XiaoMi-AI文件搜索系统
World File Search System拼写

编码多音节:长 a 拼写为 ay、a_e、ai 状态...
提供独立练习。轮到你了。仔细考虑单词 explain 的拼写。这个单词是什么?仅限学生:explain 第一步是什么?学生:点击音节。开始吧。学生:ex(tap)plain(tap)第二步是什么?学生:扩展并拼写每个音节。扩展并拼写 ex 。你是怎么拼写 /ĕĕĕ/ 的?学生:e 写下来。你是怎么拼写 /ks/ 的?学生:x 写下来。再次点击 explain 中的音节。学生:ex(tap)plain(tap)第二个音节是什么?学生:plain 扩展并拼写 plain 。你是怎么拼写 /p/ 的?学生:p 写下来。你是怎么拼写 /lll/ 的?学生:l 写下来。你必须从多个拼写模式中选择一种来拼写 /āāā/ 吗?学生:是的在 /āāā/ 的拼写位置画一个空白。plain 的最后一个音是什么?学生:/nnn/ 你如何拼写 /nnn/?学生:n 写下来。第三步是什么?学生:排除不能使用的模式。思考:哪些模式不能用来拼写普通话中的 /āāā/?给学生时间思考和回答。可能的答案:_ay 不能使用;它通常位于单词末尾,后面没有辅音第四步是什么?学生:选择剩下的一个模式来拼写声音。你能做些什么来帮助你决定选择哪种模式?学生:用两种方式写出来做吧。看看两个单词(explane 和 explain)。哪一个看起来正确?让学生讨论两个选项并选择他们认为正确的那个。正确答案的支架:解释。通过指向每个模式并说出声音来检查你的工作。这个词是什么?学生:解释

长 Aa 拼写为 ai 或 ay 组件
音节中 /āāā/ 之前的辅音。这种拼写通常用于单词末尾。我们将这个模式读作 _ay。• 指向 ai_。这个模式叫什么?学生和老师:ai 空白 它拼写什么声音?学生和老师:/āāā/ • 指向 _ay。这个模式叫什么?学生和老师:空白 ay 它拼写什么声音?学生和老师:/āāā/ • 我将使用我们的解码策略来阅读一个包含长 a 的单词,拼写为 ai_ 或 _ay。把单词 complaint 写在黑板上。让我们假装不认识这个词。我将使用阅读大词策略来弄清楚。首先,我在单词中的元音下划线。在 o 和 ai 下划线。我知道音节中一个 o 后面如果有一个辅音,就会发 /ŏŏŏ/ 的声音。我将 a 和 i 一起划线,因为这两个元音合在一起发音为 /āāā/。接下来,我寻找我知道的其他部分。我在每个部分下面都打一个点。在 c、m、p、l 和 t 下打点,同时说出它们发出的发音。我知道这个单词的所有部分,这意味着我能读懂它。我知道这个单词有两个元音,这意味着它有两个音节。我仔细查看每个音节,确保每个音节都包含一个元音。我会在每个元音之前和/或之后添加一个或两个辅音。仔细查看 com 和 plaint 。现在,我读音节,如果需要,就发音:/kŏm/ /plānt/, com'plaint'。听起来不太对,所以我会弯曲元音。我会把 /ŏŏŏ/ 的发音改成中元音:/kƏm/ /plānt/。投诉!这很有道理。

拼写脑机接口中基于图像刺激的两种范式比较
摘要:基于 P300 的拼写器可用于通过大脑活动控制家庭自动化系统。评估基于 P300 的拼写器中使用的视觉刺激是脑机接口 (BCI) 领域的常见主题。本研究的目的是使用可用性方法比较两种在以前的研究中表现优异的刺激类型。12 名参与者在两种条件下控制 BCI,这两种条件下的刺激类型不同:一个红色名人脸被白色矩形 (RFW) 包围,以及一系列中性图片 (NPs)。可用性方法包括与有效性(准确性和信息传输率)、效率(压力和疲劳)和满意度(愉悦度和系统可用性量表和情感网格问卷)相关的变量。结果表明,有效性没有显著差异,但使用 NPs 的系统报告的愉悦度明显更高。因此,由于在潜在用户可能经常使用的系统中也应该考虑满意度变量,因此对于基于视觉 P300 拼写器的家庭自动化系统的开发来说,使用不同的 NP 可能比使用单个 RFW 更合适。

附录B:单词研究,阅读和拼写的letrs范围和序列
Louisa C. Moats和Carol A. Tolman此图表基于阅读和拼写课程的习惯位置。该场中没有一个接受的范围和序列。阅读和拼写的年级水平近似,并且根据学生的成就水平会有所不同。进展旨在逐渐从简单到更复杂的语言结构移动。

P300 脑机接口拼写器的进展
脑机接口(BCI)是一种非肌肉通信技术,为大脑和外部设备提供信息交换通道。几十年来,BCI取得了显著进展并被应用于许多领域。最传统的BCI应用之一是BCI拼写器。本文主要讨论P300 BCI拼写器的研究进展,并回顾了四类P300拼写器:单模态P300拼写器、基于多种脑模式的P300拼写器、具有多感觉刺激的P300拼写器和具有多种智能技术的P300拼写器。对于每一类P300拼写器,我们进一步回顾了几种具有代表性的P300拼写器,包括它们的设计原理、范式、算法、实验性能和相应的优势。我们特别强调了范式设计思想,包括整体布局、单个符号形状和刺激形式。此外,还确定了P300拼写器的几个重要问题和研究指导。希望本综述能帮助研究人员了解这些新型P300拼写工具的新思路,提升其实际应用能力。

