XiaoMi-AI文件搜索系统
World File Search System多代

代尔夫特理工大学资料库
在荷兰北部,科学技术教育始于莱顿,1600 年 1 月 9 日,毛里茨亲王宣布了一项由西蒙·斯蒂文设计的教育计划“DuytscbeMathematique”。第二天,数学家 Ludolf van Ceulen 接到任务,负责工程科学专业学生的数学和测量教育 1 。这所隶属于莱顿大学的工程学院基本上是一所高等专业培训机构。规定课程必须用荷兰语而不是拉丁语授课,这是学术教育的惯例,这强调了新工程教育计划的学生与传统学术计划的学生之间的差异。因此,在莱顿,毕业的工程师经常被描述为“相当普通的服务提供者,具有
代尔夫特理工大学资料库
在荷兰北部,科学技术教育始于莱顿,1600 年 1 月 9 日,毛里茨亲王宣布了一项由西蒙·斯蒂文设计的教育计划“DuytscbeMathematique”。第二天,数学家 Ludolf van Ceulen 接到任务,负责工程科学专业学生的数学和测量教育 1 。这所隶属于莱顿大学的工程学院基本上是一所高等专业培训机构。规定课程必须用荷兰语而不是拉丁语授课,这是学术教育的惯例,这强调了新工程教育计划的学生与传统学术计划的学生之间的差异。因此,在莱顿,毕业的工程师经常被描述为“相当普通的服务提供者,具有

教学大纲 - 布鲁克代尔社区学院
课程描述:将强调致病微生物的生物学,强调它们的显微镜和分子方面。学生将详细描述患病状态期间宿主 - 寄生虫综合体之间存在的关系。他们也将熟悉那些具有致病性的微生物的特征。学生将能够列出和表征各种致病性细菌,病毒和真核寄生虫(包括真菌,藻类,原生动物和蠕虫)。微生物学中的隔离和识别技术将由学生在实验室中掌握。将彻底检查用于打击病原体的化学疗法,免疫学和血清学的作用。最后,将详细讨论人体的体内防御机制,尤其是那些反对侵入微生物的人。

在铵连接的二陈代
人工分子机器,由几个分子组成的纳米级机器,提供了转化涉及催化剂,分子电子,药物和量子材料的场的潜力。这些机器通过将外部刺激(如电信号)转换为分子水平的机械运动来运行。二纯化,一种特殊的鼓形分子,由夹在两个五元碳环之间的铁(Fe)原子组成,是分子机械的有前途的基础分子。它的发现于1973年获得了诺贝尔化学奖,此后已成为分子机器研究的基石。是什么使二新世如此吸引人的是其独特的特性:Fe离子的电子状态从Fe +2到Fe +3的变化,导致其两个碳环在中央分子轴周围旋转约36°。通过外部电信号控制该电子状态可以实现精确控制的分子旋转。然而,实际应用的一个主要障碍是,当吸附到底物表面,尤其是扁平金属底物的表面,即使在超高的真空条件下,也很容易分解。到目前为止,尚未发现一种未发现锚定在没有分解的表面上的确定方法。他们成功地创建了世界上最小的电气控制的分子机。“在这项研究中,我们通过使用二维冠状醚膜预先涂层来成功稳定并吸附的二茂铁分子到贵族金属表面上。重要的是,在在一项开创性的研究中,由日本千叶大学工程研究生院副教授Yamada副教授领导的研究小组,包括千叶大学工程学院的PeterKrüger教授,日本分子科学学院Satoshi Kera教授,日本分子科学研究所,Masaki Horie of Masaki Horie of ther Internation of ther Internation of the National the the Hua the Hua the Hua the hua the hua the hua the hua。这是原子量表上基于二革新的分子运动的第一个直接实验证据。他们的发现发表在2024年11月30日的《小杂志》中。为了稳定二茂铁分子,该团队首先通过添加铵盐来修改它们,形成纤新新世铵盐(FC-AMM)。这种提高的耐用性,并确保可以将分子牢固地固定在基板的表面上。然后将这些新分子固定在由冠状环状分子组成的单层膜上,这些膜被放置在平坦的铜底物上。冠状环分子具有独特的结构,其中央环可以容纳各种原子,分子和离子。Yamada教授解释说:“以前,我们发现冠状环节可以在平坦金属底物上形成单层膜。 该单层将FC-AMM分子的铵离子捕获在冠状醚分子的中央环中,从而防止了二陈代的分解,通过充当对金属底物的屏蔽。”接下来,团队放置了扫描隧道显微镜(STM)探针在FC-AMM分子的顶部,并施加了电压,这引起了分子的横向滑动运动Yamada教授解释说:“以前,我们发现冠状环节可以在平坦金属底物上形成单层膜。该单层将FC-AMM分子的铵离子捕获在冠状醚分子的中央环中,从而防止了二陈代的分解,通过充当对金属底物的屏蔽。”接下来,团队放置了扫描隧道显微镜(STM)探针在FC-AMM分子的顶部,并施加了电压,这引起了分子的横向滑动运动具体而言,在施加-1.3伏的电压时,一个孔(电子留下的空置)进入了Fe离子的电子结构,将其从Fe 2+切换到Fe 3+状态。这触发了碳环的旋转,并伴有分子的横向滑动运动。密度功能理论计算表明,由于带正电荷的FC-AMM离子之间的库仑排斥,这种横向滑动运动发生。

