XiaoMi-AI文件搜索系统
World File Search System子模型

2024; 15(3): 632-644. doi: 10.7150/jca.89581 研究论文探索头颈部鳞状细胞癌的预后免疫微环境相关基因
目的:头颈部鳞状细胞癌 (HNSCC) 具有较高的局部和远处转移率。在肿瘤组织中,肿瘤细胞与肿瘤微环境 (TME) 之间的相互作用与癌症的发展和预后密切相关。因此,筛选 HNSCC 中的 TME 相关基因对于了解转移模式至关重要。方法:我们的研究主要依赖于一种名为使用表达数据估计恶性肿瘤中的基质和免疫细胞 (ESTIMATE) 的新算法。从 TCGA 数据库中获取外显子模型每百万映射片段的每千碱基片段 (FPKM) 数据和 HNSCC 临床数据,并确定 HNSCC 组织的纯度以及基质和免疫细胞浸润的特征。此外,根据免疫、基质和 ESTIMATE 评分筛选差异表达基因 (DEG),并评估它们的蛋白质-蛋白质相互作用 (PPI) 网络和 ClueGO 功能。最后,确定了 HNSCC 中与免疫相关的 DEG 的表达谱。在高侵袭性口腔癌细胞系 (SCC-25、CAL-27 和 FaDu) 和口腔癌组织中验证了差异基因表达。结果:我们的分析发现免疫和 ESTIMATE 评分均与 HNSCC 的预后显着相关。此外,使用 Venn 算法进行交叉验证显示 433 个基因显着上调,394 个基因显着下调。所有 DEG 都与 ESTIMATE 和免疫评分相关。使用通路富集分析观察到细胞因子-细胞因子受体相互作用和趋化因子信号通路的富集。在分析了 PPI 网络的关键子网络后,我们初步筛选了 25 个基因。生存分析揭示了 CCR4、CXCR3、P2RY14、CCR2、CCR8 和 CCL19 与生存的关系以及它们与 HNSCC 中免疫浸润相关转移的关系。结论:使用 ESTIMATE 对基质和免疫细胞进行评分后,筛选了相关 TME 相关基因的表达谱,并确定了与生存相关的 DEG。这些 TME 相关基因标记物可作为 HNSCC 中的预后指标和指示转移性状的标记物,具有宝贵的实用性。

基于MRI的糖尿病和胃肠道症状受试者的泛主功能和运动性的定量
大规模生物量存储用于现代生物能源,由于生物量的内在自我加热引起了潜在的安全问题。尽管如此,在该领域进行了非常有限的研究。该项目通过开发一个综合的建模框架来填补一个关键的空白,以在生物质桩中进行自加热并进行一系列实验研究,以探索这些桩中复杂的子过程。本文仅介绍建模和测试工作的一小部分。它成功地证明了该模型在预测煤炭堆自动加热方面的有用性,从而指导煤炭储存的安全措施。在各种存储参数中,桩高,粒径和环境风速度已被确定为对煤桩内的自加热和自我命运产生重大影响。本文还说明了初始生物质水分含量对微生物反应性和氧气消耗率的明显影响。初始水分含量的增加显着提高了整体微生物反应性和氧气消耗率。小麦稻草在相同的储存条件下更容易自热,这可以证明,较高的热量产生,更快的氧气消耗以及较短的时间到达峰值温度。此外,发现微生物活性在生物质自加热中起着至关重要的作用,尤其是在热量累积的初始阶段,在0 - 75℃的温度范围内。对于此处讨论的建模,尽管桩上的流动较高,但必须将多孔桩中的流动视为层流。这是基于雷诺数的数量,该数字是根据速度的in-count量平均值和燃料颗粒的平均直径计算得出的,燃料颗粒的平均直径明显低于临界阈值(RE CR = 200)。可以将生物量桩中相关子过程得出的见解和子模型集成到模型框架中。这种整合将创建一个更全面,更强大的模型,以预测生物质储存桩中的自我加热和自命不凡,从而增强对这些现象的理论和实践管理。

clip2protect:使用文本引导的化妆通过对抗性潜在搜索
