差距 73 5.4. 途径管理方法 74 5.4.1. 填埋 74 5.4.1.1. 一般描述和 PFAS 去除机制 74 5.4.1.2. 处理方案的适用性 75 5.4.1.3. PFAS 废物阈值 76 5.4.1.4. PFAS 废物填埋场的可用性 76
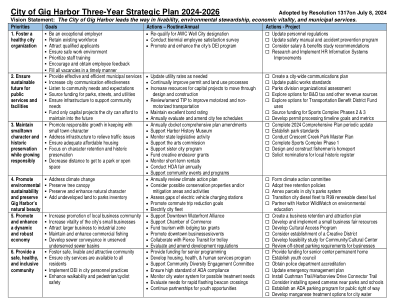
吉格港市 2024-2026 年三年战略规划
为老年中心永久住所提供资金 成立青年委员会 获得警察局认证 更新应急管理计划 安装 Cushman Trail/Harborview Drive 连接步道 考虑在公园和学校附近安装测速摄像头 为公共通行权制定 ADA 停车计划 开发城市水的锰处理方案

GNSS+ 对流层探测天气和气候
无线电掩盖(RO)已进行了深入的研究,并通过澳大利亚社区气候和地球系统模拟器(Access)数值天气预测(NWP)模式成功地将BOM作为BOM作为新数据源的澳大利亚运营天气预报服务。已经证明了十个小时的改善,因此,该团队获得了2012年澳大利亚创新卓越的奖励和澳大利亚创新挑战奖的决赛入围者。下图显示了简化的GNSS RO数据处理方案。

维多利亚州保护数据安全标准
VPDSS 中描述的要素包括直接修改风险的控制和对控制环境至关重要的支持性控制。决定哪些要素适用(适用性声明)取决于组织的风险接受标准和风险处理方案。确定适用要素还取决于要素之间如何相互作用以提供“纵深防御” 1 。如果组织认为要素不适用于自己,则应在做出此类决定的同时提供支持性论证。