XiaoMi-AI文件搜索系统
World File Search System多代

当代亲密关系再定义:评介《演算式亲密》 -新闻学研究
S12115-013-9658-9 Elliott,A。,&Turner,B.S。(2012)。社会。政治出版社。Giddens,A。(1990)。现代性的后果。政治出版社。li,J.(2024)。算法亲密关系:人际关系中的数字革命:


Z代,银行和个人财务管理
传统银行 - E.G.BBVA,Caixabank-被确定为西班牙大型金融危机背后的主要作者。新银行模型 - 例如n26-被认为更“道德”,更适合年轻的客户资料和需求。但是,这还不足以点燃信任。

推进阿米代尔地区发展
作为悉尼和布里斯班之间的中点,阿米代尔地区机场支持着多样化的区域经济,包括教育部门、游客经济、农业、体育、休闲和澳大利亚最大的可再生能源区。阿米代尔地区机场还具有非常重要的紧急服务功能,这在 2019 年全州范围的森林大火中得到了体现。自那场大火发生以来,新南威尔士州乡村消防局在阿米代尔地区机场建立了一个空中消防基地,以支持新英格兰地区和新南威尔士州北部的消防工作。

C 部分 - 阿马代尔市
请注意一份常设利益声明,如果此议程上的项目已在相关地方政府理事会会议上审议过,地方政府 DAP 成员承认,根据 DAP 行为准则 2024 第 2.4.9 节,他们已声明他们曾参加过与本次会议上正在确定的项目有关的前一次理事会会议。但是,根据 DAP 行为准则 2024 第 2.1.2 节,他们承认他们不受地方政府任何先前决定或决议的约束,并承诺对他们面前的任何 DAP 申请行使独立判断,这些申请将根据其规划优点进行考虑。3. 表格 1 DAP 申请 3.1 部分地块 9550 和 9050 Alex Wood Drive,Forrestdale – 拟建仓库/仓库/杂费办公室 – DAP/24/02752

基尔代尔郡发展规划 2023-2029
ESB 推出电动汽车基础设施 ESB 已在爱尔兰岛建立了近 1,350 个电动汽车充电点网络。爱尔兰政府为爱尔兰的电动汽车普及设定了远大目标,以解决能源需求和交通排放问题。为了满足电动汽车的增长需求,ESB 在政府气候行动基金的支持下,正在全国范围内推出大功率充电中心。这些充电中心将能够同时快速为 2 到 8 辆汽车充电,并将方便汽车在爱尔兰的国家路线和高速公路上行驶更长的距离。ESB 的计划还包括在本世纪末投资绿色氢气的生产、储存和发电设施。绿色氢气是一种清洁、零碳燃料,将由可再生能源生产。这完全符合 2020 年启动的欧盟能源部门整合战略,该战略优先考虑以能源效率为核心的更“循环”的能源系统。在无法实现直接电气化的终端应用领域(例如重型货物运输、高温工业供热和零碳可调度电力发电),使用氢等可再生燃料进行更大程度的电气化,将在2050年实现碳中和方面发挥重要作用。

霍尼斯代尔高中课程指南
WHSD 非歧视政策、第九条政策 2 职业技术教育/第六条 3 霍内斯代尔高中校长来信 4 规划高中路径/科目选择指南 5 毕业要求 6 双重注册 7 霍内斯代尔高中小型学习社区 7
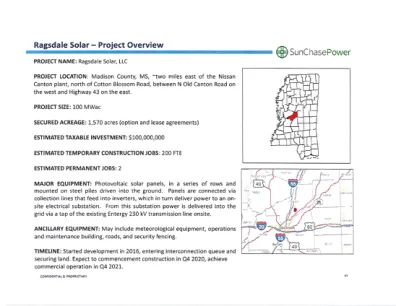
拉格斯代尔计划
8. 为实现该县目标,如果公司选择该县作为项目所在地,并且项目的资本投资等于或大于预期投资,董事会特此宣布其意图,即根据法典第 27-31-104 条的规定,批准并与公司签订 FILOT 协议,该协议的最长期限为该协议允许的最长期限(即自本决议之日起为三十 (30) 年),并按照双方商定的条款和条件以及董事会酌情决定的其他条件,保护和维护该县及其公民的利益,包括但不限于按规定方法计算年度替代从价税金额,该替代费用应等于在该县建造或安装的项目应缴纳的普通县和学校从价税的三分之一 (1/3),且该 FILOT 协议须经 MDA 批准和认证;但是,根据密西西比州的法律,任何特定的不动产或动产不得在超过十年 (10) 年的期限内受到 FILOT 协议的约束;

III 类代码长描述符
类别 III 代码 以下部分包含一组针对新兴技术、服务、程序和服务范例的临时代码。类别 III 代码允许收集这些服务或程序的数据,而使用未列出的代码则不能收集特定数据。如果有类别 III 代码,则必须报告此代码,而不是类别 I 未列出的代码。这项活动对于评估医疗保健服务和制定公共和私人政策至关重要。使用类别 III 代码可让医生和其他合格的医疗保健专业人员、保险公司、卫生服务研究人员和卫生政策专家确定新兴技术、服务、程序和服务范例的临床功效、利用率和结果。

代尔夫特理工大学资料库
在荷兰北部,科学技术教育始于莱顿,1600 年 1 月 9 日,毛里茨亲王宣布了一项由西蒙·斯蒂文设计的教育计划“DuytscbeMathematique”。第二天,数学家 Ludolf van Ceulen 接到任务,负责工程科学专业学生的数学和测量教育 1 。这所隶属于莱顿大学的工程学院基本上是一所高等专业培训机构。规定课程必须用荷兰语而不是拉丁语授课,这是学术教育的惯例,这强调了新工程教育计划的学生与传统学术计划的学生之间的差异。因此,在莱顿,毕业的工程师经常被描述为“相当普通的服务提供者,具有