XiaoMi-AI文件搜索系统
World File Search System检索服务

基于时间码的部分文件检索 2.0
Artico、Be Certain(和 Q 支架设计)、DLT、DXi、DXi Accent、DXi V1000、DXi V2000、DXi V4000、DXiV-Series、FlexTier、Lattus、Q 徽标、Q Quantum 徽标、Q-Cloud、Quantum(和 Q 支架设计)、Quantum 徽标、Quantum Be Certain(和 Q 支架设计)、Quantum Vision、Scalar、StorageCare、StorNext、SuperLoader、Symform、Symform 徽标(和设计)、vmPRO 和 Xcellis 是 Quantum Corporation 及其附属公司在美国和/或其他国家/地区的注册商标或商标。所有其他商标均为其各自所有者的财产。本文提及的产品仅用于识别目的,可能是其各自公司的注册商标或商标。所有其他品牌名称或商标均为其各自所有者的财产。Quantum 规格可能会发生变化。

查看账单状态并检索 RV
6. 成功登录后,您将进入此屏幕,从可用提供商 ID 中进行选择。注意:如果您在一个 OWCP Connect 登录下注册了多个提供商,或者您已作为用户添加到另一个提供商门户,则这些可用的提供商 ID 将在下拉菜单中可用。
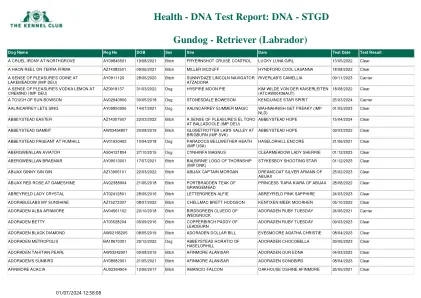
检索器(拉布拉多) - DNA测试报告
Allabs Lincolnshire Lass在Technicoat AX139501 18/03/2020 Bitch Technicoat Subur和Labil Party Party Party of Arihzans的时间20/09/2022 Clear
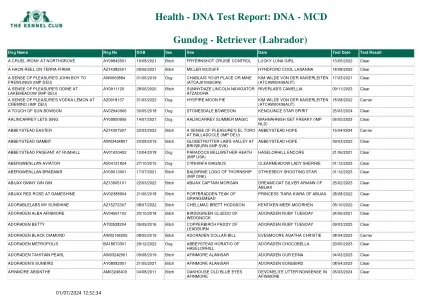
检索器(拉布拉多) - DNA测试报告
Allabs Lincolnshire Lass在Technicoat AX139501 18/03/2020 Bitch Technicoat Subur和Labil Party Party Party of Arihzans的时间20/09/2022 Clear

对话式人工智能——基于检索的聊天机器人
摘要 — 对话式人工智能可以简单地定义为通过自然对话进行的人机交互。这可以通过网站或任何社交消息应用程序上的聊天机器人、语音助手或任何其他支持交互式消息传递的界面来实现。该系统将允许人们提出疑问、获得意见或建议、执行所需的交易、寻求支持或通过对话以其他方式实现目标。聊天机器人基本上是使用自然语言的在线人机对话系统。目前,自然语言处理和机器学习机制的进步改进了聊天机器人技术。现在,越来越多的商业和社交媒体平台在其服务中使用这项技术。组织要求在聊天机器人的采用方面基于人工智能进行改进,因此它成为热门研究之一。在这项工作中,提出了一种基于任务的检索式聊天机器人,该机器人在公交车票预订领域使用深度神经网络构建。具有不同角色的多个用户提出的问题序列被作为系统的输入。因此,基于检索的系统会产生有意义的响应。生成的响应是手动评估的。结果表明,在大多数情况下,生成的答案都是有意义的。索引词——聊天机器人、基于检索的模型、神经网络、深度学习

使用相位检索单个球体的折射率...
图 6. 球体的加权噪声 LSP(SNR = 3)与模拟 LSP 的比较。后者的特性是通过谱法和非线性回归获得的,并在图例中呈现。谱方法的 MSE 和 log(MSE) 分别为 0.493 和 −0.307 ,而回归方法的 MSE 和 log(MSE) 分别为 0.198 和 −0.703 。
从高处的阴影中检索建筑物形状...
摘要 — 不连续的物体(例如建筑物)会在 SAR 图像中产生阴影。阴影是显著的特征,对图像理解大有帮助。由于城市地区建筑物密度高,阴影覆盖了图像的很大一部分,并为构建城市地图提供了重要提示。阴影的一个直接用途是根据阴影尺寸确定建筑物高度。我们在此提出另一种方法,当有高分辨率干涉图时,利用阴影来帮助检测建筑物本身。从具有非常高清晰度的振幅图像和相应的干涉图开始,我们将建筑物检测问题建模为能量最小化,其中考虑了建筑物与其阴影之间的相互作用。尽管噪声水平很高,但该方法可以获得出色的检测结果,尤其是对于高大或孤立的建筑物。


通过顺序学习过程列表以生成检索模型
最近,已经提出了一种新颖的生成检索(GR)范式,其中学会了单个序列到序列模型直接生成相关文档标识的列表(DOCID),给定查询。现有的GR模型通常采用最大似然估计(MLE)进行优化:这涉及给定输入查询的单个相关文档的可能性最大化,并假设每个文档的可能性独立于列表中的其他文档。我们将这些模型称为本文的重点方法。虽然在GR的上下文中已显示出侧面的方法是有效的,但由于其无视基本原则,即排名涉及对列表进行预测,因此被认为是次优的。在本文中,我们通过引入替代列表方法来解决此限制,该方法赋予GR模型以优化DOCID列表级别的相关性。从特定上讲,我们将排名copid列表的生成视为一个序列学习过程:在每个步骤中,我们学习了一个参数的子集,这些参数最大化了the DocID的相应生成可能性,给定(前面的)顶部 - 1个文档。为了形式化序列学习过程,我们为GR设计了位置条件概率。为了减轻梁搜索对推断期间发电质量的潜在影响,我们根据相关性等级对模型生成的文档的生成可能性执行相关性校准。我们对代表性的二进制和多层相关性数据集进行了广泛的实验。我们的经验结果表明,在检索性能方面,我们的方法优于最先进的基准。

通过公平检索增强>公平的人类一代
现有的文本到图像生成模型反映甚至扩大了其培训数据中根深蒂固的社会偏见。这对于人类图像发生尤其关注,其中模型与某些人口统计组有偏见。现有的纠正此问题的尝试受到预训练模型的固有局限性的阻碍,并且无法实质上改善人口多样性。在这项工作中,我们引入了公平检索增强生成(Fairrag),这是一个新颖的框架,该框架对从外部图像数据库中检索到的参考图像进行了预训练的生成模型,以改善人类发电机的公平性。Fairrag可以通过轻质线性模块进行调节,该模块将图像投入到Textual空间中。为了提高公平性,Fairrag应用了简单但有效的借鉴策略,在生成过程中提供了来自Di-Verse人群的图像。广泛的实验表明,Fairrag在人口统计学多样性,图像文本比对和图像保真度方面构成了现有方法,同时在推断过程中产生了最小的计算开销。