XiaoMi-AI文件搜索系统
World File Search System置信度

现实世界音乐对象识别
我们向当代光学识别(OMR)中最紧迫的两个问题提供了解决方案。我们提高了低质量,现实世界的识别准确性(即包含衰老,照明或污垢伪像)输入数据,并提供置信度评级的模型输出以实现有效的人类后处理。具体来说,我们提出了(i)复杂的输入增强方案,可以通过合成数据和现实世界文档的嘈杂扰动的结合来减少消毒基准和现实任务之间的差距; (ii)一种可用于改善OMR系统在低质量数据上的性能的对抗歧视域的适应方法; (iii)模型集合和预测融合的组合,该组合为每个预测产生值得信赖的置信度评级。我们在新创建的测试集上评估了我们的贡献,该测试集由来自国际音乐得分图书馆项目(IMSLP)/petrucci音乐库的手动注释的各种现实世界质量的页面组成。通过提出的数据增强方案,与最先进的培训相比,嘈杂的现实世界数据的检测性能从36.0%增加了一倍,达到73.3%。然后将此结果与强大的信心评级相结合,为OMR部署在现实世界中的道路铺平了道路。此外,我们还显示了无监督的对抗域适应的优点,以将36.0%的基线提高到48.9%。

信心和解释对人工智能辅助决策准确性和信任校准的影响
如今,人工智能越来越多地被用于帮助人类专家在高风险场景中做出决策。在这些场景中,完全自动化通常是不可取的,这不仅是因为结果的重要性,还因为人类专家可以利用他们的领域知识来补充模型,以确保任务成功。我们将这些场景称为人工智能辅助决策,其中人类和人工智能各自的优势共同优化联合决策结果。成功的关键在于根据具体情况适当校准人类对人工智能的信任;知道何时信任或不信任人工智能可以让人类专家适当地运用他们的知识,在模型可能表现不佳的情况下改善决策结果。本研究对人工智能辅助决策进行了案例研究,其中人类和人工智能单独具有可比的表现,并探索揭示特定案例模型信息的特征是否可以校准信任并提高人类和人工智能的联合表现。具体来说,我们研究显示特定预测的置信度得分和局部解释的影响。通过两项人类实验,我们表明,置信度得分可以帮助校准人们对人工智能模型的信任,但仅靠信任校准不足以改善人工智能辅助决策,这也可能取决于人类是否能够带来足够的独特知识来弥补人工智能的错误。我们还强调了在人工智能辅助决策场景中使用局部解释的问题,并邀请研究界探索新的可解释性方法,以校准人类对人工智能的信任。

第二卷 - 北卡罗来纳州气候研究所
在迄今为止使用的海面温度 (SST) 操作处理方法中,在卫星数据影响最小的地方,对 SST 反演算法(通过对卫星测量的辐射与现场观测进行直接回归而开发)的置信度最高,而在卫星数据潜力最大的地方,置信度最低。在卫星记录过程中,现场数据的密度和空间分布发生了显著变化。这些变化可能影响了不同卫星算法的准确性。气溶胶的影响,特别是埃尔奇琼火山 (1982) 和皮纳图博火山 (1991) 的大规模喷发,导致反演的 SST 出现显著偏差和趋势,远远超过了气候监测严格的 0.1 degK.decade -1 要求。虽然 AVHRR Oceans Pathfinder 等再处理工作已成功消除了实际卫星 SST 数据中存在的大部分偏差,但它们在许多领域仍未达到要求;例如,云消除。与从卫星辐射估计 SST 密切相关的两个问题是云检测和表面效应。在云检测中,使用预定阈值可能会影响检测/误报率,因为云状态的变化会影响空间和时间检索误差。更好的方法是将每个观测的确定性级别输入到分析步骤中,作为每个观测的误差极限描述的一部分。在这方面,云检测误差通常是非高斯和非对称的,需要修改分析方法才能产生最佳结果。表面效应(趋肤效应和

