XiaoMi-AI文件搜索系统
World File Search System成对比较

对支持飞机定期维护计划制定失败的运营后果的评估
已经对涉及飞机故障及其对商业航空公司运营影响的可能情景进行了一些实证研究。通过文档研究和访谈提取了实证数据,并以事件树分析 (ETA) 为指导。该分析由飞机制造商和商业航空公司的经验丰富的从业人员共同进行,这有助于对研究结果进行持续验证。最后,该研究还估算了已确定的故障运营后果的相关成本。为了量化故障的运营后果,在缺乏足够和可靠数据的情况下,已经采用成对比较技术的方法来有效提取专家的判断。

ES4C06645_SI_001.pdf
图S6。 (a)纳米颗粒尺寸浓度和(b)小提琴图,在1 d,15 d,15 d和30 d的PET颗粒和30 d的PET颗粒和5 mm AC中插入粒度分布的盒子图。 在A中,实线表示粒子浓度的平均值,阴影代表95%的机密间隔。 在B中,框图的顶部和底部边缘分别表示第一个四分位数和第三四分位数,内部线代表中位数,晶须表示数据中的上极端和下极端。 小提琴图的宽度说明了不同粒径的浓度。 在(b)中,由于不同条件下的样本量和方差不相等,对韦尔奇的t检验进行了成对比较(* p <0.05,** p <0.01,*** p <0.001)。 在每个孵育时间从一个生物复制中收集数据。图S6。(a)纳米颗粒尺寸浓度和(b)小提琴图,在1 d,15 d,15 d和30 d的PET颗粒和30 d的PET颗粒和5 mm AC中插入粒度分布的盒子图。在A中,实线表示粒子浓度的平均值,阴影代表95%的机密间隔。在B中,框图的顶部和底部边缘分别表示第一个四分位数和第三四分位数,内部线代表中位数,晶须表示数据中的上极端和下极端。小提琴图的宽度说明了不同粒径的浓度。在(b)中,由于不同条件下的样本量和方差不相等,对韦尔奇的t检验进行了成对比较(* p <0.05,** p <0.01,*** p <0.001)。在每个孵育时间从一个生物复制中收集数据。