无需用户特定训练即可为 SSVEP BCI 拼写者迁移学习一组 DNN
摘要 — 目标:用脑电图 (EEG) 测量的稳态视觉诱发电位 (SSVEP) 在脑机接口 (BCI) 拼写器中产生不错的信息传输速率 (ITR)。然而,目前文献中高性能的 SSVEP BCI 拼写器需要对每个新用户进行初始冗长而累人的用户特定训练以适应系统,包括使用 EEG 实验收集数据、算法训练和校准(所有这些都在实际使用系统之前)。这阻碍了 BCI 的广泛使用。为了确保实用性,我们提出了一种基于深度神经网络 (DNN) 集合的全新目标识别方法,该方法不需要任何类型的用户特定训练。方法:我们利用先前进行的 EEG 实验的参与者的现有文献数据集,首先训练一个全局目标识别器 DNN,然后针对每个参与者进行微调。我们将这组经过微调的 DNN 集合转移到新的用户实例,根据参与者与新用户的统计相似性确定 k 个最具代表性的 DNN,并通过集合预测的加权组合来预测目标字符。结果:在两个大规模基准和 BETA 数据集上,我们的方法实现了令人印象深刻的 155.51 比特/分钟和 114.64 比特/分钟 ITR。代码可用于重现性:https://github.com/osmanberke/Ensemble-of-DNNs 结论:在两个数据集上,对于所有刺激持续时间在 [0.2-1.0] 秒内的情况,所提出的方法都明显优于所有最先进的替代方案。意义:我们的 Ensemble-DNN 方法有可能促进 BCI 拼写器在日常生活中的实际广泛部署,因为我们提供最高性能,同时允许立即使用系统而无需任何用户特定的训练。索引词 — 脑机接口、BCI、EEG、SSVEP、集成、深度学习、迁移学习
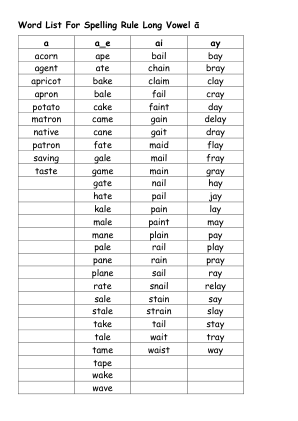
拼写规则 长元音 ā 的单词列表
e ee ea y ee 自我 啤酒 击败 婴儿 蜜蜂 埃及 爬行 欺骗 肚子 费用 平等 行为 奶油 爸爸 逃跑 甚至 鹿 梦想 小狗 免费 晚上 喂养 恐惧 快乐 李 邪恶 感觉 壮举 山丘 小便 唤起 脚 跳蚤 生气 看到 贪婪 齿轮 木乃伊 树 下面 脚跟 热 尿布 twee 细节 见面 餐 小狗 小猫 针 肉 流鼻涕 耶稣 窥视 豌豆 潮湿 仪表 女王 花生 湿漉漉的 报告 礁石 泥炭 阳光明媚 亮片 种子 恳求 泰迪熊 似乎 阅读 美味 渗透 印章 羊 座位 睡觉 小麦 速度 陡峭 扫掠 青少年 牙齿 杂草 哭泣 轮子

微小的噪音,大错误:对抗性扰动会在脑 - 计算机接口拼写中引起错误
1教育部图像处理和智能控制的主要实验室,人工智能与自动化学院,华恩科学技术大学,武汉430074,中国; 2华盛科技大学土木工程与力学学院,中国武汉430074; 3工程与信息技术学院人工智能中心,悉尼科技大学,悉尼,新南威尔士州,2007年,澳大利亚; 4美国加利福尼亚州加利福尼亚大学圣地亚哥分校神经计算学院Swartz计算神经科学中心,美国加利福尼亚州92093,美国; 5美国加利福尼亚州加利福尼亚大学圣地亚哥大学医学工程学院高级神经工程中心,美国加利福尼亚州,加利福尼亚州92093,美国和6 Zhaw Datalab,ZéurichApplied Sciences of Applied Sciences,Winterthur 8401,瑞士,


通过优化和机器学习提高 P300 拼写器的性能
摘要 脑机接口 (BCI) 是一种允许人们绕过周围神经系统 (PNS) 的自然神经肌肉和激素输出与环境互动的系统。这些接口记录用户的大脑活动并将其转换为外部设备的控制命令,从而为 PNS 提供额外的人工输出。在这一框架中,基于 P300 事件相关电位 (ERP) 的 BCI 已被证明特别成功和强大,ERP 表示特定事件或刺激后从大脑记录下来的电反应。通过分类算法确定 EEG 特征中是否存在 P300 诱发电位。线性分类器(例如逐步线性判别分析和支持向量机 (SVM))是 ERP 分类中最常用的判别算法。由于 EEG 信号的信噪比较低,因此在对信号进行分类之前,需要执行多个刺激序列(又称迭代)并取平均值。然而,虽然增加迭代次数可以提高信噪比,但也会减慢该过程。在早期的研究中,迭代次数是固定的(无停止环境),但最近文献中提出了几种提前停止策略,以便在满足某个标准时动态中断刺激序列,以提高通信速率。在这项工作中,我们探索了如何通过结合优化和机器学习来提高基于 P300 的 BCI 中的分类性能。首先,我们提出了一个新的决策函数,旨在提高无停止和提前停止环境中的分类性能(准确度和信息传输速率)。然后,我们提出了一个新的 SVM 训练问题,旨在促进目标检测过程。我们的方法在几个公开可用的数据集上被证明是有效的。