XiaoMi-AI文件搜索系统
World File Search System标识符

母体亚临床甲状腺功能减退症对后代神经发育的影响 - 基于动物的研究
可以通过观察花费的时间和计数开放臂的条目来衡量。与张开双臂相比,焦虑的动物往往会花更少的时间在张开的手臂上,并更频繁地进入闭合手臂。在本研究结束的本研究结束时(在PD 21处),通过升高的迷宫测试对这些标识符进行了研究,该标识符显示出类似焦虑的行为,其特征是在开放臂上花费的持续时间大大减少,表明母体SCH参与认知障碍的病原体。这些结果与一项研究表明,甲状腺功能减退动物在敞开的手臂中长时间停留时间(Navarro等,2015)。但是,我们的结果遵循对雄性和雌性猎犬大鼠进行的研究[15]。它表明,甲状腺功能减退症会影响两种性别的社会绩效和行为。可能是由于
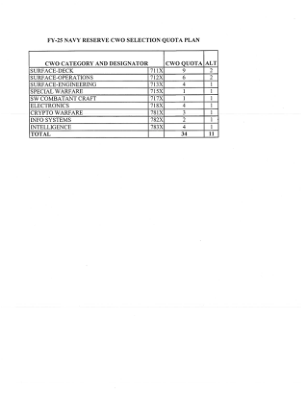
25 财年海军预备役军官选拔配额计划
2024 年 1 月 20 日 — FY-25 海军预备役 CWO 选拔配额计划。CWO 类别和标识符。CWO 配额 ALT。表面甲板。711X。9. 2. 表面作战。712X。


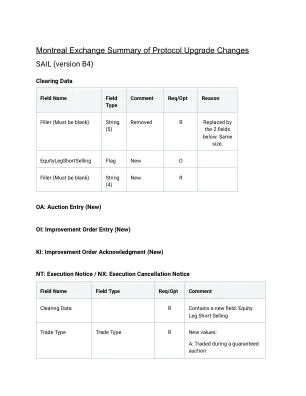

涉及司法系统 (JI) 的释放前服务(just inv)
每个 CF 都将通过组织国家提供商标识符 (NPI) 进行标识,该标识符可能是唯一的,也可能与同一组织内的其他设施共享。注册为嵌入式提供商的 CF 被归类为提供商类型免于许可诊所,并且必须将每个诊所注册为单独的站点。属于加州惩教和康复部 (CDCR) 的 CF 可以使用相同的 NPI 进行计费,并通过其实际位置进行标识。CDCR 监狱使用提供商类型 45。提供商应正确使用援助代码 I2-I6,如《提供商手册》第 1 部分中的援助代码:主图表部分所述。下文标题为“护理管理包”下的护理管理包五 (5) 不需要 JI 援助代码。

CRAM格式规范(版本3.1)
Data type Name Value byte method the block compression method (and first CRAM version): 0: raw (none)* 1: gzip 2: bzip2 (v2.0) 3: lzma (v3.0) 4: rans4x8 (v3.0) 5: rans4x16 (v3.1) 6: adaptive arithmetic coder (v3.1) 7: fqzcomp (v3.1) 8: name tokeniser (v3.1)字节块内容类型ID块内容类型标识符ITF8障碍物ID块,用于将外部数据块与数据系列ITF8大小相关联的块内容标识符在应用块数据中的大小为block compression inf inf bock inf8 iTf8 iTF8 iTF8原始大小中的大小在字节中*其他字段(标题块)字节[4] CRC32 CRC32 HASH值在块中的所有前字节

NAVSEAINST 2200.1A 便携式电子设备.pdf - Navy.mil
› 门户 › NAVINST PDF 2019 年 4 月 29 日 — 2019 年 4 月 29 日 (a) 如果在美国商业获得或通过美国军事交换获得。 (b) 如果分配了联邦通信委员会 (FCC) 标识符表示。

指导 - 普通人使用大型语言模型 -
8根据GDPR“处理”的第4(2)条,是指在个人数据或一组个人数据上执行的任何操作或一组操作,无论是通过自动手段,例如收集,记录,组织,结构,结构,存储,适应,适应,适应或变化,进行,进行,进行,咨询,咨询,咨询,通过传输,发放,分发或其他方式进行分配或委托,均可或委员会披露。9根据GDPR“个人数据”的第4(1)条,是指与已确定或可识别的自然人有关的任何信息(“数据主题”);可识别的自然人是一个可以直接或间接地识别的人,特别是通过参考标识符,诸如名称,标识号,位置数据,在线标识符或特定于物理,生理,遗传,心理,心理,经济,经济,经济,文化,文化,文化,文化,文化,经济,经济,经济,文化或社会身份的标识符。2016/679 2016/679欧洲议会和2016年4月27日的理事会关于对自然人的保护以及对个人数据的处理以及此类数据的自由流动以及废除指令95/46/EC的保护(一般数据保护法规);国家数据保护法也可能适用;法规(EU)2018/1725年的欧洲议会和2018年10月23日理事会关于自然人的保护,涉及联盟机构,机构,机构,办公室和机构以及此类数据的自由流动,以及废除45/2001和决策的欧洲数据(EC),欧洲第1147/2002/EC的自由运输(C) AI:数据保护的影响。

书籍搜索的生成检索
在书籍搜索中,应返回有关查询的相关书籍信息。书籍包含复杂的,多方面的信息,例如元数据,大纲和主要文本,其中大纲在章节和各节之间提供了层次的信息。生成检索(GR)是一种新的检索范式,将语料库信息固定到单个模型中,以生成与给定查询相关的文档标识符。如何将GR应用于书籍搜索?直接将GR应用于书籍搜索是一个挑战,因为书籍搜索的独特特征:(i)该模型需要保留该书的复杂,多面信息,从而增加了对标记数据的需求。(ii)将书籍信息分开并将其视为单独的学习部分的集合,可能会导致层次信息的丢失。我们为B OOK S EARCH(GBS)提出了一个有效的G能量检索框架,该框架具有两个主要组成部分:(i)数据元素和(ii)面向轮廓的书籍编码。为了进行数据增强,GBS构建了多个查询书对培训;它根据大纲,各种形式的书籍内容构建了多个书籍标识符,并模拟了带有多样化的伪Queries的真实书检索场景。这包括启动覆盖范围的书标识符的增强,允许该模型学会索引