XiaoMi-AI文件搜索系统
World File Search System概述
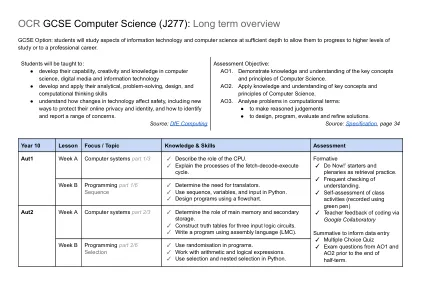
OCR GCSE计算机科学(J277):长期概述
●发展其计算机科学,数字媒体和信息技术方面的能力,创造力和知识●开发和应用其分析,解决问题,设计和计算思维能力●了解技术的变化如何影响安全,包括保护其在线隐私和身份的新方法,以及如何识别和报告范围的问题。

基于人工智能的电子学习:概述
近年来,科技的进步改变了人们学习和获取知识的方式。人工智能 (AI) 在教育领域的融入催生了一种新的学习形式,即基于人工智能的电子学习。基于人工智能的电子学习是一种创新的教育方法,利用人工智能技术为学生创造个性化的学习体验。它有可能通过为学生提供更具吸引力和更有效的学习体验来彻底改变教育[1]。人工智能在电子学习中的应用是一个特别新的研究领域,大多数研究集中在智能辅导系统的创建和使用上,其次是使用人工智能在电子学习环境中促进评估和评价。基于人工智能的电子学习是一种利用人工智能技术为学生创造个性化和互动式学习体验的电子学习。基于人工智能的电子学习的目标是使用人工智能算法分析学生行为并提供定制反馈以改善他们的学习体验 [3]。基于人工智能的电子学习可以通过各种平台进行,包括在线学习门户、移动应用程序和虚拟教室 [2]。基于人工智能的电子学习使用各种人工智能技术,包括自然语言处理、机器学习和计算机视觉,为学生创造个性化的学习体验。例如,人工智能算法可以分析学生的行为,例如花在特定主题上的时间,并提供定制反馈以帮助学生提高学习效果。此外,基于人工智能的电子学习系统还可以使用自然语言处理来了解学生的问题和需求并提供相关的答复。
大脑发育的概述
在开发的第28天之前,神经管已关闭,其主端末端已经形成了三个相互连接的腔室。这些腔室变成心室,围绕它们的组织成为大脑的三个主要部分:前脑,中脑,后脑。(FIF 3.5 a和3.5 c)随着发育的进展,the骨腔(前脑)分为三个单独的部分,它们成为两个侧心室和第三个心室。侧心室周围的区域变成了脑脑(末端大脑),第三个心室周围的区域变成了脑脑(脑)。(3.5 b和3.5 d)以最终形式,中脑内部的腔室(中脑)变窄,形成大脑渡槽,并在后部脑中形成两个结构:Metencephalon(Metercephalon(Afterbrain)和Myelencephalon(Marrowbrain)(Marrowbrain)(Marrowbrain)(Marrowbrain)(Marrowbrain)(Marrowbrain)(div 3.5 E)

afwerx Prime概述-public.pptx
方法和远程接近性操作:表征,方法,高级权力,动作获取:用于捕获,控制,对接,对接和关联的控制算法服务的机器人技术:提供寿命最终服务,任务扩展,轨道重置/DE-ORBIT/DE-ORBIT

人工智能药物研发、生物标志物开发和先进研发格局概述
本系列报告的主要目的是全面概述行业格局,包括药物发现、临床研究和制药研发其他方面采用人工智能的情况。本概述以信息丰富的思维导图和信息图表的形式突出趋势和见解,并对构成行业空间和关系的关键参与者的表现进行基准测试。这是一项概述分析,旨在帮助读者了解当今行业正在发生的事情,并可能让人们了解接下来会发生什么。自上一版以来,我们引入了大量更新,重点介绍了快速发展的行业动态,以及制药人工智能领域投资和业务发展活动的总体增长。人工智能生物技术公司、生物技术投资者和制药组织的名单已扩大到包括新实体,并增加了一份新的领先合同研究组织 (CRO) 名单,以概述合同研究行业对高级数据分析技术日益增长的兴趣。我们还重新审视了上一版的数据和章节,并反思了自那以后发生的变化。除了投资和商业趋势外,该报告还对人工智能应用和研究的一些最新成果提供了技术见解。


癌症免疫疗法早期临床开发相关生物标志物的统计方法概述
在过去十年中,出现了一种利用免疫系统对抗肿瘤的癌症治疗新模式。这些免疫疗法的新作用机制也给药物开发带来了新的挑战。生物标志物在免疫疗法早期临床开发的几个领域中发挥着关键作用,包括作用机制的证明、剂量确定和剂量优化、不良反应的缓解和预防以及患者丰富和适应症优先排序。我们讨论了在早期开发研究中建立一组生物标志物的预后、预测方面以及将生物标志物的变化与临床疗效联系起来的统计原理和方法。所讨论的方法旨在避免偏见并得出可靠且可重复的结论。本综述针对对免疫疗法背景下的生物标志物的战略使用和分析感兴趣的药物开发商和数据科学家。
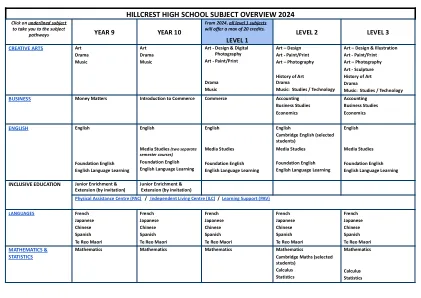

马里兰州的Maeoe介绍和环境/气候教育和识字概述
MAEOE EE认证计划是一项基于投资组合的认证计划,致力于改善正式和非正式环境教育者的培训和资源。全年接受申请,参与者最多可以收到3个MSDE CPD单位!

双子座应用的概述
双子座由Google功能最强大的AI模型提供动力,该模型具有不同的功能和用例。像当今大多数LLM一样,这些模型已预先培训,这些模型是从可公开可用来源的各种数据上进行的。我们使用启发式规则和基于模型的分类器将质量过滤器应用于所有数据集。我们还执行安全过滤,以删除可能产生政策侵略输出的内容。为了维持模型评估的完整性,我们在使用培训数据之前搜索并删除了培训语料库中可能曾经在我们的培训语料库中的所有评估数据。最终的数据混合物和权重是通过较小型号的消融来确定的。我们进行训练以改变训练期间的混合组合物 - 在训练结束时增加了与域相关的数据的重量。数据质量可能是高表现模型的重要因素,我们认为在寻找用于预训练的最佳数据集分布方面仍然存在许多有趣的问题。