包括安全性[63],生物识别技术[38]和刑事侵犯[45],在许多情况下表现优于人类[12,48,61]。尽管这种技术的积极方面,但FR系统严重威胁了数字世界中的个人安全和隐私,因为它们有可能使大规模监视能力[1,67]。进行审查,政府和私人实体可以使用FR系统来通过刮擦Twitter,LinkedIn和Facebook等社交媒体资料的面部来跟踪用户关系和活动[18,20]。这些实体通常使用特定的FR系统,其规格是公众未知的(黑匣子模型)。因此,迫切需要采取一种有效的方法来保护面部隐私免受这种未知的FR系统的影响。理想的面部隐私保护算法必须在自然和隐私范围之间取得正确的平衡[70,77]。在这种情况下,“自然性”被定义为没有人类观察者很容易掌握的任何噪声伪影和人类认识的身份。“隐私保护”是指受保护图像必须能够欺骗黑盒恶意FR系统的事实。换句话说,被指定的图像必须与给定的面部图像非常相似,并且对于人类观察者而言是无伪影的,而同时欺骗了一个未知的自动化FR系统。由于产生自然主义面孔的失败会严重影响在社交媒体平台上的用户体验,因此它是采用隐私增强算法的必要预先条件。1)[22,25,39,72]。最近的作品利用对抗性攻击[57]通过覆盖原始面部图像[6,53,74]上的噪声约束(有限的)广泛扰动来掩盖用户身份。由于通常在图像空间中优化了对抗示例,因此通常很难同时实现自然性和隐私[70]。与基于噪声的方法不同,不受限制的对抗示例并未因图像空间中扰动的大小而影响,并且在对敌方有效的同时,对人类观察者来说表现出更好的感知现实主义[3,55,68,76]。已经做出了几项努力,以生成误导FR系统的不受限制的对抗示例(请参阅Tab。在其中,基于对抗化妆的方法[22,72]随着

脑积水水弹性模型中旋转流的数值模拟
I. 简介 许多研究人员已经基于多孔弹性构建了脑积水的计算理论。此类模型将有助于更好地理解问题,从而提供更好的治疗方法。此类模型还忽略了分流术的间歇性影响,而分流术是治疗脑积水最常用的方法。我们使用弹性和流体力学来创建人脑和脑室系统的数学模型。我们的模型通过考虑跨导水管的流动并包括边界约束来扩展以前的工作。这将为疾病的边界和改善创建一个定量模型。我们开发并解决了该模型的控制方程和边界条件以及有意义的临床发现。我们的模型通过将导水管流与边界约束结合起来,扩展了早期对脑积水的研究。脑脊液沿着脊髓周围的蛛网膜下腔向下流动,然后进入颅脑蛛网膜下腔,然而,物理定律很难解释这种流动是如何持续的。采用体内刺激的数学方法来研究脉动血液、脑和脑脊液的动态相互作用 1 。本文介绍的模拟是为患有脑脊液生理病理疾病脑积水的个体生成的 2 。研究特发性脑积水化学浓度不对称循环的后脑室通透性 3 。使用基本的几何模型,当前的研究提出了一种全新的脑积水多物理扩散过程方法,并作为更复杂的几何模拟的标准 4 。研究了脑脊液在心血管和蛛网膜下腔的循环以及脑脊液渗入多孔脑实质的问题。开发了复杂大脑几何形状的边界条件 5 。将标准受试者的研究信息与代表颅内动力学的实际计算模型进行了比较。该模型利用特定于受试者的磁共振 (MR) 图像和物理边界条件作为输入,可重现脉动的脑脊液循环并模拟颅内压力和流速 6 。该数值模型用于探索横截面几何形状和脊髓运动如何影响非稳定速度、剪应力和压力梯度场 7 。该系统分为五个子模型:动脉系统血液、静脉系统血液、心室脑脊液、颅内蛛网膜下腔和脊髓出血腔。阻力和顺应性将这些子模型连接起来。构建的模型用于模拟七个健康个体中发现的关键功能特征,例如动脉、静脉和脑脊液流量分布(幅度和相移) 8 。此前,利用时间分辨三维磁共振速度映射研究人体血管系统中健康和异常的血流模式。利用这种方法研究了 40 名健康志愿者 9 的脑室系统中脑脊液流量的时间和空间变化。这些颗粒中的脑脊液和血液之间的屏障很小,使脑脊液能够流入循环并被吸收。与脑脊液的产生相反,消耗是压力-

患者级可解释的机器学习,以预测SPECT MPI和CCTA成像的主要不良心血管事件
