XiaoMi-AI文件搜索系统
World File Search System注释的

经验研究文章写作中心电子邮件
从广泛的兴趣开始,然后将其范围缩小到特定主题。这个过程的流程图可能看起来像这样:诗歌EzraPound的诗歌EzraPound的诗歌翻译。下一步是确定您的主题是否可以研究:您是否有足够的时间进行研究?您是否与此主题有个人联系,这可能会阻碍您保持相对公正的能力?您对这个主题了解足够多,可以轻松地收集相关的学术文学?上面的兴趣流程图可以产生以下可研究的问题:以斯拉·庞德(Ezra Pound)的中国诗歌翻译是否准确?如果您对研究问题充满信心,请继续前进,并开始编译资源,您可能需要用于带注释的书目/文献评论。注释书目的注释参考书目(如果您的教授要求),找到六个来源 - 至少有三篇是同行评审的学术文章 - 与您的研究问题有关。总结文章,解决作者提出的论点,他们提供的有关您的主题的背景信息以及/或他们为支持或反对您的论点提供的证据。您注释的书目的布局将首先包括以MLA或APA格式对源的完整引用,然后在下面进行摘要。这是与研究问题有关的注释书目的一个示例:以埃兹拉·庞德(Ezra Pound)对中国诗歌的翻译是否准确?

议程/委员会报告运输和基础设施...
根据注释的《田纳西州法典》第8-44-112条,保留了公众评论该议程上出现的立法项目。希望发言的公众可能会在理事会委员会的注册表上注册,张贴在委员会计划开会的会议室外面。公众评论会议会议将在会议开始之前立即结束。公众意见在理事会委员会会议上总共限制为八分钟,每位发言人最多可允许两分钟发言。

设施流体指标和测试方法 - SMTnet
摘要:该技术转让由三角研究研究所 (RTI) 作为 SEMATECH 设施流体项目 (S100) 的一部分准备。它是有关现有设施流体度量和测试方法的信息汇编。有关标准方法的信息来自 SEMATECH 和 SEMI。其他信息来自对期刊和会议论文集的文献检索。已发布的信息主要涉及所使用的测试设备以及发现的检测和纯度水平。许多文章讨论了新设备的使用,无论是商业还是实验。报告附有大量带注释的参考书目。

协作视觉文本表示为开放式摄取分段(补充材料)优化
- 可可固定:可可固定是一个大规模的语义分割数据集,其中包含164k图像,带有171个带注释的类,分为训练集(118k映像),验证集(5K图像)和测试集(41K图像)。在我们的实验中,我们使用完整的118K训练集作为训练数据来训练语义模型。- 可可式式:可可式跨跨培训图像与可可固定相同的训练图像。这些图像被标记为133个类别。在我们的经验中,我们使用可可式式跨跨景模型。- Pascal-voc:Pascal-Voc包括1,449张图像,用于20个宣传类。在开放式语义语义分割中,所有20个类均用于评估(称为PAS-20)。- ADE20K:ADE20K是一个大规模的场景,理解数据集构成了2K图像,用于验证两种注释:一种具有150个类的班级,带有Panoptic注释,另一个带有847个课程的语义注释。对于开放式语义语义分割,我们在ADE20K的两个设置上评估了我们的方法:150个类(称为A-150)和847类(称为A-847)。在开放式综合综合分割中,我们使用带有150个类注释的设置进行评估。

用于分层 IC 图像分析的无监督域自适应与直方图门控图像转换
摘要 — 深度学习通过使用卷积神经网络 (CNN) 对电路结构进行分割,在具有挑战性的电路注释任务中取得了巨大成功。深度学习方法需要大量手动注释的训练数据才能获得良好的性能,如果将在给定数据集上训练的深度学习模型应用于不同的数据集,则可能会导致性能下降。这通常被称为电路注释的域转移问题,其源于不同图像数据集之间的分布可能存在很大差异。不同的图像数据集可以从不同的设备或单个设备内的不同层获得。为了解决域转移问题,我们提出了直方图门控图像转换 (HGIT),这是一种无监督域自适应框架,它将图像从给定的源数据集转换到目标数据集的域,并利用转换后的图像来训练分割网络。具体而言,我们的 HGIT 执行基于生成对抗网络 (GAN) 的图像转换并利用直方图统计数据进行数据管理。实验是在适应三个不同目标数据集(无训练标签)的单个标记源数据集上进行的,并评估了每个目标数据集的分割性能。我们已经证明,与已报道的域自适应技术相比,我们的方法实现了最佳性能,并且也相当接近完全监督的基准。索引术语——深度学习、集成电路图像分析、无监督域自适应、图像到图像转换

Ben Bartlett博士合成时间维度中的确定性光子量子计算:补充
图S1。 一个注释的图形,描绘了主文本中描述的结构以及物理和逻辑电路元素的对应关系。 (a)设备的物理设计,并带有指示物理电路元素实现的量子操作的注释。 (b)原子:ω1的能量结构与空腔模式和光子载体频率共鸣,而ω0却是遥不可及的。 (c)量子电路的栅极图通过散射单元的光子量子置轴的单个通过。 顶部轨道表示光子值的状态,而底部导轨表示原子量子。 光子返回存储环后,将r x(-θ)应用于原子量子,并进行原子态的射击测量。 最终输出状态| ψouted是zπS1。一个注释的图形,描绘了主文本中描述的结构以及物理和逻辑电路元素的对应关系。(a)设备的物理设计,并带有指示物理电路元素实现的量子操作的注释。(b)原子:ω1的能量结构与空腔模式和光子载体频率共鸣,而ω0却是遥不可及的。(c)量子电路的栅极图通过散射单元的光子量子置轴的单个通过。顶部轨道表示光子值的状态,而底部导轨表示原子量子。光子返回存储环后,将r x(-θ)应用于原子量子,并进行原子态的射击测量。最终输出状态| ψouted是zπ