转录因子凝结物的工程材料特性控制哺乳动物细胞和小鼠中的基因表达
和进一步经历了同性恋,导致多价相互作用和LLP的诱导。VP16被募集到CMV最小启动子提供的转录起始位点,并诱导报告基因表达。(b)调整转化因子冷凝物的材料特性。要修改凝结物材料特性,采用了两种策略:首先,通过将CRY2换成Cry2 Olig,从而增加了相互作用的价值,而Cry2 Olig构成了高阶寡聚物;其次,通过共转染编码融合到麦克里(可视化)和fus n和nLS的cry2 olig的结构来提高价值和浓度。与CRY2-EYFP-FUS N -VP16或CREY2 OLIG -EYFP-FUS N -VP16构建体(黄色和绿色数据点)共转染了编码CIBN-TER和基于TETO 4的SEAP报告基因。可选地,添加了编码Cry2 Olig -MCH -MCH -FUS n -nls的构造(以2:1的质粒量比为2:1相对于含VP16的构建体,红色和黑色数据点)。在进行FRAP分析之前,将细胞在黑暗中培养32小时。蓝光照明10分钟后(2.5 µmol m -²S-1)开始。 图像在液滴漂白之前直接显示出反应性核。比例尺= 5 µm。 图显示了根据n≥7凝结物回收曲线的非线性拟合计算出的移动部分的平均值和单个值(请参见右图)。 使用学生的t.test(*=p≤0.05; **** =p≤0.0001)进行成对比较。。图像在液滴漂白之前直接显示出反应性核。比例尺= 5 µm。图显示了根据n≥7凝结物回收曲线的非线性拟合计算出的移动部分的平均值和单个值(请参见右图)。使用学生的t.test(*=p≤0.05; **** =p≤0.0001)进行成对比较。
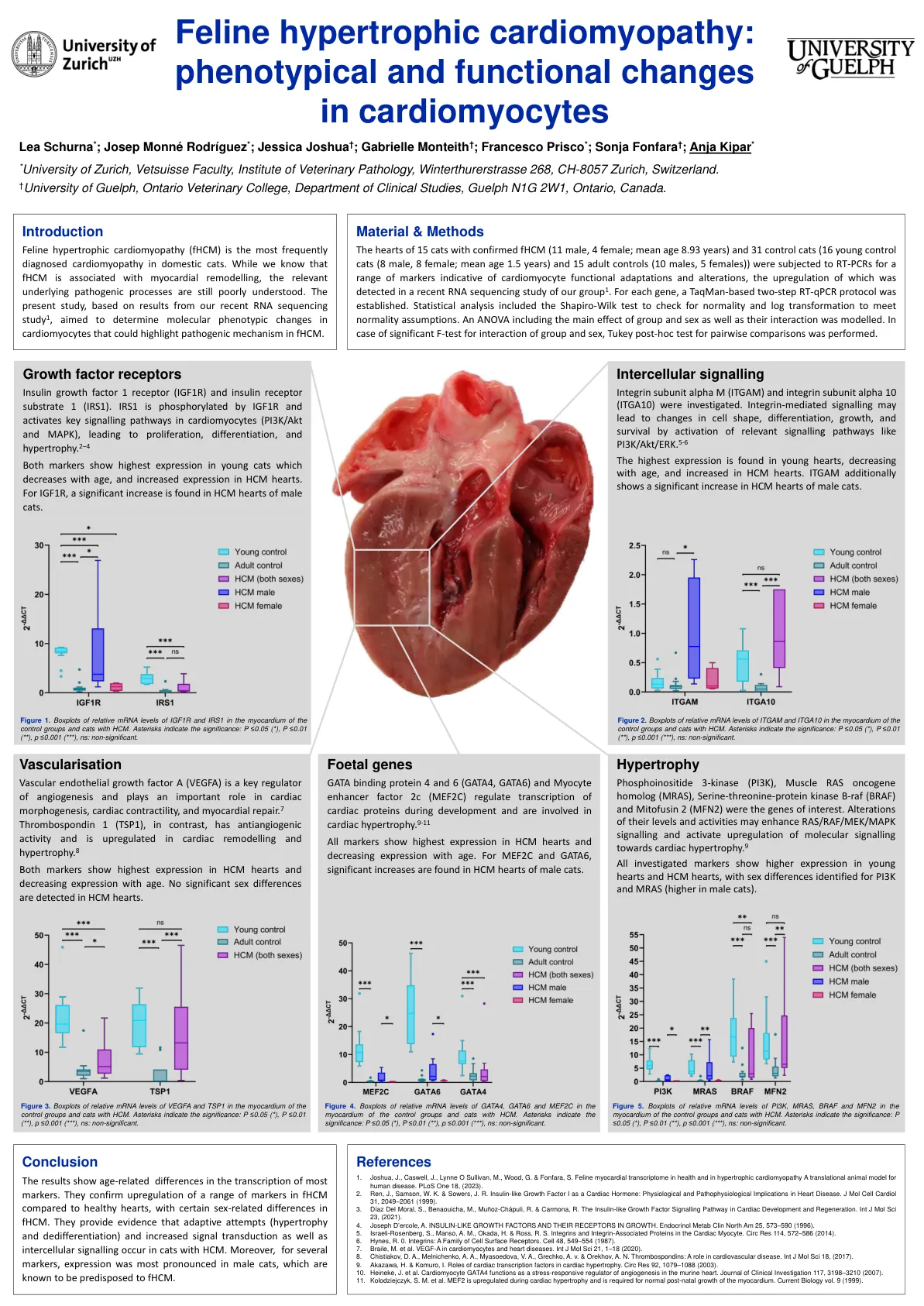
心肌细胞的表型和功能变化
对 15 只确诊为 fHCM 的猫(11 只雄性,4 只雌性;平均年龄 8.93 岁)和 31 只对照猫(16 只幼年对照猫(8 只雄性,8 只雌性;平均年龄 1.5 岁)和 15 只成年对照猫(10 只雄性,5 只雌性))的心脏进行 RT-PCR,检测一系列表明心肌细胞功能适应和改变的标志物,在我们最近对第 1 组的 RNA 测序研究中检测到了这些标志物的上调。对于每个基因,建立了基于 TaqMan 的两步 RT-qPCR 方案。统计分析包括 Shapiro-Wilk 检验以检查正态性,以及对数变换以满足正态性假设。建立了包括组别和性别的主效应及其相互作用的方差分析模型。如果组别和性别的相互作用的 F 检验显著,则进行 Tukey 事后检验以进行成对比较。

评估Chatgpt和Google Gemini的表现以及土耳其牙科教育中的含义
结合了这两年(238个总问题),ChatGpt-O1和Gemini 2.0的结果,高级率为97.46%(230个正确答案,95%CI:94.62%,100.00%)和97.90%和97.90%(231个正确答案,95%CI:95%CI:94.62%,100.00.00%),显着地聊天 - 聊天88,4.4%,4.4%,聊天88(chat)。 211正确答案,95%CI:85.43%,91.89%)和双子座1.5 Pro(91.60%,218个正确答案,95%CI:87.75%,95.45%)。统计分析显示模型之间存在显着差异(p = 0.0002)。成对比较表明,与Chatgpt-O1(P = 0.0016)和Bonferroni校正后的Gemini 2.0 Advanced(P = 0.0007)相比,Chatgpt-4O的表现显着不足。最佳模型的始终高准确性率和狭窄的置信区间强调了它们在回答DUS问题时的优异可靠性和表现。

