XiaoMi-AI文件搜索系统
World File Search System查询

1型糖尿病和无序饮食:议会查询
该报告特别指出,在服务方法中,糖尿病的不同方面和饮食失调专家之间缺乏整合,以及数据的收集和共享。这种不一致给T1DE患者的成功治疗和管理带来了风险。解决这些问题需要开发标准化的T1DE途径,常见框架和改进的技术基础架构,以确保NHS内所有专业的安全,道德和有效的数据共享。确定了良好的实践,尤其是NHS英格兰飞行员的作用。但是,应该指出的是,尽管NHS英格兰的国家糖尿病计划可以为飞行员提供资金,但在飞行员完成后,经营服务的永久费用,然后成为地方委托委员会的责任。担心当地专员会判断综合T1DE服务提供的相对费用太高而无法筹集资金,鉴于当地的T1DE需要这种服务的当地人口相对较少。此外,本报告还认识到有关T1DE相对于其复杂性规模进行的有限研究,这表明需要进一步研究和理解。

英国政府关于残疾就业差距查询的信
附件1访问工作方案138。委员会欢迎通过访问工作计划及其背后的意图获得的支持。它与证人一致,但是该计划以目前的形式太慢且限制性,尤其是在冗长的申请过程和资金上限方面。139。委员会呼吁英国政府在打算审查该计划以使其更加精简和响应迅速的计划时提出。尤其是委员会向英国政府建议,它认为删除资金上限,证人建议这是该计划的主要限制。委员会进一步建议,为目前尚不为其最佳服务的自由职业者和自由职业者建立特定计划。140。该报告的这一部分以及为此做出贡献的人的生活经验吸引了国务卿工作和养老金和苏格兰国务卿的注意。访问工作计划为残疾人以及患有健康状况的人提供赠款。要有资格获得工作,申请人需要从事有偿工作(或即将在12周内开始或返回工作)。一项工作可以是全职的或兼职的,可以包括就业,自雇,学徒制,工作审判或工作经验,实习或工作安置。对自雇客户的资格与其他形式的就业形式相同。自雇客户的申请要求对申请人的自我就业收入进行检查。最新的官方统计数据(2023/2024财政年度)所反映的工作计划的访问量很高。在2023/2024年,有67,720人获得了批准的工作支持,在2022/2023中增加了36%。总支出为2.578亿英镑,2022/2023增长了33%。DWP认识到有关访问工作应用程序的延迟,这些延迟对客户的影响。我们致力于改善客户体验并减少等待时间。为了帮助减少积压,该部门简化了交付惯例,并培训了其他人员来处理申请。另外还有118名员工被重新部署以支持申请。该计划自1994年成立以来,该计划一直保持不变,而在此期间,我们对残疾人的理解已经改变了,客户的需求也发生了变化。我们已经采取了一些步骤来现代化工作访问以改善客户体验。从2024年4月开始,该计划的所有核心元素都变得完全数字化,客户能够在线申请并提出付款请求。

英国的决定性十年 - 经济2030查询
英国最近的过去以停滞的生活水平,生产力疲软,投资低和不平等的高度标志。这使得需要一种新的经济方法。使这一点至关重要的是即将到来的挑战规模。英国现在面临十年的变化,因为Covid-19的后果和持续的技术进步与英国退欧和净零过渡融为一体。必须很好地管理这些直接的后果,而那些在整个过程中失去支持的人。这些冲击还将重塑必须建立新的经济战略的背景。这对经济学而言要多得多。缓慢的增长,高度不平等和严重处理的经济破坏破坏了福祉,加剧了社会分裂并带来持久影响的政治问题。

