XiaoMi-AI文件搜索系统
World File Search System统计量

定量测定 - 验证和验证工具包
Westgard QC提供方法验证数据分析工具套件和在线配对数据计算器。4该计算器可以与方法比较的数据一起使用,以计算有关回归线,S Y/X)和相关系数的线性回归统计量(斜率,Y截距和标准偏差(R,Pearson产品矩相关系数); t检验统计(两种方法或偏置测量值之间的平均差异; SD差异,两种方法之间差异的标准偏差)。也可以用于提供“比较图”,该图显示了Y轴的测试方法结果与X轴上的比较方法结果,以及一个“差异图”,该图显示了测试对y轴的比较结果之间的差异与X轴上的比较方法。

单光子激光元的分辨率限制-CVF Open Access
单光子光检测和范围(LIDAR)系统通常配备一系列检测器,以提高空间分辨率和传感速度。但是,考虑到激光跨场横跨场景产生的固定量磁通量,当更多像素在单位空间中堆积时,每像素信号到噪声(SNR)将减小。这在传感器阵列的空间分辨率与每个像素的SNR之间的空间分辨率之间提出了基本的权衡。探索了这种基本限制的理论表征。通过得出光子竞争统计量并引入一系列新的近似技术,得出了时间延迟的最大样品估计器的平均平方误差(MSE)。理论预测与模拟和实际数据良好。

开发和验证综合疾病注册表工具
方法:我们进行了一项方法论研究,以通过两步过程(开发和判断)来检查以患者为中心的通信工具的内容有效性。四个NCD的集成NCD注册表工具包括主要的2部分,即第1部分包括一般特征,即有关报告设施详细信息,患者信息,患者病史的一般数据,包括NCD的行为风险因素,第2部分包括4个疾病模块,即年轻的糖尿病,中风,癌症和急性心脏事件以及随访。对于验证,在第一步,域的确定,采样(项目生成)和仪器形成,第二步,内容有效性比,内容有效性指数和修改的KAPPA统计量由专家小组进行。专家面板和项目影响分数的建议用于检查仪器的面部有效性。
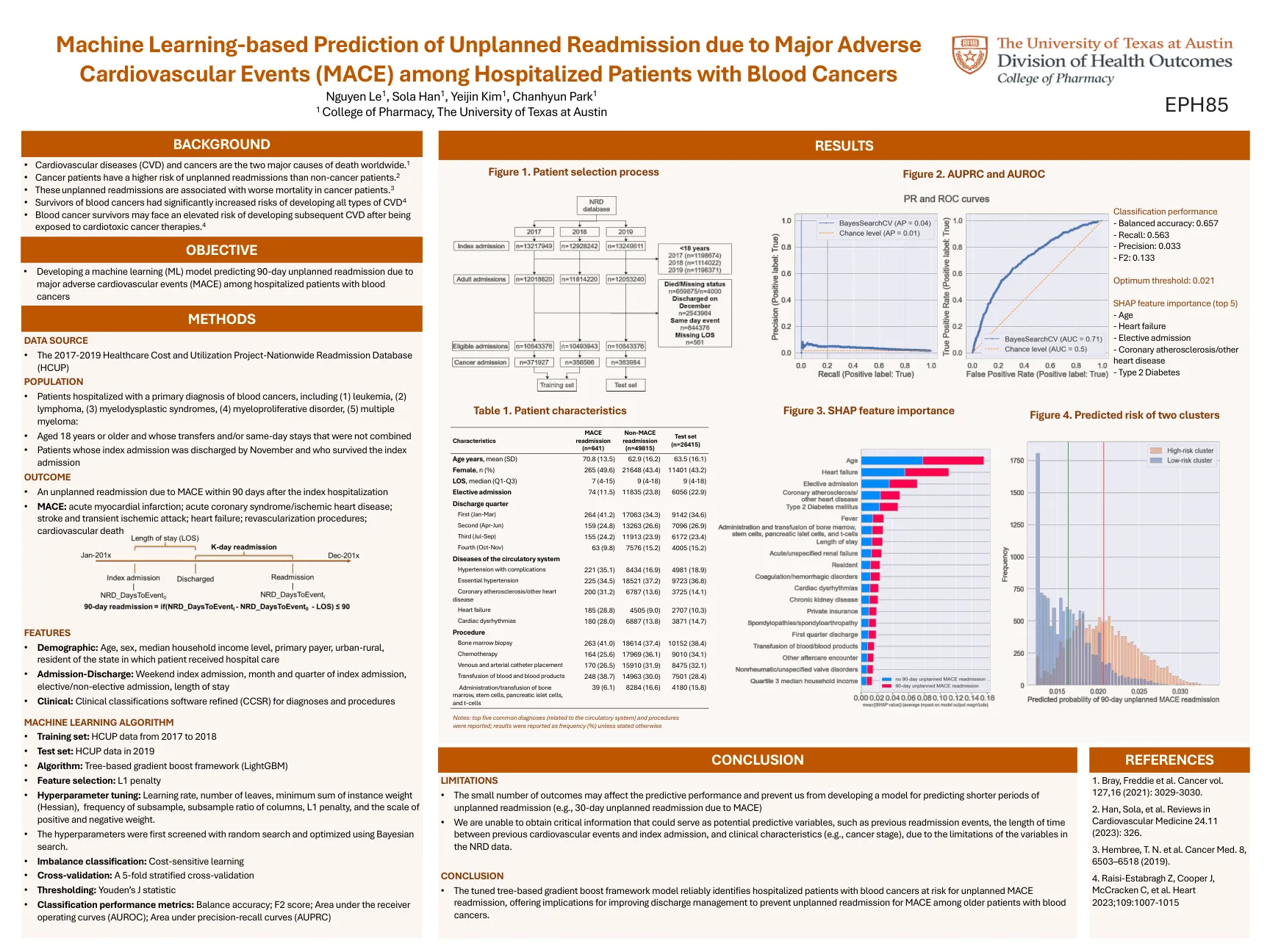
基于机器学习的预测未计划的重新入学,这是由于主要不利
MACHINE LEARNING ALGORITHM • Training set: HCUP data from 2017 to 2018 • Test set: HCUP data in 2019 • Algorithm: Tree-based gradient boost framework (LightGBM) • Feature selection: L1 penalty • Hyperparameter tuning: Learning rate, number of leaves, minimum sum of instance weight (Hessian), frequency of subsample, subsample ratio of columns, L1 penalty, and the scale of positive and negative weight.•首先对超参数进行筛选,并使用贝叶斯搜索进行优化。•不平衡分类:成本敏感的学习•交叉验证:5倍分层的交叉验证•阈值:Youden的J统计量•分类性能指标:平衡精度; F2分数;接收器操作曲线(AUROC)下方; Precision-Recall曲线(AUPRC)下的区域