乌代·饶 - 高速公路教堂
《反思》正如书名所暗示的那样——我对去年阅读圣经时引起我注意的圣经经文的个人反思。它们是写在日记里的,作为我个人日常灵修的一部分。(封面上的图片是我使用的日记和圣经,还有一些我潦草的笔迹!)因此,与我的第一本每日灵修书《深入》不同,这本书涉及的学术或研究很少。事实上,在对这本书的灵修进行微调时,我抵制了通过大量重写来调和、淡化或美化我的一些反思的诱惑。我希望我能够保留我所写内容的诚实和亲密,当时我认为只有上帝和我会阅读它们!感谢 Supriya 如此精心地设计封面和每一页,感谢 Anne 至少五次校对整个灵修书,感谢 Aashray 的专业指导,感谢 Aneela 在本书出版的各个方面比我付出更多!最重要的是,我感谢上帝使用我,尽管我并不配,也不称职。我祈祷这些反思能造福许多人,让他们与我们伟大而慈爱的上帝建立更深的关系,并让他们实现他的王国目标!

格伦代尔职业学院目录
历史和教育理念、我们的使命以及我们的员工和教职员工 1 BPPE 批准声明、目录更新政策和所有权声明 1-2 特别信息 3 认证和批准信息 4 学院位置和提供的课程 5-6 设施 7 加利福尼亚州居住要求/学生实际位置 7 教室/实验室设备 8-10 一般信息 11 入学要求和程序 入学要求 11-16 在我们机构获得的学分和证书的可转移性 16 转学分政策 16-19 转学分 – VA 学生 19 课程实际要求 19-21 第 504 条/ADA 政策 22 IX 条/性骚扰政策 23-44 有关学术日历的信息 45 学院日历 45 学生和校友服务 46 就业服务 47 行为准则 48-49 纪律程序和终止及申诉政策 50 版权政策 51出勤政策 52-53 实习/外部实习/临床经验 53-54 补课政策 54 远程教育出勤政策和学术时间表 55 休假 (LOA) 56-57 FERPA 下的权利通知 57-58 机构记录保留 58 学生投诉/申诉程序 59 非歧视和反骚扰政策 60-63 毕业要求和文凭 64 其他许可和认证信息 64 图像使用 64 课程 护理学理学学士 (RN 至 BSN) 65-69 护理学副学士学位 (RN) 70-78 医疗管理理学副学士学位 79-82 医疗管理理学副学士学位 – 远程教育 (DE) 83-86 中央服务仪器技术员 87-90 医疗助理 91-93 医疗保险账单员和编码员 94-96外科技术-职业科学副学士 (ST-AOS) 97-103 职业护士 104-107 课程学费安排 108-109 加州学生学费恢复基金 (STRF) 110-111 退款政策 112-113 退学政策 113 学费和/或其他费用支付 113 财务援助信息 114-116 退还第四章资金 116-117 课程信息/课程学分和必修课外准备时间 118-119 评分系统 120 令人满意的学业进展 (SAP) 121-124 终止政策 124-125 重新入学政策 125 学生记录保留政策 125 退伍军人管理局学生信息评分系统 126 令人满意的学业进展 (SAP) 126-128 教职员工和公司领导信息 129-135 目录出版日期:2025 年 1 月 6 日