调查迅速变化的欧洲北极地区的上层生物多样性和胶状浮游生物社区:EDNA METABARCODING调查
fi g u r e 2上升后生阿尔法和β多样性模式。(a)在每个深度区域和采样位置,海洋后生动物门的相对读取丰度。(b)香农多样性指数(H')和(c)在所有四个深站组合的每个深度区域的SRS的物种丰富度标准化的Motus数据。Tukey的HSD成对比较与Tukey调整后的P值进行了比较。*表示<0.05的显着差异,****表示显着差异<0.001。(d)基于jaccard距离的Motus社区结构(K = 2)的非线性多维标度。颜色表示海洋区,点形表示站点,地块上显示的应力值。深度区域被定义为上皮(0-99 m),下层(100-200 m),中质质量(201-1000 m)和浴类质(> 1000 m)。

估计令牌在偏好学习中的影响
在巨大的文本语料库中鉴定的大型语言模型(LLM)表现出了各种自然语言处理任务的非凡能力[Brown,2020]。但是,这些模型通常显示出偏见或有毒行为,以及如何使它们与人类价值观保持一致仍然是一个开放的问题。最近,通过将其作为加强学习(RL)问题来解决这个问题,目的是最大化人类偏好。这种方法,也称为人类反馈(RLHF)[Christiano等人,2017年,Stiennon等,2020],已成为使LLMS对齐的主要方式。将偏好学习作为RL问题,一个重要的问题是如何定义奖励功能。以前,这通常是使用成对比较模型(例如Bradley-Terry模型[Bradley and Terry,1952])建模的。但是,正如Munos等人指出的那样,这可能是有问题的。[2023],而解决此问题的一种更自然的方法是将其作为游戏进行。在目前的工作中,我们遵循这种方法,并将其与可以看待优势函数的想法结合使用以编码动作的因果效应[Pan等,2022],并证明这使我们能够量化代币在RLHF环境中的因果效应。

remerelination保护神经元免受DLK
alpha多样性 - 盒子代表第一四分位数和第三四分位数之间的四分位间范围(IQR),水平线表示中位数,晶须是IQR的1.5倍的上和下值。alpha多样性。(a)Pielou的均匀度显示出显着差异(H = 85.7,P = 1.07E-17)。成对比较表明,印第安人(n = 61)的均匀均高于欧洲 - 加拿大人(n = 41)(h = 56.2,q = 6.51e-13),欧洲进军者(n = 23)(h = 17.0,q = 17.0,q = 7.32e-05)和印尼 - 加拿大人(q = 7.32e-05)和印尼 - 加拿大人(n = 17)(n = 17)(q = 1.8)(Q = 1.8),Q = 1.8,Q = 1.8,Q = 1.8,Q = 1.8,Q = 1.8,Q = 1.8,Q = 1.8。欧洲 - 加拿大对照组的得分也明显高于印度移民(n = 32)(h = 41.4,q = 6.09e-10)和印度 - 加拿大人(h = 21.7,q = 8.10e-06)。(b)也发现了香农的多样性,显示出明显的差异(H = 79.8,p = 1.89e-16)。*** =q≤0.001,** =q≤0.01, * =q≤0.05
![arXiv:2310.01432v3 [cs.CL] 2024 年 12 月 9 日](/simg/e\e7ceb8e93071edf9a053df0cbcf1b011fa58d8b3.webp)
arXiv:2310.01432v3 [cs.CL] 2024 年 12 月 9 日
大型语言模型 (LLM) 已显示出作为评估 AI 系统生成的答案质量的自动评估器的前景。然而,基于 LLM 的评估器在用于评估成对比较中的候选答案时表现出位置偏差或不一致性,无论内容如何,都会偏向第一个或第二个答案。为了解决这个限制,我们提出了 P ORTIA,这是一个基于对齐的系统,旨在模仿人类的比较策略,以轻量级但有效的方式校准位置偏差。具体来说,P ORTIA 将答案分成多个部分,同时考虑长度和语义,然后将它们合并回单个提示以供 LLM 评估。对 6 个 LLM 对 11,520 个答案对进行的大量实验表明,P ORTIA 显着提高了所有模型和比较形式的一致性率,平均相对提高 47.46%。它还使 P ORTIA 增强型 GPT-3.5 能够实现与 GPT-4 相当的与人类的一致率,并将 GPT-4 的一致率提高到 98%。后续的人工评估表明,P ORTIA 增强型 GPT-3.5 模型在与人类评估者的一致性方面甚至可以超越独立的 GPT-4,凸显了 P ORTIA 纠正立场偏见、提高 LLM 一致性和提高性能的同时保持成本效率的能力。