理解回归,并在长期内以高频收集的观察结果 *
在本文中,我们通过长时间的时间间隔收集的观测值分析回归。对于形式的渐近分析,我们假设样品是从连续的时间随机过程中获得的,并让采样间隔δ缩小至零,样品跨度t增加到无穷大。在此设置中,我们表明,只要δ→0相对于t→∞,标准的WALD统计量向无穷大和回归偏差就会变得虚假。这种现象确实是本文中考虑的回归类型在实践中经常观察到的现象。相比之下,我们的渐近理论预测,如果我们使用适当的长期差异估计的WALD测试的强大版本,则伪造性消失。使用长期对短期利率的长期回归我们的经验说明,这得到了强烈和明确的支持。

定向搜索来自……的连续引力波
年轻的孤立中子星及其疑似位置是定向搜索连续引力波 (GWs) 的有希望的目标 [1]。即使没有从脉冲星的电磁观测中获得计时信息,这种搜索也可以以合理的计算成本实现有趣的灵敏度 [2]。包含候选非脉冲中子星的年轻超新星遗迹 (SNR) 是此类搜索的自然目标,即使在没有候选中子星的情况下,小型 SNR 或脉冲星风星云也是如此(只要 SNR 不是 Ia 型,即不会留下致密物体)。过去十年,已经发表了许多关于孤立、定位良好的中子星(除已知脉冲星外)的连续引力波的上限。它们使用的数据范围从初始 LIGO 运行到高级 LIGO 的第一次观测运行(O1)和第二次观测运行(O2)。大多数搜索都针对相对年轻的 SNR [3-11]。一些搜索瞄准了银河系中心等有希望的小区域 [4, 8, 11–13]。一项搜索瞄准了附近的球状星团,那里的多体相互作用可能会有效地使一颗老中子星恢复活力,从而产生连续的引力波 [14]。一些搜索使用了较短的相干时间和最初为随机引力波背景开发的快速、计算成本低的方法 [4, 8, 11]。大多数搜索速度较慢但灵敏度更高,使用较长的相干时间和基于匹配滤波和类似技术的针对连续波的专用方法。这里我们展示了对 12 个 SNR 的 O2 数据的首次搜索,使用完全相干的 F 统计量,该统计量是在代码流水线中实现的,该流水线源自首次发布的搜索 [3] 等 [5, 9] 中使用的代码流水线。由于 O2 噪声频谱并不比 O1 低很多,我们通过专注于与年轻脉冲星观测到的低频兼容的低频,加深了这些搜索(相对于 O1 搜索 [9])。这一重点使我们能够增加相干时间,并获得显着的改进