scipad:将空间线索纳入无监督的姿势深入关节学习
摘要 - 不监督的单眼深度估计框架 - 作品显示出有希望的自主驱动性能。但是,现有的解决方案主要依靠一个简单的召集神经网络来进行自我恢复,该网络努力在动态,复杂的现实世界情景下估算精确的相机姿势。这些不准确的相机姿势不可避免地会恶化光度重建,并误导了错误的监督信号的深度估计网络。在本文中,我们介绍了Scipad,这是一种新颖的方法,它结合了无监督的深度置式联合学习的空间线索。具体来说,提出了一种置信度特征流估计器来获取2D特征位置翻译及其相关的置信度。同时,我们引入了一个位置线索聚合器,该位置线索聚合器集成了pseudo 3D点云中的depthnet和2D特征流入均匀的位置表示。最后,提出了一个分层位置嵌入喷油器,以选择性地将空间线索注入到鲁棒摄像机姿势解码的语义特征中。广泛的实验和分析证明了与其他最新方法相比,我们的模型的出色性能。非常明显的是,Scipad的平均翻译误差降低了22.2%,而Kitti Odometry数据集的相机姿势估计任务的平均角误差为34.8%。我们的源代码可在mias.group/scipad上找到。

金融包容
注意:评估期涵盖2014年至2022年中期的财政年度。2022财政年度考虑了2021年12月31日批准的项目(或在2021年12月31日生效的MIGA项目)。as =咨询服务; ASA =咨询服务和分析; DPO =开发政策操作; IFC =国际金融公司; IPF =投资项目融资; IS =投资服务; MIGA =多边投资担保机构; mpweg =微型企业,贫困家庭,妇女和其他排除的群体; p4r =计划库。a。为了估计与DPO和其他多组分项目中金融包容相关的总数,项目的承诺金额是按比例分配的组件(例如,DPO的先前措施)。仅考虑与金融包容相关的组件。,如果组件具有多个子组件,则承诺的金额是按比例分配的,该子量与解决财务包容性的那些子集团分配。b。体积,反映了95%的置信度。采样框架将机构,工具,地区和国家收入水平视为地层。c。对于咨询项目,使用了支出价值。这些价值与与融资项目相关的vol umes不直接相提并论。d。独立评估小组使用关键字搜索来确定1,205个世界银行ASA项目可能与金融包容性有关。反映95%置信度的随机样本产生了43.8%的假阳性率。该数字用于从样本到人群的投影。

英吉利海峡和凯尔特海岩石的半自动测绘
摘要 本报告介绍了采用半自动化方法绘制海底基岩露头的结果。该方法由两个要素组成,即 1) 使用随机森林集成模型自动空间预测海底岩石的存在与否,以及 2) 根据辅助地质数据和专家知识手动编辑模型输出。该方法适用于 Charting Progress 2 区域 3(东海峡)和 4(西海峡和凯尔特海),但预计也适用于其他区域海域。自动预测是基于对岩石存在与否(响应变量)的观察以及各种预测变量,包括水深、水深的几种导数(坡度、粗糙度、水深位置指数等)、模拟流体动力学(深度平均潮流速度和峰值波轨道速度)和地质信息,例如基于基岩年龄和岩性的相对抗侵蚀性、沉积物流动性指标以及海床或海床附近硬质基质的存在。根据一组独立的测试数据评估了模型输出的准确性,准确性统计数据表明结果令人满意(总体准确性:83%)。目视检查确实发现某些地方存在错误分类,并相应地调整了模型输出。根据测深数据的类型(质量)、随机森林集合的模型一致性以及空间明确方式下的预测与观测之间的一致性,对已开发岩层的置信度进行了评估。在以系统方式进行手动编辑的情况下,对置信度分数进行了修改。最终输出显著改善了对英吉利海峡和凯尔特海海底基岩存在的表示。

地图集文档
搜索使用140 fb - 1在√𝑠= 13 = 13 TEV的proton-Proton碰撞中,搜索在辐射量激量激量仪中腐烂的中性长颗粒(LLP)。分析由三个通道组成。第一个目标配对生产的LLP,其中至少一个LLP的产生具有足够低的增强,以至于其衰减产物可以作为单独的喷气机解析。第二和第三通道的目标LLP分别与衰减衰变的𝑊或𝑍玻色子相关。在每个通道中,不同的搜索区域针对不同的运动学制度,以涵盖广泛的LLP质量假设和模型。没有观察到相对于背景预测的事件过多。higgs玻色子分支分支到成对的一对大于1%的强烈衰减中性LLP,在95%的置信度下排除在95%的置信度下,适当的衰减长度在30 cm至4.5 m的适当范围内,这取决于LLP质量,这取决于LLP质量,这是先前搜索的Hadronic Caloremeter搜索量的三个因素。与横截面高于0.1 pb的𝑍玻色子相关的长寿命深光子的产生被排除在20 cm至50 m的范围内的深色光子平均衰减长度,从而通过数量级提高了先前的Atlas结果。最后,Atlas首次对长期的光轴轴向粒子模型进行了探测,生产横截面高于0.1 Pb,在0.1 mm至10 m范围内排除了0.1 Pb。