流查询矢量化的HD-MAP构造
高清地图(HD-MAP)的至关重要目的是为地图元素提供厘米级别的位置信息,并在自主驾驶中的各种应用中扮演着关键的角色,包括本地化[6,23,32,33,35,38]和Navigation [1,2,11]。传统上,HD-MAP的构建是通过基于SLAM的方法[30,40]离线进行的,这既是耗时又是劳动力密集的。最近的研究努力已转向使用船上的预定范围内的本地地图的建造。尽管许多现有的作品框架构造作为语义序列任务[17,24,27,29,41],但这种方法中的栅格化表示表现出冗余的信息,缺乏地图元素之间的结构关系,并且通常需要广泛的后处理工作[17]。响应这些局限性,MAPTR [19]采用了一种端到端的方法来构建vecter ver的地图,类似于Detr范式[4,5,21,42]。

关于关系数据库和大语言模型的混合查询
数据库传统上查询在封闭世界中运行,对超出数据库中存储的数据之外的问题的问题没有提供任何答案。使用SQL的混合查询通过将关系数据库与大型语言模型(LLMS)集成在一起以回答超越数据库问题,从而提供了替代方案。在本文中,我们介绍了第一个跨域基准,天鹅,其中包含120个超越数据库问题的问题。为了利用最新的语言模型来解决天鹅中的这些复杂问题,我们提出了两个解决方案:一个基于模式扩展,另一个基于用户定义的功能。我们还讨论优化机会和潜在的未来方向。我们的评估表明,使用GPT-4 Turbo几乎没有提示,可以实现高达40.0%的执行准确性,而数据事实可达到48.2%。这些结果突出了混合查询的潜力和挑战。我们认为,我们的工作将激发进一步的研究,以创建更有效,更准确的数据系统,这些数据系统无缝整合关系数据库和大型语言模型,以解决超越数据库问题。
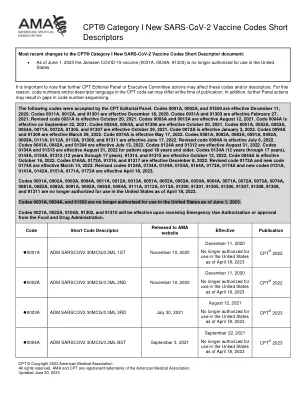
COVID-19,用于患者查询的疫苗脚本
CPT编辑面板接受以下代码。代码0001A,0002A和91300是生效的2020年12月11日。代码0011A,0012A和91301于2020年12月18日生效。代码0031A和91303是生效的,2021年2月27日。修订的代码0031A于2021年10月20日生效。代码0003A和0013A于2021年8月12日生效。代码0004A于2021年9月22日生效。代码0034A,0064A和91306于2021年10月20日生效。代码0051A,0052A,0053A,0054A,0071A,0072A,91305和91307于10月29日生效,2021年10月29日。代码0073A于2022年1月3日生效。代码0094A和91309于2022年3月29日生效。代码0074A是生效的2022年5月17日。代码0081A,0082A,0083A,0091A,0092A,0093A,0093A,0111A,0112A,0112A,0113A,91308和91311于6月17日生效,2022年6月17日生效。修订的代码0094A于2022年7月6日生效。代码0041A,0042A和91304于2022年7月13日生效。代码0124A和91312是生效的,2022年8月31日。代码0134a和91313于2022年8月31日生效,年龄在18岁及以上。代码0134A(12年至17年),0144A,0154A,91313(12年至17年),91314和91315是生效的,2022年10月12日生效。代码0044A于2022年10月19日生效。代码0164a,0173a,91316和91317是生效的,2022年12月8日。修订的代码0173A和新代码0174A是生效的,2023年3月14日。修订的代码0124A,0134A,0144A,0154A,0164A,0173A,0173A,0174A和新代码0121A,0141A,0141A,0142A,0151A,0151A,0171A,0171A,0172A,0172A是4月18日,2023年4月18日,2023年4月18日。Codes 0001A, 0002A, 0003A, 0004A, 0011A, 0012A, 0013A, 0051A, 0052A, 0053A, 0054A, 0064A, 0071A, 0072A, 0073A, 0074A, 0081A, 0082A, 0083A, 0091A,0092A,0093A,0094A,0111A,0112A,0112A,0113A,91300,91301,91301,91305,91306,91307,91307,91308,91308,91309和91311不再在4月18日的Unitedal授权使用,以在4月18日,2023年4月18日。代码0031A,0034A和91303不再在2023年6月1日在美国使用。代码0021A,0022A,0104A,91302和91310在获得食品和药物管理局的紧急使用授权或批准后将有效。