近年来,在摄影成像中使用机器学习(ML)技术的使用激增。作为评估潜在冠状动脉疾病(CAD)患者的成像方式的数量,并且该技术继续改善,在做出临床判断时,可以考虑大量数据。但是,大量变量和越来越多的成像数据可以使准确评估患者的挑战。人工智能(AI)和ML可以通过基于广泛的临床和成像变量的有用提示来帮助这一过程[1]。的确,ML算法已被证明是患者风险分层和诊断评估中的宝贵工具[2,3]。冠状动脉层析成像血管造影(CCTA)是一种用于评估CAD冠状动脉动脉的非侵入性诊断程序。它具有高的负预测值,允许负CCTA结果有效排除显着的CAD [4,5]。另一个重要的非侵入性诊断测试是单光子发射计算机断层扫描(SPECT),它主要评估冠状动脉狭窄和指南管理的功能意义。使用CCTA和SPECT添加了疑问涉嫌CAD的患者对牙菌斑和灌注负担的评估[6-8]。普遍的临床预测方法通常涉及专家选择潜在的相关变量,然后进行回归/分类分析。Automl旨在减轻开发出良好表现ML管道所需的计算成本和人类专业知识[9,10]。ML的最新进展使这种经典的方法限制性(仅使用一种模型类型),效率低下(需要用于超参数的手动调整)并可能有偏见(预测指标前定位)。尽管医疗保健中基于ML的预测模型的进步,但采用这些模型的一个主要障碍是,其中许多被认为是“黑匣子”,这是指缺乏可解释性[11]。呼吁对这些模型的运作方式进行更多研究[12-15]。无法解释预测模型可以侵蚀对它们的信任,尤其是在决策可能会带来严重后果的心血管医学中。在医学中,黑匣子模型将发挥重要作用,在许多情况下,与我们缺乏完全生物学或临床理解的其他领域没有太大的不同[16]。但是,就像了解疾病和疗法背后的机械主义是有益的一样,对ML模型如何得出的结论有了更大的了解[17]也是有帮助的。对可解释的ML的研究激增,以解决这个问题[18]。已经开发了探索AI预测背后推理的各种方法[19,20]。一种有效的方法是建立一个次要,更透明的模型,例如决策树或随机森林,输入

纵向单...
为了最大程度地减少与强制施用相关的纵向成像和潜在风险的辐射暴露,采取了二维(2D)非对比度轴向轴向单板CT CT,而不是在临床实践中常见的三维(3D)体积CT。然而,很难在纵向成像中找到相同的横截面位置,因此在不同年内捕获的器官和组织存在实质性变化,如图1。在2D腹部切片中扫描的器官和组织与身体成分措施密切相关。因此,增加的位置差异可以准确地分析身体组成的挑战。尽管有这个问题,但尚未提出任何方法来解决2D切片中位置差异的问题。我们的目标是减少位置方差在人体组成分析中的影响,以促进更精确的纵向解释。一个主要的挑战是,在不同年内进行的扫描之间的距离是未知的,因为该切片可以在任何腹部区域进行。图像注册是在其他情况下用于纠正姿势或位置错误的常用技术。但是,这种方法不适合解决2D采集中的平面运动,其中一种扫描中出现的组织/器官可能不会出现在另一种扫描中。基于参考。13,图像协调方法分为两个主要组:深度学习和统计方法。值得注意的统计方法包括战斗14及其变体,15-17 Convbat,18和贝叶斯因子回归。19然而,与生成模型不同,统计方法通常缺乏对我们方案至关重要的生成能力。基于深度学习的现代生成模型最近在生成和重建高质量和现实的图像方面取得了重大成功。20 - 26生成建模的基本概念是训练生成模型以学习分布,以便生成的样品 ^ x〜pdð ^xÞ来自与训练数据分布x〜pdðxÞ的分布相同。27通过学习输入和目标切片之间的联合分布,这些模型可以有效地解决注册的局限性。变化自动编码器(VAE),28是一种生成模型,由编码器和解码器组成。编码器将输入编码为可解释的潜在分布,解码器将潜在分布的样本解码为新数据。生成对抗网络(GAN)20是另一种类型的生成模型,其中包含两个子模型,一个生成新数据的生成器模型和一个区分实际图像和生成图像的歧视器。通过玩这个两人Min-Max游戏,Gans可以生成逼真的图像。Vaegan 29将GAN纳入VAE框架中,以创建更好的合成图像。通过使用歧视器来区分真实图像和生成的图像,Vaegan可以比传统的VAE模型产生更真实和高质量的图像。但是,原始的vaes和gan遭受了缺乏对产生图像的控制的局限性。有条件的GAN(CGAN)30和CONDINATION VAE(CVAE)31解决了此问题,该问题允许生成具有条件的特定图像,从而对生成的输出提供了更多控制。但是,这些条件方法中的大多数都需要特定的目标信息,例如目标类,语义图或热图,在测试阶段32作为条件,这在我们的情况下是不可行的,因为我们没有任何可用的直接目标信息。
