XiaoMi-AI文件搜索系统
World File Search System歧视性

人工智能发展中的社会困境以及我们必须解决它的原因
AI 开发人员面临的困境。我们认为,当前 AI 开发中道德实践的方法未能解释开发人员在做正确的事情和保住工作之间做出选择的挑战。如果每个人都以某种方式行事,社会就会获得最佳结果,但实际实施这种行为会给个人带来不利影响,使他们无法做到这一点,这时就会出现社会困境。我们发现的问题是,当前的结构往往把拒绝不道德开发的负担放在开发人员的肩上,而由于他们的社会困境,他们不可能做到这一点。此外,这一挑战将变得越来越重要和普遍,因为人工智能正成为当前最具影响力的技术之一,对开发的需求巨大 [ 19 , 68 ]。人工智能领域的进步带来了数据分析和模式识别的空前进步,随后推动了该行业的进步。这一进步主要归功于机器学习,这是一种数据驱动的方法。在大多数情况下,所使用的数据都是历史数据,因此可以代表歧视性做法和不平等现象。因此,当前使用的许多机器学习模型巩固甚至加剧了现有的歧视性做法和不平等现象。此外,人工智能技术不必具有歧视性,其发展就是不道德的。基于面部识别、智能警务和安全城市系统的大规模监视已被多个国家使用 [ 29 ],社交媒体使用的新闻推送模型会创建回音室并助长极端主义 [ 24 ],自主武器系统正在生产中 [ 38 ]。

机场和空中导航服务提供商的经济监督
将反竞争行为或滥用市场支配地位的风险降至最低 确保收费应用的非歧视性和透明度 确保运力投资以具有成本效益的方式满足当前和未来的需求 保护乘客和其他最终用户的利益

尊重的工作场所政策
骚扰是令人反感的或不受欢迎的行为,评论,欺凌或应有的行动或应合理地知道的行为,将冒犯或羞辱另一个人,或不利地影响另一个人的健康和安全。这可以包括单一事件或一系列事件,这些事件本质上可以是歧视性的,也可以是非歧视性的,旨在恐吓,冒犯,退化或羞辱某个特定的人或群体。骚扰包括种族,宗教信仰,肤色,身体残疾,年龄,祖先,起源地,婚姻状况,收入来源,家庭状况,家庭状况,性别认同,性别认同,性别表达和性取向以及性良好或性良好或进步或性别验证或进步或进步或进步或进步,骚扰包括行为,评论,欺凌或行动。行为,评论,欺凌或行动无需故意构成骚扰,也不需要针对特定的个人或团体。MEG不容忍骚扰。

“当然AI区分”:识别交流...
本文主张在评估现实生活中AI设计,开发和部署的社会影响时,需要将反歧视性视为独特的视角。该论点基于对挪威公共部门约200个组织的调查以及19次深入的访谈,并提出了将“歧视”翻译为跨学科和话语环境中社会相关概念的挑战。本文在我们的研究中提出了对歧视风险的六个话语回应,以预示着专注于歧视如何使人们能够应对其他概念(例如偏见和隐私)无法解决的独特挑战。通过将歧视与其他辅助问题(例如偏见和隐私)区分开来,我们提出了我们对在实际实践和情况下对AI设计,开发和部署的批判性理解的必要性,并敦促AI开发人员积极采用反歧视性镜头,而在其实践中不替代临床概念,例如bias exprivation efformenty of topersipers of诸如bias或其他偏见,或其他相同的概念。
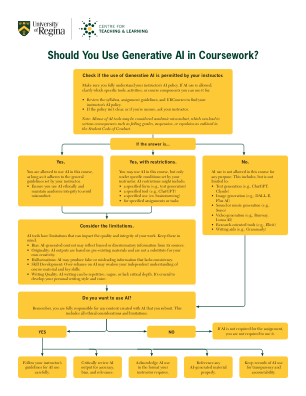
你应该在课程中使用生成式人工智能吗?
人工智能工具存在一些局限性,可能会影响您作品的质量和完整性。请记住以下几点:• 偏见:人工智能生成的内容可能反映其来源的偏见或歧视性信息。• 原创性:人工智能输出基于预先存在的材料,不能替代您的作品