4 周全餐代餐计划
• 纯蛋白棒 • Quest 棒 • Costco 出售的 Kirkland Signature • Fit Crunch • UW American Center Pharmacy 出售的 Bariatric Advantage 您的医疗团队可能已将此信息作为您护理的一部分提供给您。如果是这样,请使用它并在您有任何疑问时致电。如果此信息不是作为您护理的一部分提供给您的,请咨询您的医生。这不是医疗建议。这不能用于诊断或治疗任何医疗状况。由于每个人的健康需求不同,您在使用此信息时应与您的医生或医疗团队的其他成员交谈。如果您有紧急情况,请拨打 911。版权所有 © 12/2021 威斯康星大学医院和诊所管理局。保留所有权利。由护理系 HF#8227 制作。

常规代孕价格清单
Surrogate Screening Tests: Probable Possible HIV (Human Immunodeficiency Virus)* $105.00 HBsAg (Hepatitis B) * $99.00 HCsAb (Hepatitis C) * $59.00 RPR (Syphilis) * $49.00 DNA Gene Probe (Gonorrhea & Chlamydia) * $139.00 CMV Total (Cytomegalovirus) $104.00 ABO RH(血型)$ 39.00抗体屏幕$ 55.00 Rubella ab IgG $ 129.00 Rubella疫苗接种(如果不能免疫)(注射套件)$ 142.00 VARICELLA(Chicken Pox)Varicella疫苗接种(Injection X2 incection x2 incl。)$ 377.00孕酮$ 140.00 cbc w/diff $ 48.00电解质$ 42.00 FSH(卵泡刺激激素)$ 140.00 counsyl遗传测试†$ 550.00尿液药物筛查$ 83.00 Venipuncture(x3)上面的“*”测试每六个月重复一次,以确保
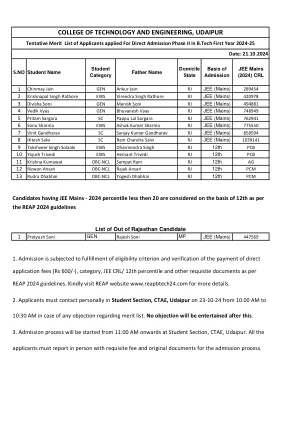
乌代布尔科技工程学院
1 Chinmay Jain Gen Ankur Jain RJ Jee(Mains)289454 2 Krishnapal Singh Rathore Ews Virendra Singh Rathore RJ Jee(Mains)420978 3 Divisha soni soni gen gen manish soni soni soni soni soni soni rj jee(Mains)494881 4 vedik vyas vyas bhases jee jee 7 jee 7 sc Appu Lal Sargara RJ Jee(Mains)762941 6 Sonu Sharma EWS Ashok Kumar Sharma RJ Jee(Mains)775550 7 Vinit Gandharav SC Sanjay Kumar Gandharav gandharav rj Jee(Mains) EWS Dharmendra Singh RJ 12th PCB 10 11 Krishna Kumawat OBC-NCL 12 届 Sampat Ram RJ 12 届 AG 12 Rizwan Ansari OBC-NCL 13 Rudra Dhabhai OBC-NCL 14 Yogesh Dhabhai RJ 12 届 PCM

低血糖症 - 格伦代尔动物医院
糖(称为“低血糖性癫痫”)通常会在 1-2 分钟内停止;如果癫痫发作时间延长,建议送往医院;如果短暂的癫痫发作已经结束或存在其他极低血糖迹象(称为“低血糖危机”),建议在口腔组织、脸颊内壁涂抹玉米糖浆或 50% 葡萄糖,然后在宠物可以吞咽后通过口腔给予相同的溶液;然后立即寻求兽医的医疗帮助 开始频繁喂食低单糖饮食,如果宠物无法进食,则进行静脉输液治疗