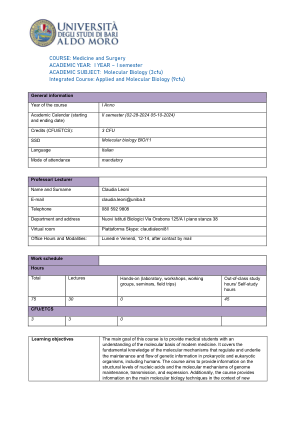
分子生物学(3cfu)综合课程
超螺旋和拓扑性质。拓扑异构酶。细菌类核。组蛋白和核小体的性质和组装。染色质的高级结构。组蛋白的翻译后修饰。溴多胺和染色质结构域。表观遗传学。原核生物和真核生物的基因组。复制模型。DNA合成。细菌DNA聚合酶。校对和缺口翻译。复制子模型。OriC和半甲基化。Ter/Tus。真核细胞核中的复制工厂。ARS结构和复制控制。酶学。前RC和前启动复合物。复制抑制剂,如化疗药物和抗病毒药物。端粒和端粒酶的结构、功能和意义。DNA损伤和修复。基因组作为动态实体。体细胞和种系突变。SNP。内在和外在损伤。化学和物理诱变剂。原核生物和真核生物中的去除、逆转和损伤避免系统。MUT 系统。BER 系统。糖基化酶的重要性。安全系统。NER 系统:UvrABCD 和 XP 蛋白。GG-NER 和 TC-NER。光解作用、MGMT、AlkBH。损伤耐受机制。TLS。细菌中的 SOS 反应。单丝和双丝断裂。HR 和 NHEJ。由于修复系统突变而导致的人类疾病。位点特异性重组。重组酶。Lambda 噬菌体。Cre-Lox 系统和 KO 小鼠。简单和复杂的转座子。SINE 和 LINE 元素、Alu 序列。原核生物和真核生物中的 RNA。结构、类型和特性。细菌 RNA 聚合酶和相关因子。转录单位。转录步骤。细菌启动子中的共识序列。终止机制。抑制剂。 Lac、ara 和 trp 操纵子。阳性和阴性对照。真核细胞中的 RNA 类别。RNA 聚合酶 (CTD) 的结构和功能。三种启动子的特征。基础转录机制。TFIIH。反式激活因子、辅激活因子。CpG 岛甲基化。组蛋白密码。长程调节剂。DNA 结合蛋白的功能域 (HTH、HD、HLH、ZF、LZ)。RNA 成熟、核运输和转录后控制。加帽类型。添加 polyA。CTD 的变化。外显子和内含子。外显子改组。四类内含子及其去除机制。剪接体和剪接位点。AT-AC 剪接。EJC 复合体。可变剪接。ESE 和 ESS 序列、SR 和 hnRNP 蛋白。SMN 基因。剪接和病理。rRNA 和 tRNA 加工反应。核糖体基因。 SnoRNA 和核仁功能。RNA 编辑。插入和转换编辑。人类 RNA 编辑的示例。细胞核和细胞质中的 RNA 周转。外泌体。无义介导的 mRNA 衰变 (NMD)。非编码 RNA。小 RNA 在细胞中的功能。RNA 干扰。siRNA。微小 RNA 的生物发生。miRNA、长链非编码 RNA、环状 RNA 的作用机制。逆转录病毒的一般信息。遗传密码和翻译。遗传密码的性质和特征。线粒体密码。ORF。tRNA 的特征。不常见碱基。aa-tRNA 合成酶的功能和类别。遗传密码的翻译重编码和扩展。SeCys。核糖体是一种核酶。原核生物和真核生物的翻译阶段。不同的启动机制。能量成本。NSMD。细菌中的 tmRNA。抑制剂。蛋白质的翻译后修饰、分选和降解。折叠和错误折叠。朊病毒。HSP60 和 HSP70。泛素和泛素化系统。SUMO 化糖基化。蛋白酶体。肽信号。蛋白质分选。线粒体输入。线粒体基因组细胞中的线粒体可塑性。人类线粒体基因组。遗传、结构、复制及其表达的原理。线粒体 DNA 中的改变。DNA 克隆的原理。修饰限制系统。克隆载体。cDNA 合成。基因组 DNA 和 cDNA 文库。TA 克隆。表达克隆。基因表达沉默。基因治疗。数据库。基因组编辑元件(Talen、Zn 指、CRISPR/Cas9 系统)。PCR 和 DNA 测序。PCR 的特性。PCR-RFLP。实时 PCR、DNA 测序。NGS。核酸杂交。杂交原理。熔点和严格性。探针制备:切口平移。Southern、Northern、杂交测定。蛋白质印迹。