钻石距离中统一通道的查询最佳估计
我们考虑统一量子通道的过程断层扫描。给定对作用于D维Qudit的未知统一通道的访问,我们旨在输出对ε-close的统一的经典描述,即ε-close的钻石规范中未知的统一。我们使用未知通道的O(D 2 /ε)应用来设计算法实现误差ε和仅一个Qudit。这改善了先前的结果,这些结果使用O(D 3 /ε2)[通过标准过程断层扫描]或O(D 2。< /div>)5 /ε)[Yang,Renner和Chiribella,Prl 2020]应用。为了显示此结果,我们引入了一种简单的技术来“引导”一种算法,该算法可以通过Heisenberg缩放来产生可以产生εError估计的恒定估计值。最后,我们证明了一个互补的下限,即使访问未知统一的逆版本或受控版本,估计也需要ω(D 2 /ε)应用。这表明我们的算法既具有最佳的查询复杂性又具有最佳空间复杂性。

生物医学文档检索的叙事查询图(技术报告)
基于关键字的搜索是当今数字库中的标准。然而,像科学知识库中的复杂检索场景一样,需要更复杂的访问路径。尽管每个文档在某种程度上有助于一个领域的知识体系,但关键字之间的外部结构,即它们的可能关系以及每个单个文档中跨越的上下文对于有效检索至关重要。遵循此逻辑,可以将单个文档视为小规模的知识图,图形查询可以提供重点文档检索。我们为生物医学领域实施了一个完全基于图的发现系统,并证明了其过去的好处。不幸的是,基于图的检索方法通常遵循“确切的匹配”范式,该范式严重阻碍了搜索效率,因为确切的匹配结果很难按相关性进行排名。本文扩展了我们现有的发现系统,并贡献了有效的基于图的无监督排名方法,一种新的查询放松范式和本体论重写。这些扩展程序进一步改善了系统,因此由于部分匹配和本体论重写,用户可以以更高的精度和更高的回忆来检索结果。

通过主动查询从人类反馈中学习的强化
将大语言模型(LLM)与人类偏好保持一致,在建立现代生成模型中起着关键作用,可以通过从人类反馈(RLHF)学习来实现。尽管表现出色,但当前的RLHF方法通常需要大量的人类标记的偏好数据,这很昂贵。在本文中,受主动学习成功的启发,我们通过提出查询有效的RLHF方法来解决此问题。We first formalize the alignment problem as a contextual dueling bandit problem and design an active-query-based proximal policy optimization ( APPO ) algorithm with an e O ( d 2 / ∆) instance-dependent regret bound and an e O ( d 2 / ∆ 2 ) query complexity, where d is the dimension of feature space and ∆ is the sub-optimality gap over all the contexts.然后,我们提出了基于直接偏好优化(DPO)的算法的实用版本ADPO,并将其应用于微调LLMS。我们的实验表明,ADPO仅对人类偏好的查询进行了大约一半的查询,与最先进的DPO方法的性能相匹配。

量子计算在数据库查询优化中的适用性
我们评估了量子计算在两个基本查询优化问题(连接顺序优化和多查询优化 (MQO))上的适用性。我们分析了目前基于门的量子系统和量子退火器(两种目前市面上可用的架构)上可以解决的问题维度。首先,我们评估了基于门的系统在 MQO 上的使用情况,MQO 之前已通过量子退火解决。我们表明,与传统计算相反,不同的架构需要进行复杂的调整。此外,我们提出了一种用于连接顺序问题的多步骤重新表述,使其可以在当前量子系统上解决。最后,我们系统地评估了我们对基于门的量子系统和量子退火器的贡献。通过这样做,我们确定了当前局限性的范围,以及量子计算技术对数据库系统的未来潜力。