XiaoMi-AI文件搜索系统
World File Search System市场

人工智能市场
[画外音] 认识 AI Markets。对于需要实时数据和见解的投资者,AI Markets 使用自然语言处理来了解他们的要求并立即获取,将大量全球市场数据从我们的交易柜台带到他们的交易柜台。这种人工智能的使用有助于以前所未有的速度满足我们客户的独特需求;并从汇丰的全球研究和交易数据、市场分析、定价和执行中找到他们所需的见解。在汇丰,这只是我们利用人工智能开辟机遇世界和拥抱创新以开发下一代数字银行的一种方式。免责声明:AI Markets 允许用户使用自然语言处理(“NLP”)访问某些汇丰数据,该处理提供了解释和理解人类语言的能力。AI Markets 使用的 NLP 解析器将尝试根据可用的数据将用户的查询与适当的答案进行匹配。此 NLP 模型的各个方面使用机器学习,机器学习是人工智能的一个子集,使用数学工具和算法来创建可用于进行预测的模型。AI Markets 不使用基于机器学习的生成式人工智能来获取文本或其他格式的内容并生成文本或其他格式的新上下文。AI Markets 提供的信息仅供参考,其准确性可能有所不同,仅供参考。

市场更新
委员会(“SEC”),包括 S-4 表格上的注册声明,该声明将包含 TechTarget 的代理声明,该声明也构成 NewCo 的招股说明书(“代理声明/招股说明书”)。最终的代理声明/招股说明书将邮寄给 TechTarget 的股东。TechTarget 和 NewCo 还可能向 SEC 提交有关拟议交易的其他文件。本通讯不能替代任何代理声明、注册声明或招股说明书,或 TechTarget 或 NewCo(视情况而定)可能就拟议交易向 SEC 提交的任何其他文件。在作出任何投票或投资决定之前,敬请TECHTARGET的投资者和证券持有人仔细完整地阅读代理声明/招股说明书(一旦发布)以及TECHTARGET或NEWCO向SEC提交的或将要提交的任何其他相关文件以及与拟议交易相关的这些文件的任何修订或补充(一旦发布),因为这些文件包含或将包含与拟议交易和相关事项有关的重要信息。 TechTarget 投资者和证券持有人将能够通过美国证券交易委员会维护的网站 www.sec.gov 免费获取代理声明/招股说明书(当其可用时)以及其他包含有关 TechTarget、NewCo 和拟议交易其他方(包括 Informa)的重要信息的文件副本。TechTarget 向美国证券交易委员会提交的文件副本可在 TechTarget 互联网网站 www.TechTarget.com 的“投资者关系”页面的“财务”标签下免费获取,或通过联系 TechTarget 投资者关系部 investor@TechTarget.com 获取。
市场审查
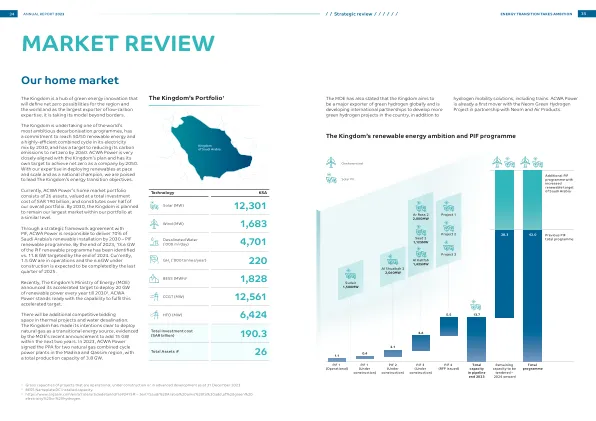
ACWA Power is currently constructing a 240 MW wind power plant in Azerbaijan, and has very recently singed a MoU with the State Oil Company of Azerbaijan Republic (SOCAR) and Abu Dhabi Future Energy Company (Masdar), to develop 500 MW of renewable energy projects in the Nakhchivan Autonomous Republic of the Republic of Azerbaijan, forging a strong partnership for future development in the country.在今年早些时候,针对大型项目的制定制定了四项实施协议,包括1 GW陆上,1.5 GW的海上风电场和一个电池储能项目与阿塞拜疆能源部签署。
市场回顾
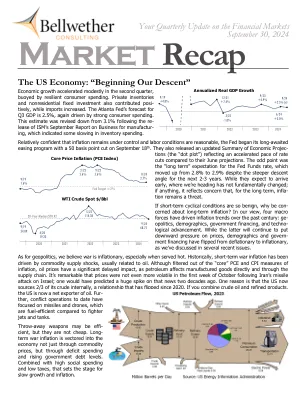
至于地缘政治,我们认为战争是通货膨胀的,尤其是当热门服务时。从历史上看,短期战争通货膨胀是由通常与石油有关的商品供应冲击驱动的。尽管从“核心” PCE和通货膨胀的CPI度量中过滤,但石油价格的影响很大,因为石油会直接和通过供应链影响制造商品。值得注意的是,在伊朗对以色列的导弹袭击之后,在10月的第一周,价格并没有更加动荡。人们会预测,二十年前,这一消息会有巨大的激增。一个原因是美国现在的原油中有2/3的资源,这种关系自2020年以来就已经翻转了。如果您将原油和精制产品结合在一起,那么美国现在是油的净出口国。迄今为止的冲突操作集中在导弹和无人机上,与战斗机和坦克相比,这是燃油效率的。



市场上的市场
•DeepSeek似乎比其他前沿模型更有效地训练了45倍的型号。清楚,DeepSeek的大多数方法已经存在。这是最大的成就:面对筹码禁令,弄清楚如何立即部署它们,并介绍其自身的自我增强学习•专家的混合:GPT-3.5使用其整个模型来解决培训和推理,尽管可能只需要一小部分模型。相比之下,GPT-4和DeepSeek是专家(MOE)模型的混合物,它们仅激活解决每个问题所需的模型的各个部分。DeepSeek V3的参数为6,710亿个,但在任何给定时间中只有370亿个活动•MLA是指“多头潜能”,这是对DeepSeek保持较小的存储器的行话,而在运行的过程中,•其他deepseek效率方法在运行•与BF16或FP3精确的过程中存储的其他deepseek效率方法,这些方法是供应fp3的精确量,它们是精确的。模型还使用多言语预测(MTP),而不仅仅是预测下一代币,这将准确性降低了约10%,但提出速度却增加了一倍,但DeepSeek声称V3非常便宜,需要2.7毫米H800 GPU小时,这是$ 2/GPU时的费用,只需$ 2/GPU时,只有5600万美元2美元。Llama 3.1 405B最终训练运行的GPU小时数量可比数量高约10倍3。需要进行更多的分析来确定这种过度专业化是否是一个更广泛的问题•DeepSeek今天早上刚刚宣布了另一个版本:多模式模型(文本,图像生成和解释)。DeepSeek明确指出,这是最终培训的成本,不包括“与先前的研究和消融实验相关的架构,算法或数据相关的成本”•DeepSeek V3性能与OpenAI的4O和Anthropic的SONNET-3.5竞争,并且似乎比Llama最大的培训成本更好。DeepSeek提供的API访问为每百万个令牌0.14美元,而Openai则收取每百万个令牌4 $ 750;也许某种程度的损失领导者定价•DeepSeek可能“过度指定”其模型:它在MMLU基准测试上做得很好,但是当问题略有变化时,其性能的下降速度比其他型号更快。毫不奇怪,DeepSeek不假装数据隐私并存储所有内容