利用在线相互知识提炼实现跨模态医学图像分割
深度卷积神经网络的成功部分归功于海量带注释的训练数据。然而在实践中,获取医疗数据注释通常非常昂贵且耗时。考虑到具有相同解剖结构的多模态数据在临床应用中广泛可用,在本文中,我们旨在利用从一种模态(又称辅助模态)学到的先验知识(例如形状先验)来提高另一种模态(又称目标模态)的分割性能,以弥补注释的稀缺性。为了缓解由模态特定外观差异引起的学习困难,我们首先提出一个图像对齐模块(IAM)来缩小辅助和目标模态数据之间的外观差距。然后,我们提出了一种新颖的相互知识蒸馏(MKD)方案,以充分利用模态共享知识来促进目标模态分割。具体来说,我们将我们的框架制定为两个独立分割器的集成。每个分割器不仅从相应的注释中显式提取一种模态知识,而且还以相互引导的方式从其对应部分中隐式探索另一种模态知识。两个分割器的集合将进一步整合来自两种模态的知识,并在目标模态上生成可靠的分割结果。在公共多类心脏分割数据(即 MM-WHS 2017)上的实验结果表明,我们的方法通过利用额外的 MRI 数据在 CT 分割方面取得了很大的改进,并且优于其他最先进的多模态学习方法。

一种深度学习的方法,以实现高效而准确的珊瑚...
摘要。珊瑚礁是重要的生态系统,由于当地人类的影响和气候变化,其威胁越来越大。对珊瑚礁的有效,准确的监测对于它们的保护和管理至关重要。在本文中,我们提出了一个自动珊瑚检测系统,该系统只能使用一次(YOLO)深度学习模型,该模型是专门针对水下进化分析量身定制的。要训练和评估我们的系统,我们采用了一个由400个原始水下图像组成的数据集。,我们使用数据增强技术通过图像操纵将带注释的图像的数量增加到580,这可以通过提供更多样化的训练示例来改善模型的性能。数据集是从捕获各种珊瑚礁环境,物种和照明条件的水下视频中仔细收集的。我们的系统可以实现Yolov5算法的实时对象检测功能,从而实现有效而准确的珊瑚检测。我们使用Yolov5从带注释的数据集中提取区分特征,从而使系统能够概括,包括以前看不见的水下图像。在我们的原始图像数据集上,使用Yolov5成功实施了自动珊瑚检测系统,突出了先进的计算机视觉技术在珊瑚礁研究和保护中的潜力。进一步的研究将着重于完善算法以处理具有挑战性的水下图像条件,并扩展数据集以结合更广泛的珊瑚种类和时空变化。
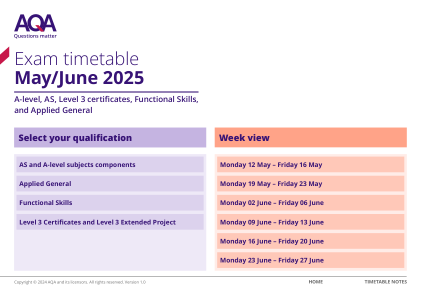
2025 年 5 月/6 月考试时间表
18. 参加 AS 和 A-level 数学、7356 和 7357 考试的学生需要小册子“A-level 数学公式”,但如果他们还参加高等数学,可能更喜欢使用“A-level 数学和 A-level 高等数学公式和统计表”。学生必须使用 AQA 提供的干净副本,而不是从网站打印的版本。学生不得将自己的带注释的副本带入考场。学校/学院应查看规范以获取有关学生在考试中所需材料的信息。文具可在考试前由考试官员订购。

可解释的 AI Holodeck 中的 CLIP 引导 3D 场景生成
简介文本到场景生成的一个主要挑战是生成多样化但又与用户输入保持相关的场景。 先前关于 3D 场景生成的工作主要集中于使用用户明确提到的对象或相关对象(而不考虑基础环境)的场景的可信度(Chang 等人,2015 年;Coyne 和 Sproat,2001 年)。 然而,虚拟场景也可以包含隐式对象(即通过常识与其他对象相关并从隐式场景知识中得出的对象(¨ Ohlschl¨ager 和 V˜o,2020))。 隐式对象可以通过特定于环境或特定于实例的知识收集,并且可以通过描绘多样化和人口密集的物理空间的真实感来提高生成场景的可信度。我们之前曾介绍过 AI Holodeck (Smith 等人,2021) 的初始阶段,这是一个使用通过带注释的数据集收集的环境特定知识从自然语言输入生成虚拟 3D 场景的应用程序。在本文中,我们介绍了 AI Holodeck 应用程序的新版本,它通过两个层次收集常识性知识。首先,如前一版本所示,带注释的图像数据集为系统提供了与用户明确定义的对象隐式相关的对象。其次,CLIP 引导 (Radford 等人,2021) 搜索从与用户输入相关的参考图像中提取对象及其空间关系。由于存在令人惊讶的隐式对象或其位置,这一添加也增加了我们系统对可解释性的需求。对于