XiaoMi-AI文件搜索系统
World File Search System视觉模型

2025 WY/Co-TWS会议研讨会描述
描述:本研讨会的主要目的是向参与者介绍开源计算机视觉模型用于分析相机陷阱图像的应用。该研讨会旨在提供动手经验,以获取免费的云计算资源来部署和解释这些模型,以增强野生动植物监测和研究。虽然相机陷阱可以进行全面的野生动植物监测,但尽管此任务的耗时,许多研究人员仍会手动查看相机陷阱图像。存在几种开源模型来自动化这些任务,但是很难实施这些模型并验证其性能。Western Ecosystems,Inc。(West)的机器学习团队擅长开发和部署来自相机陷阱图像,无人机镜头和声学数据的动物和栖息地检测的计算机视觉模型。我们期待有机会分享我们的专业知识,并通过使用尖端的计算机视觉技术来帮助推进野生动植物监测的领域。一些编程经验将有所帮助。参与者应尽可能带上笔记本电脑。


Xuanlin (Simon) Li
◦我的主要研究兴趣包括(1)具有通用,开放世界(2D和3D)的感知和推理能力的建筑视觉模型和机器人模型,这些能力和推理能力可以有效地用于现实世界应用; (2)扩展培训数据,学习算法的学习算法和基准,以实现现实世界中可概括和可靠的机器人操作。

视觉模型的有效测试时间适应
通过预训练的视觉模型进行测试时间适应,引起了越来越多的关注,以应对测试时间的分离转移。尽管事先实现了非常有前途的性能,但它们会进行密集的计算,这与测试时间适应非常不规则。我们设计了TDA,这是一种无训练的动态适配器,可通过视觉模型进行有效,有效的测试时间适应。tda可与轻巧的键值缓存一起使用,该缓存维持具有很少射击伪标签的dy-namic队列作为值,而相应的测试样本特征则是键。杠杆键值缓存,TDA允许通过渐进式伪标签的细化逐渐调整数据,而逐步测试数据,而不会产生任何反向传播。此外,我们引入了负伪标记,即当模型不确定其伪标签预测时,通过将伪标签分配给某些负类时,可以减轻伪标签噪声的不利影响。在两个基准上进行的广泛实验表明,与最先进的艺术品相比,TDA的实体有效性和效率。该代码已在https://kdiaaa.github.io/tda/中发布。

杰克逊的简历2025
•领导了针对各种机器人任务的增强学习模型的开发,包括细胞显微镜和细胞转移,利用大规模,分布式机器学习系统和深度强化学习算法。•设计和实现的可扩展API可为机器学习模型提供数据,与云计算平台,云存储和大数据系统集成,以实现有效的数据处理和检索。•开发和部署了用于图像分割,对象分类和对象检测等任务的计算机视觉模型,以确保可靠和可扩展的解决方案。

外周血细胞图像分析的语言模型
摘要本文研究了视觉模型(VLM)在外周血细胞自动形态学分析中的应用。虽然手动显微镜分析仍然是血液学诊断的金标准,但它既耗时又可能会受到观察者间的变化。这项工作旨在开发和评估能够从微观图像中对血细胞进行准确的形态描述的微调VLM。我们的方法论包括三个主要阶段:首先,我们创建了一个合成数据集,该数据集由10,000个外周血细胞图像与专家制作的形态描述配对。第二,我们在三个开源VLMS上使用低级适应性(LORA)和量化Lora(Qlora)进行了微调方法:Llama 3.2,Qwen和Smovlm。最后,我们开发了一个基于Web的界面,用于实用部署。的结果表明,在预先调整后所有模型的所有模型中都有显着改善,QWEN的性能最高(BLEU:0.22,Rouge-1:0.55,Bertscore F1:0.89)。为了确保可访问性并实现正在进行的评估,该模型已被部署为网络空间的Web应用程序,使研究社区可自由使用。我们得出的结论是,微调的VLM可以有效地分析外周血细胞形态,从而为血液学分析提供了标准化的潜力。这项工作建立了一个框架,可以将视觉模型改编为专业的医疗成像任务,这对改善临床环境中的诊断工作流程的影响。完整的实现可在GitHub

