XiaoMi-AI文件搜索系统
World File Search System用图
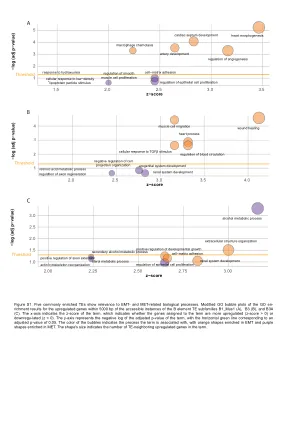
图S1
图S1。 五个通常富集的TE与EMT和MET相关的生物学过程相关。 在B1元素te subfamilies b1_mus1(a),b3(b)和b3a(c)的可访问实例的5000 bp内的GO富集结果的修改后的GO气泡图。 x轴表示该术语的z评分,该术语表明分配给该术语的基因是更上调的(z分数> 0)还是下降的(z <0)。 y轴表示该术语调整后的P值的负log,水平绿线对应于调整后的P值为0.05。 气泡的颜色表示该术语与之相关的过程,橙色形状富含EMT和紫色形状富含MET。 形状的大小指示了该术语中上调的基因的数量。图S1。五个通常富集的TE与EMT和MET相关的生物学过程相关。在B1元素te subfamilies b1_mus1(a),b3(b)和b3a(c)的可访问实例的5000 bp内的GO富集结果的修改后的GO气泡图。x轴表示该术语的z评分,该术语表明分配给该术语的基因是更上调的(z分数> 0)还是下降的(z <0)。y轴表示该术语调整后的P值的负log,水平绿线对应于调整后的P值为0.05。气泡的颜色表示该术语与之相关的过程,橙色形状富含EMT和紫色形状富含MET。形状的大小指示了该术语中上调的基因的数量。

量子图
量子图项目提议深入探索量子信息论核心的组合方面,它位于组合学和理论计算机科学与量子物理学的交叉点上。更具体地说,我们的项目旨在对量子图概念进行几项理论发展,量子图被视为图的非交换概括。这项跨学科的提案旨在开发新的组合和代数方法来解决量子信息中的基本问题,同时阐明组合结构和量子特性之间的深层关系。在量子信息论的框架内,量子图(也称为非交换图)的概念首次由 Duan 等人在 [DSW13] 中提出,目的是将香农理论中的某个概念推广到量子情况。与经典图可视为非自反对称关系这一事实类似,Weaver [Wea21] 将量子图表述为冯·诺依曼代数上的自反对称量子关系。Musto 等人 [MRV18] 还将有限量子图表述为有限量子集上的邻接运算符。非常令人惊讶的是,这三种不同的观点指向了同一个对象,即量子图,这是本博士项目的重点。

机器图
我向作者 P. Kannaiah 博士、K.L. 教授表示祝贺。S.V.U. 的 Narayana 和 K. Venkata Reddy 先生。蒂鲁帕蒂工程学院出版了这本关于“机械制图”的书。本书首先介绍了工程制图的基础知识,然后作者系统地介绍了机械制图。在我看来,这是一种极好的方法。这本书对机械工程专业文凭、学位和 AMIE 级别的学生来说都是一本宝贵的书。P. Kannaiah 博士拥有约二十五年的丰富教学经验,这些经验得到了充分利用,正确地反映了对该主题的处理和呈现。K.L. 教授机械工程教授 Narayana 和车间主管 K. Venkata Reddy 先生明智地联手,从他们丰富的经验中提供有用的插图,这一独特之处是本书的一大财富,其他书籍可能没有这样的机会。任何绘图书都必须遵循 BIS 标准。作者在这方面做得非常细致。此外,本书毫无遗漏地涵盖了印度各大学的教学大纲。学习绘图原理并将其应用于工业实践对任何学生来说都是必不可少的,本书是工程专业学生的宝贵指南。它也是工业设计和绘图部门的参考书。本书几乎是机械绘图的完整手册。本书是学生和专业人士学习计算机图形学的基础,计算机图形学是现代的必备课程。我相信工程专业的学生会发现这本书对他们非常有用。

二维材料范德华异质结光电探测器研究进展
图 3 掺杂调控 vdW 异质结理论研究典型成果( a )结构优化后的 C 、 N 空位及 B 、 C 、 P 、 S 原子掺杂 g-C 3 N 4 /WSe 2 异质结 的俯视图 [56] ;( b )图( a )中六种结构的能带结构图 [56] ;( c )掺杂的异质结模型图、本征 graphene/MoS 2 异质结的能带结 构及 F 掺杂 graphene/ MoS 2 异质结的能带结构 [57] ;( d ) Nb 掺杂 MoS 2 原子结构的俯视图和侧视图以及 MoS 2 和 Nb 掺杂

氮化镓高电子迁移率晶体管的物理失效分析技术研究进展
Figure 12.1540-MeV 209Bi ion irradiation 1.7 × 10 11 ions/cm 2 TEM images of AlGaN/GaN HEMT devices: (a) Gate region cross-section; (b) The orbital image of the heterojunction region shown in Figure (a); (c) The image shown in Figure (a) has a depth of approximately 500 nm; (d) Traces formed at the drain; (e) As shown in Figure (d), the trajectory appears at a depth of ap- proximately 500 nm [48] 图 12.1540-MeV 209Bi 离子辐照 1.7 × 10 11 ions/cm 2 的 AlGaN/GaN HEMT 器件的 TEM 图像: (a) 栅极区域截面; (b) 图 (a) 所示异质结区域轨道图 像; (c) 图 (a) 所示深度约 500 nm 图像; (d) 在漏极形成的痕迹; (e) 如图 (d) 所示,轨迹出现在深度约 500 nm 处 [48]

人工智能报告之机器学习Artificial Intelligence ...
图 2-2 GAN 发展脉络 ...................................................................................................................... 3