聚谷氨酸疾病蛋白:相互作用曲线和病理效应的共同性和差异
图1 Polyq疾病蛋白的αFOLD结构。 (A) Predicted AlphaFold protein model of full-length ATXN1 (Human; AF-P54253), (B) ATXN2 (Human; AF-Q99700), (C) ATXN3 (Human; AF-P54252), (D) ATXN7 (Human; AF-O15265), (E) CACNA1A (Human; AF-O00555), (F) TBP(人类; AF-P20226),(G)AR(人类; AF-P10275)和(H)ATN1(Human; AF-P54259)。 (i)预测氨基酸残基1至413的Alphafold蛋白模型HTT(HTTQ21(1-414)),其中包含21个聚谷氨酰胺。 预测的HTTQ21(1-414)AlphaFold模型叠加在灰色(蛋白质数据库ID 6x9O,2.60Å分辨率[99]中显示的Cryo-EM确定的HTT-HAP40蛋白结构[99],其中未在Cryo-Em结构中确定PolyQ区域。图1 Polyq疾病蛋白的αFOLD结构。(A) Predicted AlphaFold protein model of full-length ATXN1 (Human; AF-P54253), (B) ATXN2 (Human; AF-Q99700), (C) ATXN3 (Human; AF-P54252), (D) ATXN7 (Human; AF-O15265), (E) CACNA1A (Human; AF-O00555), (F) TBP(人类; AF-P20226),(G)AR(人类; AF-P10275)和(H)ATN1(Human; AF-P54259)。(i)预测氨基酸残基1至413的Alphafold蛋白模型HTT(HTTQ21(1-414)),其中包含21个聚谷氨酰胺。预测的HTTQ21(1-414)AlphaFold模型叠加在灰色(蛋白质数据库ID 6x9O,2.60Å分辨率[99]中显示的Cryo-EM确定的HTT-HAP40蛋白结构[99],其中未在Cryo-Em结构中确定PolyQ区域。HTTQ21(1-414)模型高度对齐冷冻结构。由黑色矩形构建的残基代表野生型Polyq区域。比例尺表示源自AlphaFold预测的PLDDT值,并表示每日置信度度量[97]:PLDDT> 90,高精度; 90> plddt> 70建模良好; 70> PLDDT> 50低置信度; PLDDT <50差精度。ar,雄激素受体; ATN1,Atrophin 1; atxn1,ataxin 1; atxn2,ataxin 2; atxn3,ataxin 3; atxn7,ataxin 7; Cacna1a,钙电源门控通道亚基Alpha1 A(Cav2.1);冷冻电子,冷冻电子显微镜; HTT,亨廷顿; PLDDT,每个保留模型置信度评分; Polyq,聚谷氨酰胺; TBP,TATA结合蛋白。
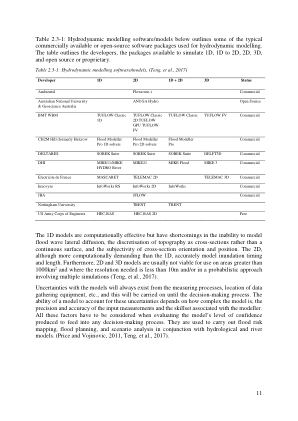
11 表 2.3-1:流体动力学建模软件/...
模型的不确定性始终存在,包括测量过程、数据收集设备的位置等,并且这种不确定性会一直持续到决策过程。模型考虑这些不确定性的能力取决于模型的复杂程度、输入测量的精度和准确性以及建模者的技能。在评估模型产生的置信度以用于任何决策过程时,必须考虑所有这些因素。它们用于与水文和河流模型结合进行洪水风险测绘、洪水规划和情景分析。(Price 和 Vojinovic,2011 年,Teng 等人,2017 年)。
植物植物激素的定性和定量代谢组学分析
分析结果表为操作员提供了一个简单的表,启用了交通灯审核系统 - 确定化合物时使用绿色复选框,黄色的含义要进行审查,红色表示没有匹配。预测的元素公式和silico在化学数据库中预测的片段化也可以通过将任何实验数据与理论信息匹配来实现更高水平的置信度。Sciex OS软件的分析部分中生成的结果表链接到原始数据文件,因此可以使用原始数据快速审查库的每个标识(图8)。