Weijian Xu
加利福尼亚大学加利福尼亚大学拉霍亚大学,加利福尼亚州,2017年至2022年研究生研究助理,顾问:Zhuowen Tu-教授 - 专注于视觉代表性学习,并将其应用于广泛的应用程序。 - 探索了视觉模型中的变压器,重点是任务解码器和骨干设计。 相关作品被CVPR 2021和ICCV 2021接受。 - 开发了一个注意事项分类的注意星座模型。 这项工作被ICLR 2021接受。 - 开发了一种几何感知的骨骼检测方法,具有加权的Hausdor距离和几何加权的跨透明镜损失。 这项工作被BMVC 2019接受。加利福尼亚大学加利福尼亚大学拉霍亚大学,加利福尼亚州,2017年至2022年研究生研究助理,顾问:Zhuowen Tu-教授 - 专注于视觉代表性学习,并将其应用于广泛的应用程序。- 探索了视觉模型中的变压器,重点是任务解码器和骨干设计。相关作品被CVPR 2021和ICCV 2021接受。- 开发了一个注意事项分类的注意星座模型。这项工作被ICLR 2021接受。- 开发了一种几何感知的骨骼检测方法,具有加权的Hausdor距离和几何加权的跨透明镜损失。这项工作被BMVC 2019接受。

混合储能系统的进步
域的概括(DG)旨在解决源和目标域之间的分布变化,而Cur-Currand DG方法默认是从源和目标域共享相同类别的数据的设置。nev-但是,在实际情况下,从目标域中存在看不见的类。为了解决此问题,已经出现了开放式域概括(OSDG),并且已经完全提出了几种方法。但是,与DG方法相比,大多数措施的方法采用了具有略有改进的复杂体系结构。最近,在通过微调范式的DG中引入了视觉模型(VLM),但用大型视力模型消耗了大型的训练开销。因此,在本文中,我们创新了知识从VLMS转移到轻质视觉模型,并通过从三种表达式(包括得分,类别和实例(SCI)(SCI)的三种观点引入扰动蒸馏(PD)来提高鲁棒性,称为SCI-PD。此外,以前的方法是由具有相同和固定拆分的基准定向的,忽略了源域之间的局限性。这些方法可以通过我们提出的新的基准混合域概括(HDG)和一种新型的度量H 2 -CV造成急剧性能的衰减,它们构建了var-ous拆卸以全面评估算法的鲁棒性。广泛的实验表明,我们的方法在多PLE数据集上优于最先进的算法,尤其是在数据稀缺时提高了鲁棒性。1。简介

茶菜:生成长纪录片的预告片
关键字:预告片,多模式学习,视觉语言模型摘要:预告片是促进娱乐,商业和教育领域内容的有效工具。但是,为长视频创建有效的预告片是具有挑战性的,因为它需要为输入视频进行远程多模式建模能力,同时需要维护视听式的一致性,管理场景过渡并保留输出茶筒的事实准确性。由于缺乏公共可用的数据集,沿这项研究方向的进展受到了阻碍。在这项工作中,我们介绍了DocormaryNet,这是1,269家纪录片与他们的预告片配对的集合,其中包含视频,语音,音乐,声音效果和叙述的多模式数据流。使用DocordaryNet,我们提出了一个新的两阶段系统,用于从长纪录片中生成预告片。提出的曲植物系统首先使用预算的大语言模型从纪录片中抄录的叙述中生成预告片,然后选择最相关的视觉内容,以通过语言视觉模型伴随生成的叙述。对于叙述 - 视频匹配,我们探索了两种方法:一种基于预训练的模型,使用鉴定性的对比性语言视觉模型和一个深层的顺序模型,该模型了解叙述和视觉效果之间的映射。我们的实验结果表明,基于训练的方法比直接训练的深度自回归模型更有效地识别相关的视觉内容。
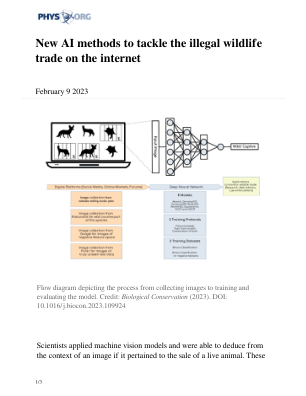
新的 AI 方法可打击互联网上的非法野生动物贸易
“这是首次应用机器视觉模型来推断图像背景,以识别活体动物的销售。当卖家宣传出售动物时,广告中通常会附上动物被圈养的图像。这不同于非圈养图像,例如游客在国家公园拍摄的动物照片。使用一种称为特征可视化的技术,我们证明了我们的模型可以同时考虑图像中动物的存在以及图像中动物的周围环境。因此,可以标记可能非法出售动物的帖子,”这项研究的主要作者 Ritwik Kulkarni 博士说。