基于 PET/CT 的放射基因组学支持 KEAP1/NFE2L2 通路靶向治疗接受根治性放射治疗的非小细胞肺癌
对于肺癌患者,与手术相比,放射治疗会增加局部复发 (LR) 的风险,但毒性特征更佳。KEAP1/NFE2L2 突变状态 (Mut KEAP1/NFE2L2) 与接受放射治疗的患者的 LR 显着相关,但很少可用。使用非侵入性方式预测 Mut KEAP1/NFE2L2 有助于进一步个性化每种治疗策略。方法:基于 770 名患者的公共队列,首先使用连续基因表达水平开发模型 RNA (M-RNA) 来预测 Mut KEAP1/NFE2L2 ,从而得到二元输出。然后构建模型 PET/CT (M-PET/CT) 以使用 PET/CT 提取的放射组学特征来预测 M-RNA 二元输出。 M-PET/CT 在接受根治性容积调强弧形放射治疗的 151 名外部队列中得到了验证。每个模型都是使用多层感知器网络方法在单独的队列上构建、内部验证和评估的。结果:M-RNA 在测试队列中的 C 统计量为 0.82。在 101 名患者的训练队列中,保留的 M-PET/CT 的曲线下面积为 0.90(P,0.001)。将 20% 的概率阈值应用于测试队列后,M-PET/CT 的 C 统计量达到 0.7。由于患者根据 LR 风险显著分层,风险比为 2.61(P = 0.02),因此在容积调强弧形放射治疗队列中验证了相同的放射组学模型。结论:我们的方法可以使用 PET/CT 提取的放射组学特征预测 Mut KEAP1/NFE2L2,并有效地对接受放射治疗的外部队列中有 LR 风险的患者进行分类。

II. 驯化的基因组决定因素
t检验是一种用于分析某个种群与另外两个种群之间的差异的统计方法,是对简单Fst分析的改进。此类方法已在其他方面得到成功应用,例如,用于分析藏族相对于中国人和欧洲人对高海拔的适应性(Yi et al., 2010),以及用于分析玉米(Zea Mays L.)的驯化过程,将大刍草与两个栽培品种种群进行比较(da Fonseca et al., 2015)。另一方面,由于选择压力导致的偏离中性进化模型的基因组区域遗传多样性改变可通过Tajima的D统计量来测量(Nielsen, 2001; Tajima, 1989)。在这种情况下,正值可能同时表示平衡选择和基因渗入的影响,而负值通常被推断为驯化选择的迹象。

高性能确定性原位电子
摘要固态量子发射器在现实世界量子信息技术中的应用需要具有高过程产量的精确纳米制动平台。具有出色发射特性的自组装半导体量子点已被证明是满足许多新型量子光子设备需求的最佳候选者之一。然而,它们的空间和光谱位置在统计上以太大而无法通过固定光刻和灵活的处理方案进行整体统计量变化。我们通过基于精确且方便的阴极发光光谱进行了灵活和确定性的制造方案来解决这个严重的问题。本文介绍了该先进的原位电子束光刻的基础和应用示例。尽管我们在这里专注于作为光子发射器的量子点,但这种纳米技术概念非常适合基于基于量子发射器的各种量子纳米量设备的制造,这些量子发射器表现出适当的强大发光信号。

使用机器学习的新物理学的信号无关搜索的多次测试
摘要在这项工作中,我们解决了如何通过利用多个测试策略来增强信号无关搜索的问题。特别是我们考虑依靠机器学习的假设检验,其中模型选择可以引起对新物理信号的特定家庭的偏见。专注于新的物理学习机,这是一种进行信号不合命中率检验测试的方法,我们探索了多种多次测试的方法,例如组合P值和聚集的测试统计量。我们的发现表明,结合不同的测试,特征性的囊型玻璃参数是有益的,并且与最佳可用测试相当的表演是可以实现的,同时也可以提供对各种异常的响应更加均匀的响应。本研究提出了一种方法,该方法是有效的,该方法是在机器学习方法之外的方法,并且可以原则上应用于基于假设检验的较大类模型分析。