我们的现代奴隶制和人口贩运声明
国际供应链管理有限公司致力于2015年《现代奴隶制法》的原则以及废除现代奴隶制和人口贩运的原则。作为雇主的同等机会,国际供应链管理有限公司致力于为其员工创建和确保非歧视性和尊重的工作环境。

董事会在评估和管理AI风险中的作用
复杂的公司,公司越来越多地面临声誉,财务和法律风险,从开发和部署不按预期运行或产生有问题结果的AI系统。潜在风险的范围很广,可以包括促进歧视性实践,导致产品失败并产生虚假,误导性或有害内容。

人工智能发展中的社会困境以及我们必须解决的原因
人工智能开发人员面临的困境。我们认为,当前人工智能开发中的道德实践方法未能解释开发人员在做正确的事情和保住工作之间做出选择的挑战。如果每个人都以某种方式行事,社会就会取得最佳结果,但实际实施这种行为会给个人带来不利影响,使他们无法做到这一点,这就存在社会困境。我们发现的问题是,当前的结构往往把拒绝不道德开发的负担放在开发人员的肩上,因为他们面临社会困境,不可能做到这一点。此外,这一挑战将变得越来越重要和普遍,因为人工智能正成为当前最具影响力的技术之一,对开发的需求巨大[19,68]。人工智能领域的进步导致了数据分析和模式识别的空前进步,随后该行业也取得了进展。这一进步主要归功于机器学习,这是一种数据驱动的方法。在大多数情况下,所使用的数据都是历史数据,因此可以反映出歧视性做法和不平等现象。因此,目前使用的许多机器学习模型巩固甚至加剧了现有的歧视性做法和不平等现象。此外,人工智能技术的发展即使不具有歧视性,也是不道德的。基于面部识别、智能警务和安全城市系统的大规模监控已被多个国家使用 [29],社交媒体使用的新闻推送模型会形成回音室效应并助长极端主义 [24],自主武器系统正在生产中 [38]。

极热对中国湖泊变暖的影响
背景:一种非侵入性子宫内膜癌检测工具,可以准确地有症状的女性进行定义测试,这将改善患者护理。尿液是一种吸引人的生物流体,用于癌症检测,因为它的简单性和易于收集性。这项研究的目的是确定可以区分子宫内膜癌患者与症状对照的基于尿液的蛋白质组学特征。方法:这是一个前瞻性案例 - 对症状的绝经后妇女的控制研究(50个癌症,54例对照)。无效的自我收集的尿液样品进行质谱法处理,并使用所有理论质谱(Swath-MS)的顺序窗口采集进行运行。机器学习技术用于识别重要的歧视性蛋白质,随后使用逻辑回归将其合并在多标记面板中。结果:用于子宫内膜癌症检测的最高歧视性蛋白单独表现出适度的准确性(AUC> 0.70)。但是,结合最歧视性蛋白的算法在AUC> 0.90中表现良好。表现最好的诊断模型是一个10标记的面板,将SPRR1B,CRNN,CALML3,TXN,FABP5,C1RL,MMP9,ECM1,S100A7和CFI结合在一起,并预测子宫内膜癌的AUC为0.92(0.96 - 0.96 - 0.97)。基于尿液的蛋白质特征显示出早期癌症检测的良好精度(AUC 0.92(0.86 - 0.9))。结论:一种患者友好的,基于尿液的测试可以在有症状的女性中提供非侵入性子宫内膜癌检测工具。有必要在较大的独立队列中进行验证。

《京畿道人工智能应用政策建议》
需要通过制定和使用非侵入性结果利用清单、禁止基于种族、性别、地域的偏见和歧视性的数据选择和使用、结果的验证和重新解释、数据水印技术的引入和应用等方式,打造安全可靠的人工智能利用环境。