
机构名称:
¥ 1.0
双子座由Google功能最强大的AI模型提供动力,该模型具有不同的功能和用例。像当今大多数LLM一样,这些模型已预先培训,这些模型是从可公开可用来源的各种数据上进行的。我们使用启发式规则和基于模型的分类器将质量过滤器应用于所有数据集。我们还执行安全过滤,以删除可能产生政策侵略输出的内容。为了维持模型评估的完整性,我们在使用培训数据之前搜索并删除了培训语料库中可能曾经在我们的培训语料库中的所有评估数据。最终的数据混合物和权重是通过较小型号的消融来确定的。我们进行训练以改变训练期间的混合组合物 - 在训练结束时增加了与域相关的数据的重量。数据质量可能是高表现模型的重要因素,我们认为在寻找用于预训练的最佳数据集分布方面仍然存在许多有趣的问题。
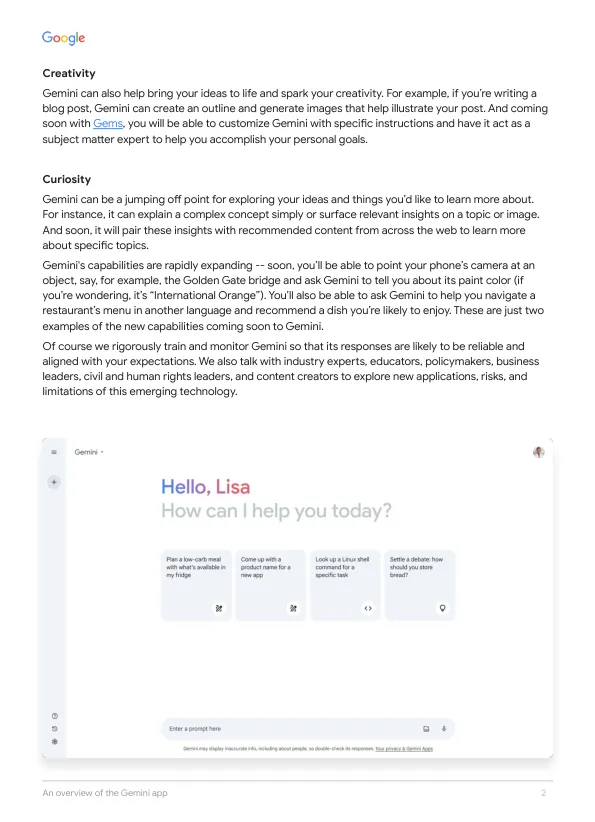
双子座应用的概述
主要关键词




相关文件推荐





























